
批量标准化参数[副本]

共有1个答案

是的,你是对的。BatchNorm应用于致密层中的每个单元。但是,对于卷积层,我们仅将其应用于不同的信道。因为,权重在通道中共享。这里给出了更全面的答案
-
问题内容: 我试图切换一些硬编码的查询以使用参数化输入,但是遇到一个问题:如何格式化参数化批量插入的输入? 当前,代码如下所示: 一个可能的解决方案(从如何将数组插入到一个带有PHP和PDO的单个MySQL Prepared语句中 修改而来)似乎是: 有没有更好的方法来完成带有参数化查询的批量插入? 问题答案: 好吧,您有三个选择。 一次构建-执行多次。基本上,您只需为一行准备一次插入,然后循环执
-
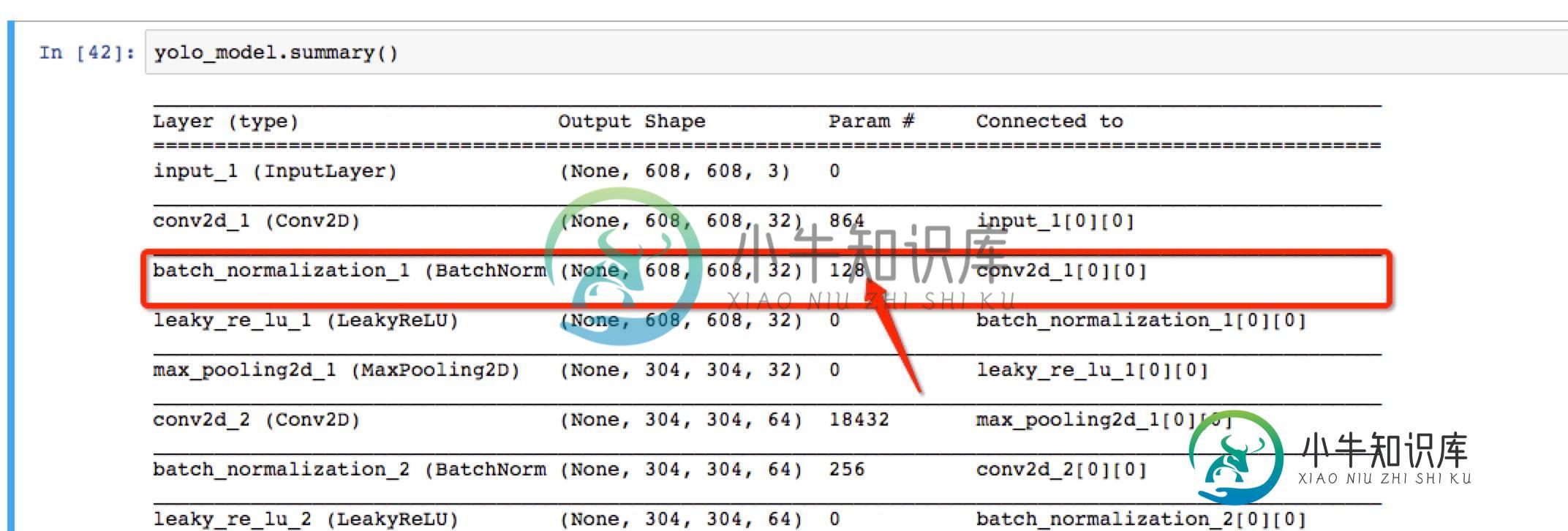
我的问题是批处理规范化(BN)正在规范化什么。 我在问,BN是单独标准化每个像素的通道还是一起标准化所有像素的通道。它是在每张图像的基础上还是在整个批次的所有通道上进行的。 具体而言,BN在X上运行。比如说,。因此,当轴=3时,它在“c”维度上运行,即通道数(对于rgb)或特征图数。 因此,假设X是rgb,因此有3个通道。BN是否做到了以下几点:(这是BN的简化版本,用于讨论维度方面。我知道gam
-
最近,我读了很多关于keras批处理规范化的文章,讨论了很多。 根据该网站:设置“tf.layers.batch\u normalization”中的“training=False”,这样训练将获得更好的验证结果 答案是: 如果使用training=True启用批次标准化,则将开始标准化批次本身,并收集每个批次的平均值和方差的移动平均值。现在是棘手的部分。移动平均值是指数移动平均值,tf的默认动量
-
我有64位MacOS汇编代码,它对数组执行二进制搜索。标准 C 库中的二进制搜索是: 我的集会看起来像 我想知道是否具有任何明确的参数顺序,即是否有任何方法可以知道对应于这里?它是,,?
-
我有一个db2表t1,其中一个列是通过使用一个标量函数填充的,该函数接受两个字符串参数。 在准备sql代码时,如下所示: 当我现在向准备好的语句添加一个参数时,我得到一个错误,即第一个参数的类型不正确。 我已经尝试用单引号包装第一个参数,但没有效果。还有谁有过这个问题并且已经找到了解决办法吗?主要的问题是,我现在确定db2引擎如何为标量函数准备第一个字符串参数,以便首先抛出错误。
-
当我读到一篇论文《批量规范化:通过减少内部协变量转移来加速深层网络训练》时,我想到了一些问题。 在报纸上,它说: 由于训练数据中的m个样本可以估计所有训练数据的均值和方差,因此我们使用小批量来训练批量归一化参数。 我的问题是: 他们是选择m个示例,然后同时拟合批次范数参数,还是为每个输入维度选择不同的m个示例集? E、 g.训练集由x(i)=(x1,x2,…,xn)组成:固定批次的n维,执行所有拟