
R2DBC TransientDataAccessResourceException:Id为[…]的行不存在

我的要求是这样的
{
"title" : "Star Wars: The Rise Of Skywalker",
"description": "In the riveting conclusion of the landmark Skywalker saga, new legends will be born-and the final battle for freedom is yet to come.",
"releaseYear": "2019",
"language": "English",
"rentalDuration": 7,
"rentalRate": "4.99",
"length": 165,
"replacementCost": "14.99",
"rating": "PG",
"specialFeaturesList": [ "SciFi", "Star Wars"],
"filmCategory": "Sci-Fi",
"actors":[
{
"firstName":"Daisy",
"lastName": "Ridley"
},
{
"firstName":"Carrie",
"lastName":"Fisher"
},
{
"firstName": "Oscar",
"lastName": "Isaac"
},
{
"firstName": "Adam",
"lastName": "Driver"
},
{
"firstName": "Mark",
"lastName": "Hamill"
},
{
"firstName": "John",
"lastName": "Boyega"
}
]
}
下面是我的逻辑和代码
/**
* Logic :
* Transaction start
* -- find Language or insert
* -- find Flim by (Title,release year and languageId) or insert
* -- foreach( actor)
* ---- find or create actor
* ---- find or create film_actor ( film id, actor)
* -- end
* -- for category
* ---- find category or insert
* ---- find film_category or insert
* -- end
* -- Map data
* Transaction end
*
* @param filmRequest
* @return Mono<Pair < Boolean, FilmModel>>
*/
代码:
@Override
public Mono<Pair<Boolean, FilmModel>> create(FilmRequest filmRequest) {
return Mono.just(filmRequest)
.flatMap(this::getOrCreateLanguage)
.flatMap(languageInput -> getOrCreateFilm(filmRequest, languageInput.getLanguageId()))
.flatMap(filmInput ->
Mono.zip(Mono.just(filmInput),
Flux.fromIterable(filmRequest.getActors())
.flatMap(this::getOrCreateActor)
.doOnNext(actorInput -> getOrCreateFilmActor(filmInput.getSecond().getFilmId(), actorInput.getActorId()))
.collectList(),
Mono.just(filmRequest.getFilmCategory())
.flatMap(this::getOrCreateCategory)
.flatMap(category -> getOrCreateFilmCategory(filmInput.getSecond().getFilmId(), category.getCategoryId()))
))
.map(tuple -> {
FilmModel filmModel = GenericMapper.INSTANCE.filmToFilmModel(tuple.getT1().getSecond());
List<ActorModel> actorModelList = tuple.getT2().stream().map(GenericMapper.INSTANCE::actorToActorModel).collect(Collectors.toList());
filmModel.setActors(actorModelList);
return Pair.of(tuple.getT1().getFirst(), filmModel);
}).as(operator::transactional);
}
这就是我的失败:
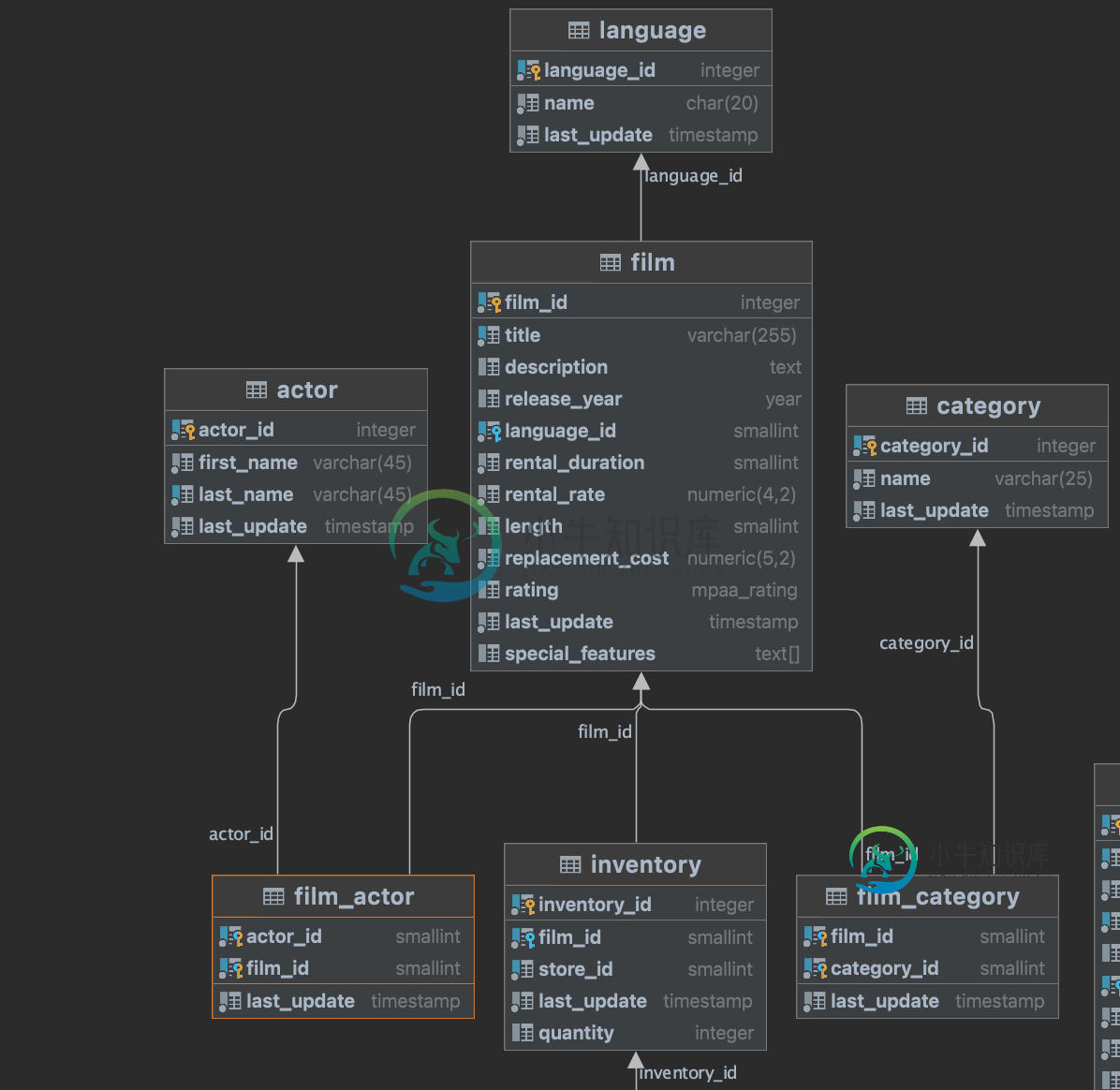
TransientDataAccessResourceException:未能更新表[film\u类别]。Id为[1006]的行不存在。
https://gist.github.com/harryalto/d91e653ca1054038b766169142737f87
电影实体ID未持久化,因此相关插入失败。
共有1个答案

我解决了这个问题。主要问题是,对于film\u category和film\u actor,主要由外键组合而成(即film\u id from film,category\u id from category/actor\u id from actor)。我不得不更改存储库的定义
@Repository
public interface FilmActorRepository extends
