
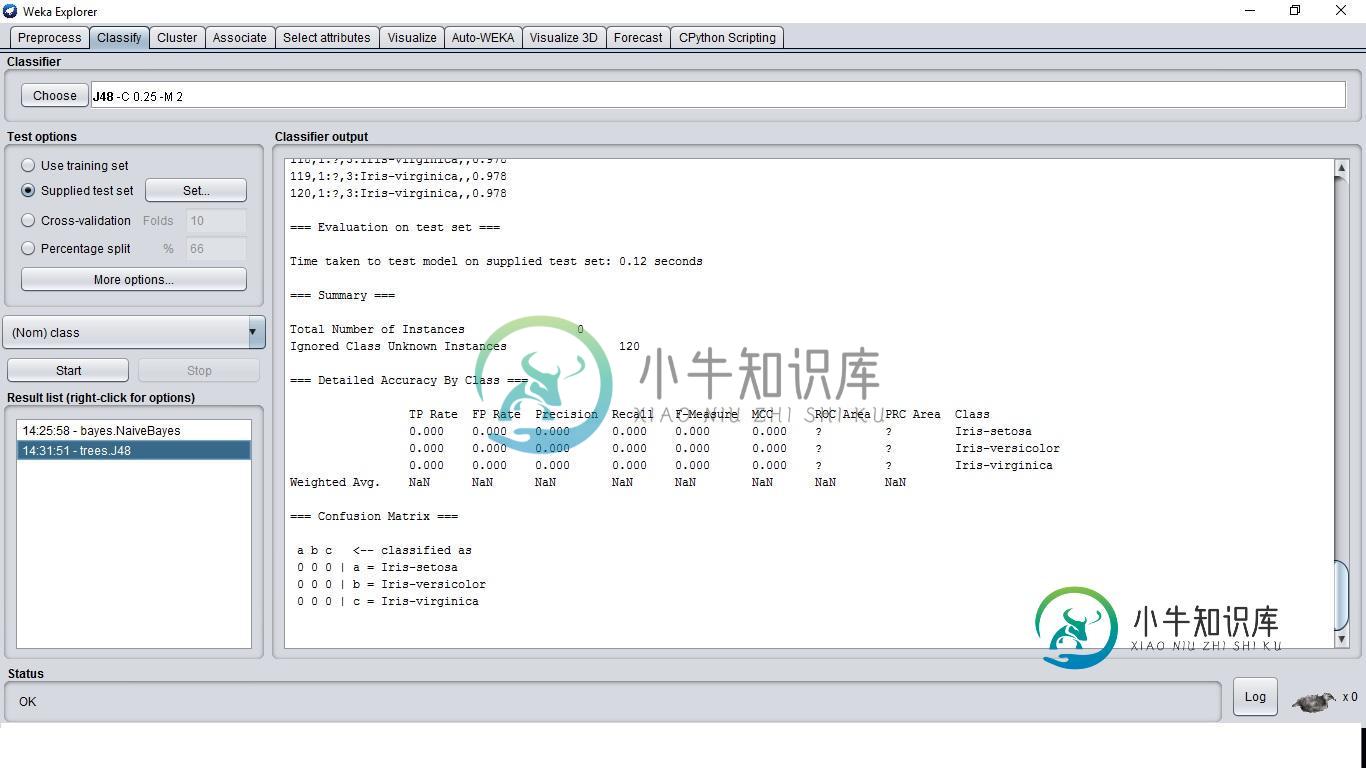
Weka中带有测试数据的空混淆矩阵

共有1个答案

混淆矩阵通过将测试集中实例的实际类与分类器预测的类进行比较,显示经过训练的分类器的性能。但是您提供的测试集没有类信息,因此没有什么可比较的。这就是为什么你看到
Total Number of Instances 0
Ignored Class Unknown Instances 120
在屏幕截图的输出中。
通常,您会首先使用交叉验证或具有类信息的测试集来评估分类器的性能。然后,您可以使用经过训练的分类器对未知数据进行分类,例如使用帮助中所述的在当前测试集上重新评估模型。
-
如何分析Weka中的混淆矩阵,以获得准确度?我们知道,由于数据集不平衡,精度不准确。混淆矩阵如何“确认”准确性? 示例:a)准确率96.1728% b) 准确率:96.8% 等...
-
我想在weka中进行分类。我正在使用一些方法(随机树、随机森林、决策表、随机子空间...),但它们会给出如下结果。 然而,我希望结果作为准确度和混淆矩阵。我怎样才能得到这样的结果? 注意:当我使用小数据集时,它会以混淆矩阵的形式给出结果。它可以与数据集的大小相关吗?
-
对不起,我是新来WEKA,刚刚学习。 在我的决策树(J48)分类器输出中,有一个混淆矩阵: 我如何读取这个矩阵?
-
我对数据挖掘并不陌生,所以我完全被WEKA结果难倒了。希望得到一些帮助。提前谢谢! 我有一个具有二分类(S, H)的数值向量数据集。我在省略交叉验证中训练了一个朴素贝叶斯模型(尽管方法真的无关紧要)。结果如下: 如您所见,输出和混淆矩阵都有三个错误。然后,我使用具有相同属性和相同两个类的独立数据集重新评估模型。结果如下: 这就是我的问题所在。输出清楚地显示有很多错误。事实上,有44个。另一方面,混
-
我正在对实际数据和来自分类器的预测数据进行多标签分类。实际数据包括三类(c1、c2和c3),同样,预测数据也包括三类(c1、c2和c3)。数据如下 在多标签分类中,文档可能属于多个类别。在上述数据中,1表示文档属于特定类,0表示文档不属于特定类。 第一行Actual\u数据表示文档属于c1类和c2类,不属于c3类。类似地,第一行predicted\u数据表示文档属于类别c1、c2和c3。 最初我使
-
我一直在使用Weka的J48决策树将RSS提要中的关键字频率分类为目标类别。我想我可能在协调生成的决策树与报告的正确分类的实例数以及混淆矩阵中的实例数方面存在问题。 例如,我的一个. arff文件包含以下数据摘录: 以此类推:总共有64个关键字(列)和570行,其中每一行都包含一天提要中关键字的频率。在这种情况下,10天内有57条feed,总共有570条记录需要分类。每个关键字都以代理项编号作为前