
使用java、itext和POI API将excel文件转换为pdf并保留设置

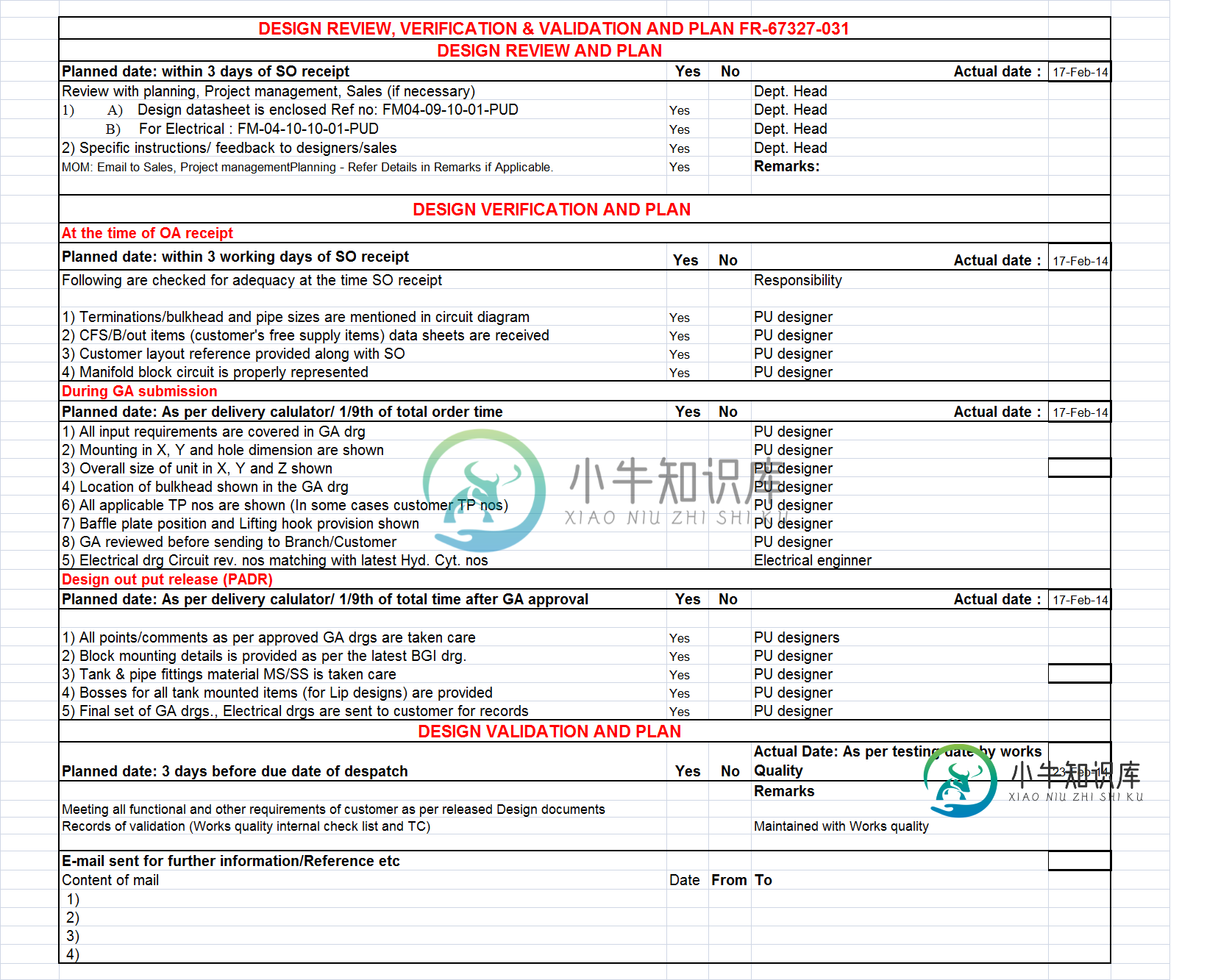
我有一个Excel文件,它有5列,几乎没有合并单元格、空白单元格、日期和其他文本信息(普通Excel文件)。
我正在使用java中的POI API读取此文件。我能够使用iText jar将文件转换为pdf表。
但是,整个格式不会复制到pdf中。(例如,合并的单元格进入一列,其他格式或设置都消失了)。
将创建一个简单的pdf表格。
如何保留与excel中相同的格式?(我想要pdf格式的excel表的精确副本)
这是我正在使用的代码
//First we read the Excel file in binary format into FileInputStream
FileInputStream input_document = new FileInputStream(new File("K:\\DCIN_TER\\DCIN_EPU2\\CIRCUIT FROM BRANCH\\RAINBOW ORDERS\\" + SONo.trim() + "\\" + SONo.trim() + " - Checklist.xls"));
// Read workbook into HSSFWorkbook
HSSFWorkbook my_xls_workbook = new HSSFWorkbook(input_document);
// Read worksheet into HSSFSheet
HSSFSheet my_worksheet = my_xls_workbook.getSheetAt(0);
// To iterate over the rows
Iterator<Row> rowIterator = my_worksheet.iterator();
//We will create output PDF document objects at this point
com.itextpdf.text.Document iText_xls_2_pdf = new com.itextpdf.text.Document();
PdfWriter.getInstance(iText_xls_2_pdf, new FileOutputStream("K:\\DCIN_TER\\DCIN_EPU2\\CIRCUIT FROM BRANCH\\RAINBOW ORDERS\\" + SONo.trim() + "\\" + SONo.trim() + " - Checklist.pdf"));
iText_xls_2_pdf.open();
//we have 5 columns in the Excel sheet, so we create a PDF table with 5 columns; Note: There are ways to make this dynamic in nature, if you want to.
PdfPTable my_table = new PdfPTable(5);
//We will use the object below to dynamically add new data to the table
PdfPCell table_cell;
//Loop through rows.
while(rowIterator.hasNext())
{
Row rowi = rowIterator.next();
Iterator<Cell> cellIterator = rowi.cellIterator();
while(cellIterator.hasNext())
{
Cell celli = cellIterator.next(); //Fetch CELL
switch(celli.getCellType())
{
//Identify CELL type you need to add more code here based on your requirement / transformations
case Cell.CELL_TYPE_STRING:
//Push the data from Excel to PDF Cell
table_cell = new PdfPCell(new Phrase(celli.getStringCellValue()));
//move the code below to suit to your needs
my_table.addCell(table_cell);
break;
case Cell.CELL_TYPE_NUMERIC:
//Push the data from Excel to PDF Cell
table_cell = new PdfPCell(new Phrase("" + celli.getNumericCellValue()));
//move the code below to suit to your needs
my_table.addCell(table_cell);
break;
}
//next line
}
}
//Finally add the table to PDF document
iText_xls_2_pdf.add(my_table);
iText_xls_2_pdf.close();
//we created our pdf file..
input_document.close(); //close xls
我已将excel文件附加为图像
共有2个答案