ReactiveCrudRepository<FilmActor, FilmActorPK> {
@Query("select * from film_actor where film_id = :film_id")
Flux<FilmActor> findAllByFilmId(@Param("film_id") final Long filmId);
@Query("select * from film_actor where film_id = :film_id and actor_id = :actor_id limit 1")
Mono<FilmActor> findByFilmIdAndActorId(@Param("film_id") final Long filmId, @Param("actor_id") final Long actorId);
@Modifying
@Query("insert into film_actor (film_id, actor_id, last_update) values (:#{#filmActor.filmId}, :#{#filmActor.actorId}, now()) on conflict DO NOTHING")
Mono<FilmActor> save(final FilmActor filmActor);
}
其中,FilmActorPK定义为
@Value
@Builder
public class FilmActorPK implements Serializable {
private long filmId;
private long actorId;
}
我做了类似的练习,为电影类别存储库
@Repository
public interface FilmCategoryRepository extends
ReactiveCrudRepository<FilmCategory, FilmCategoryPK> {
@Query("select * from film_category where category_id = :category_id and film_id = :film_id limit 1")
Mono<FilmCategory> findFirstByCategoryIdAndFilmId(@Param("category_id") Long categoryId, @Param("film_id") Long filmId);
@Query("select * from film_category where film_id = :film_id limit 1")
Mono<FilmCategory> findFirstByFilmId(@Param("film_id") Long filmId);
@Modifying
@Query(
"insert into film_category (film_id, category_id, last_update)
values (:#{#filmCategory.filmId}, :#{#filmCategory.categoryId},
now()) on conflict DO NOTHING"
)
Mono<FilmCategory> save(final FilmCategory filmCategory);
}
其中FilmClass oryPK定义为
@Value
@Builder
public class FilmCategoryPK implements Serializable {
private long filmId;
private long categoryId;
}
这个想法是从这个问题上提出来的
这解决了我的问题。我理解R2DBC有不同的理念,可以在R2DBC中做一些事情,使其与类似JPA的语法对等,而有些事情是不可能的。但我真的很喜欢R2DBC,因为我做了更多的练习作为我学习的一部分。
-
当我执行一个sql脚本时。我遇到了倾斜数据问题,所以我尝试设置参数来优化它,如下所示 Hadoop版本:v2.4.0 当我尝试时,我得到了以下错误: SLF4J:类路径包含多个SLF4J绑定。slf4j:在[jar:file:/home/www/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/static
-
我正在批量插入同一分区的多行,如果不存在。从我的测试中可以看出,如果任何行是重复的,则所有插入都将失败,并且不会插入任何行。我想保留if不存在行为,但如果存在重复项并且仍然插入非重复行,则不会使批处理失败。有没有办法告诉卡桑德拉,如果有重复项,不要让批处理失败?
-
问题内容: 我有一个具有以下结构和数据的表: 当我执行以下SQL: 我得到以下结果: 服务器是基于什么决定决定返回吉尔和弗雷德,并排除杰克和汤姆? 我在MySQL中运行此查询。 注意1:我知道查询本身没有任何意义。我正在尝试调试“ GROUP BY”方案的问题。我试图了解用于此目的的默认行为。 注2:我习惯于编写与GROUP BY子句相同的SELECT子句(减去聚合字段)。当我遇到上述行为时,我开
-
我使用的是ehcache 1.2.3。由于缓存大小是根据“元素”指定的,缓存占用的内存可能会有很大差异(ehcache与hibernate一起使用,并且还保存标准查询缓存,其中查询返回大小可能会有所不同的结果集)。我的问题是:如果JVM内存不足会发生什么。阅读ehcache的变更日志给我的印象是,最初它使用的是软引用,但由于java 1.4正在大力清理它们,软引用最终被删除了。因此,如果缓存太大,
-
我听说chrome已经为“img”元素实现了本机延迟加载,firefox也将很快跟进。 我找到的解释告诉我们,当您向img元素添加一个属性load=“lazy”时,它只会在浏览器认为它“靠近”视口时请求src url,“close”的定义取决于实际可用带宽。 我的问题实际上是关于内存消耗。在实际加载了延迟加载的图像,并且图像离视口足够远之后,浏览器是否会释放内存,在必要时再次延迟加载(可能是从磁盘