
将itext替换为pdfbox性能

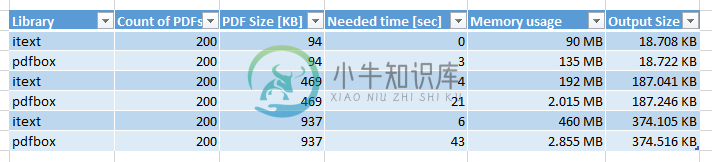
我正在评估将我们的pdf处理从itext替换为pdfbox。我用200个单页pdf(94KB、469KB、937KB)做了一些测试,并将它们合并到我们应用程序中的一个pdf中。PDFBox版本:2.0.23。itextversion:2.1.7。以下是测试结果:
这是itext实现:
byte[] l_PDFPage = null;
PdfReader l_PDFReader = null;
PdfCopy l_Copier = null;
Document l_PDFDocument = null;
OutputStream l_Stream = new FileOutputStream(m_File);
// do it for all pages in the editor
for( int i = 0; i < m_Editor.getCountOfElements(); i++ ) {
l_Page = m_Editor.getPageAt(i);
l_PDFPage = l_Page.getAsPdf();
l_PDFReader = new PdfReader(l_PDFPage);
l_PDFReader.getPageN(1).put(PdfName.ROTATE, new PdfNumber(l_PDFReader.getPageRotation(1) + l_Page.getRotation() % 360));
l_PDFReader.consolidateNamedDestinations();
if( i == 0 ) {
l_PDFDocument = new Document(l_PDFReader.getPageSizeWithRotation(1));
l_Copier = new PdfCopy(l_PDFDocument, l_Stream);
l_PDFDocument.open();
}
l_Copier.addPage(l_Copier.getImportedPage(l_PDFReader, 1));
if( l_PDFReader.getAcroForm() != null )
l_Copier.copyAcroForm(l_PDFReader);
l_Copier.flush();
l_Copier.freeReader(l_PDFReader);
}
l_PDFDocument.close();
l_Stream.close();
这是pdfbox实现:
byte[] l_PDFPage = null;
List<PDDocument> pageDocuments = new ArrayList<>();
PDDocument saveDocument = new PDDocument();
try {
// do it for all pages in the editor
for( int i = 0; i < m_Editor.getCountOfElements(); i++ ) {
// our wrapper object for a page
l_Page = m_Editor.getPageAt(i);
// page as byte[]
l_PDFPage = l_Page.getAsPdf();
PDDocument document = PDDocument.load(l_PDFPage);
// save page document to close it later
pageDocuments.add(document);
PDPage page = document.getPage(0);
saveDocument.addPage(saveDocument.importPage(page));
}
saveDocument.save(l_Stream);
}
finally {
// close every page document
for(PDDocument doc : pageDocuments) {
doc.close();
}
saveDocument.close();
}
我也尝试过使用pdfbox的pdfmerger。性能几乎与其他pdfbox实现相同。但对于937KB的文件,我在这个实现中遇到了outofmemory异常:
byte[] l_PDFPage = null;
OutputStream l_Stream = new FileOutputStream(m_File);
PDFMergerUtility merger = new PDFMergerUtility();
// do it for all pages in the editor
for( int i = 0; i < m_Editor.getCountOfElements(); i++ ) {
l_Page = m_Editor.getPageAt(i);
// page as byte[]
l_PDFPage = l_Page.getAsPdf();
merger.addSource(new ByteArrayInputStream(l_PDFPage));
}
merger.setDestinationStream(l_Stream);
merger.mergeDocuments(null);
所以我的问题是:
- 为什么pdfbox的性能(所需的时间和内存使用)与itext相比如此糟糕
共有1个答案

PDFBox和iText在体系结构上不同,因此对于不同的任务,它们的性能也不同。
特别是iText尝试提前写出新内容,在您的情况下,大部分页面已写入输出
l_Copier.addPage(l_Copier.getImportedPage(l_PDFReader, 1));
和
l_PDFDocument.close();
最终只完成PDF并写入最后剩下的对象和文件尾。
另一方面,PDFBox最终会立即保存所有内容:
saveDocument.save(l_Stream);
iText方法的优点是内存占用较小(正如您所观察到的),缺点是一旦写入页面,就无法更改其数据。
(顺便说一句:iText架构已经从iText 5更改为iText 7,在iText 7中您可以选择并可以将所有内容保存在内存中,但这里的价格也是一个很大的内存占用。)
因此,
为什么pdfbox的性能(所需的时间和内存使用量)与ittext相比如此糟糕?
上面可以部分解释内存使用的差异。同样在iText中
l_Copier.freeReader(l_PDFReader);
PdfReader可以关闭(由垃圾收集来为您完成)以释放其资源,而在PDFBox代码中,您可以保持所有源文档处于打开状态,将资源保留到最后。(事实上,我假设当您使用importPage时,不需要保留它们。)
关于时间,我现在还不确定。您应该进行更精细的计时,并确定在PDFBox中使用额外时间的确切位置;因此,我支持@Tilman对分析数据的请求。我想是在最后的扑救中,但这只是一种预感。此外,这种时间差异可能取决于所讨论的PDF的结构细节,对于其他文档可能不太极端。
-
问题内容: 所以我似乎无法弄清楚…我有一句话要说,我希望它成为。我已经尝试了以下所有方法,但似乎都没有效果; 我真的不明白为什么最后一个有效,因为这样可以正常工作: 我在这里想念什么吗? 编辑 我知道\是转义字符。我要在这里执行的操作是将所有内容都 转换为其他内容, 并且替换似乎没有按照我的预期进行。 我希望字符串a看起来像字符串b。但是替换并不能像我想的那样替换斜线。 问题答案: 无需为此使用r
-
问题内容: 我正在用Python解析文件中的文本。我必须替换所有换行符(\ n), 因为此文本将生成html-content。例如,这是文件中的一些行: 现在我做: 而且我仍然看到带有换行符的文本。 问题答案: 只是踢,你也可以 用替换字符串中的所有换行符。
-
我正在测试以下页面中的示例代码:https://svn.apache.org/viewvc/pdfbox/trunk/examples/src/main/java/org/apache/pdfbox/examples/signature/ 但是在文件createsignaturebase.java中,在函数和中,它调用了一个不再存在的属性:。我仔细阅读了Pdfbox页面和它的迁移指南,它没有提到这
-
我已经用iText创建了一个文档,我想把这个文档(保存为PDF文件)转换成一个图像。为此,我使用PDFBox,它需要一个PDDocument作为输入。我使用以下代码: 此时,我从已保存的文件中加载文档。但我希望在Java内部执行此操作。 所以我的问题是:如何将文档转换为PDDocument? 非常感谢任何帮助!
-
我得到了一个导入的文本块,但格式并不总是那么完美。之后我会尝试用jquery解决这个问题。所以我开始用 替换 : null null 但替换不起作用。最终的html应该如下所示:
-
我想用iText将带有图像的html文件转换成pdf格式。我在这里提供我的消息来源。 请帮助我如何使用iText将带有图像的html文件转换为pdf格式。如果没有图像或者硬编码图像路径,我可以转换html文件。提前致谢