使用Apache Tika,您可以将xlsx文件转换为html格式,并通过Apache pdfbox将html格式的文本转换为pdf。

您使用过ExcelToHtmlConverter吗?它在Apache POI的3.13版本中。它与WordToHtmlConverter具有相同的用法。将Excel转换为超文本标记语言后,您可以使用iText将超文本标记语言转换为PDF。这是我通过使用这些工具获得的PDF:
-
问题内容: 我正在尝试使用iText库将.txt文件转换为.pdf文件。我面临的问题如下: 我在txt文件中有清晰的格式,与此类似: 在输出中,格式消失了,看起来像这样: 代码如下: 我还尝试使用IDENTITY_H创建BaseFont,但是它不起作用。我猜这是关于编码或类似的东西。你怎么看?我用完了解决方案… 谢谢 LE:正如艾伦(Alan)以及iText页面上的教程所建议的那样,除了我现有的代
-
我正在尝试将HTML转换为PDF。首先,我从下面的链接将我的HTML代码转换为XHTML。http://www.cruto.com/resources/code-generators/code-converters/html-to-xhtml.asp 然后,为了测试它,我用生成的XHTML代码创建了一个HTML文件,并成功地显示在浏览器上。之后,我尝试用下面的java代码将HTML文件转换为PDF
-
我想用iText将带有图像的html文件转换成pdf格式。我在这里提供我的消息来源。 请帮助我如何使用iText将带有图像的html文件转换为pdf格式。如果没有图像或者硬编码图像路径,我可以转换html文件。提前致谢
-
将html文件转换为pdf文件。我有html文件,css文件和js文件在一个文件夹,我如何转换index.html创建pdf使用Java的itext。有谁能帮我解决这个问题。有没有样本项目?
-
当尝试使用将文件转换为文件时,会出现以下异常: RuntimeException:Scanline必须以EOL代码字开头。在com.itextpdf.text.pdf.codec.tifffaxdecoder.readeol(tifffaxdecoder.java:1303),在com.itextpdf.text.pdf.codec.tifffaxdecoder.decode2d(tifffaxd
-
我正在寻找一些“稳定”的方法来转换从MS WORD到PDF文件的DOCX文件。从现在起,我使用OpenOffice安装作为监听器,但它经常挂起。问题是,当许多用户同时想要将SXW、DOCX文件转换成PDF时,我们会遇到这样的情况。还有其他的可能性吗?我尝试了这个网站上的示例:https://angelozerr.wordpress.com/2012/12/06/how-to-convert-doc