
使用一个JenkinFile或多个JenkinFile

我们目前正在使用Windows\Jenkins 2.107.1(无管道),我正在研究管道。我们有一个夜间构建作业,它从存储库中获取、提交和等待其他作业。我看到9个作业同时在同一主节点上运行(我们只有一个主节点)。我不清楚我们应该有一个Jenkinsfile还是多个Jenkinsfile。它不会是一个多分支管道,因为我们不会创建测试分支,然后再合并回主管道。在存储库中,我们有product1.0分支、product2.0分支等,并且只构建了一个分支(最新的一个)。虽然我确实喜欢Blue Ocean编辑器,但它只适用于多分支管道。
我是将所有作业合并到一个Jenkinsfile中,还是为每个现有作业创建多个jenkins文件(Jenkinsfilestart、JenkinsfileFetchCVs、JenkinsFileFetchGit、Jenkinsfilenextjob等,并让一个调用另一个)?。我是否将所有旧作业创建为Jenkinsfile,或由一个主Jenkinsfile执行的脚本?我是用声明式还是脚本?
已经在测试VM上建立了Jenkins管道,但还不清楚该走哪条路。
寻找方向和/或示例。是否有关于如何转换现有Jenkins非管道系统的文档?
我在写了第一篇帖子后发现了这个。。。https://wiki.jenkins.io/display/JENKINS/Convert到管道插件。它确实有点帮助,因为它提供了一些已转换的步骤,但无法转换所有步骤,并将在管道脚本中给出注释“/”无法转换生成步骤,请根据需要进行验证并手动转换。“有一个选项“递归转换下游作业(如果有)”,如果选择该选项,则会将所有下游作业添加到同一管道脚本中,并且会混淆作业参数。还有一个选项“提交JenkinsFile”。我将进一步研究这个问题,但它不是转换为管道的全部,我仍然不确定是否应该有一个或多个脚本。
添加于19年7月26日-看看我的研究是否正确…
声明式管道(来自SCM的管道脚本)存储在存储库中的Jenkinsfile中。每次执行此Jenkins作业时,都会从存储库中获取(以获取最新版本的Jenkinsfile)。
管道脚本作为config.xml文件的一部分存储在Jenkins\作业文件夹中(它不存储在存储库中,也不存储在作业文件夹中的单独Jenkinsfile中)。只有当作业需要时,才会从存储库中获取管道脚本(您不需要执行存储库获取来获取管道脚本)。
除了我们的夜间产品生产之外,我们还有其他工作。我可以为其他每个作业为每个作业(JenkinsfileA、JenkinsfileB等)创建一个单独的声明性Jenkinsfile,然后也存储在存储库中(与主Jenkinsfile位于同一分支中),但这意味着每个附加作业,为了获得该作业的特定Jenkinsfile,还需要执行存储库提取(基本上是为每个作业提取\克隆存储库分支,并将存储库分支的多个版本不必要地下载到每个作业的工作区)。
这对我来说毫无意义(除非我迄今为止对事物的理解是错误的)。因为主产品构建在每次运行时都需要一个fetch(以获取任何可能的开发人员签入),所以我认为为该工作执行声明性Jenkinsfile没有问题。对于其他作业(如果我们不离开,则暂时采用经典(非管道)格式),它们将是管道脚本。
是否有任何方法(或计划)能够执行声明性管道,而无需存储在存储库中并每次执行提取(减少成为Groovy开发人员的需要)?Blue Ocean脚本编辑器似乎是一个更容易用于创建管道脚本的工具,但它仅适用于多分支管道(我们不这样做)。
序列化(重新启动作业),是仅适用于节点出现故障时,还是可以从任何点重新启动管道作业(声明式或脚本式),如果它失败了?
我看到有一些地方可以查看哪些Jenkins插件已移植到管道,但是否可以运行任何东西来查看您拥有的经典作业,以预先确定哪些作业将有问题转换为管道?
2019年2月8日。。。学习和玩管道。我看到您可以在Pipeline Scrip窗口中使用声明性,但它仍然将其存储在配置中。xml文件。我在同一个脚本中使用了声明性和非声明性的组合。
我正在尝试理解Blue Ocean接口,“Multi分支”这个词让我有点困惑。我们不创建测试分支,而是将它们合并回master。在存储库中,我们为产品的每个版本都有分支,并且我们很少回到以前的分支\版本。所以,如果我现在正在处理分支V9,我是否还需要Master分支中的Jenkinsfile,或者任何其他以前的版本分支?
我一直在玩蓝海(只做多分支管道)。我使用的是Windows系统Jenkins 2.176.2,从今天(1.18.0)起,我拥有所有最新的Blue Ocean插件。我正在访问一个本地Git存储库(不是GitHub),并遇到以下问题。。。
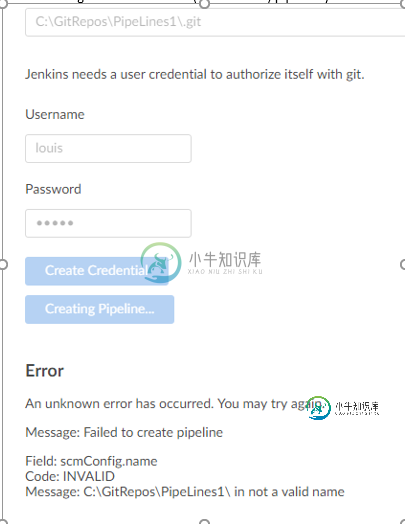
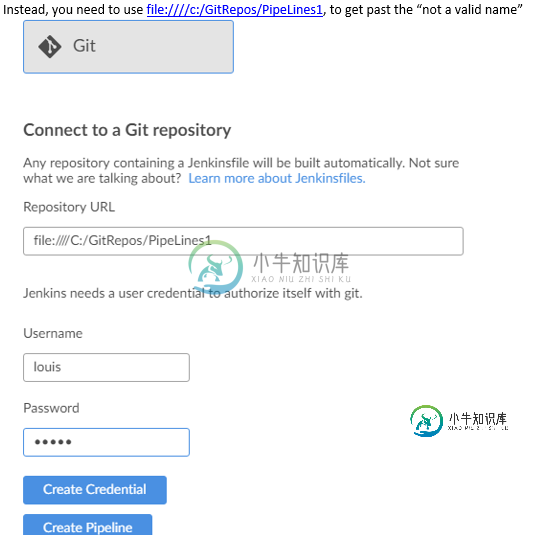
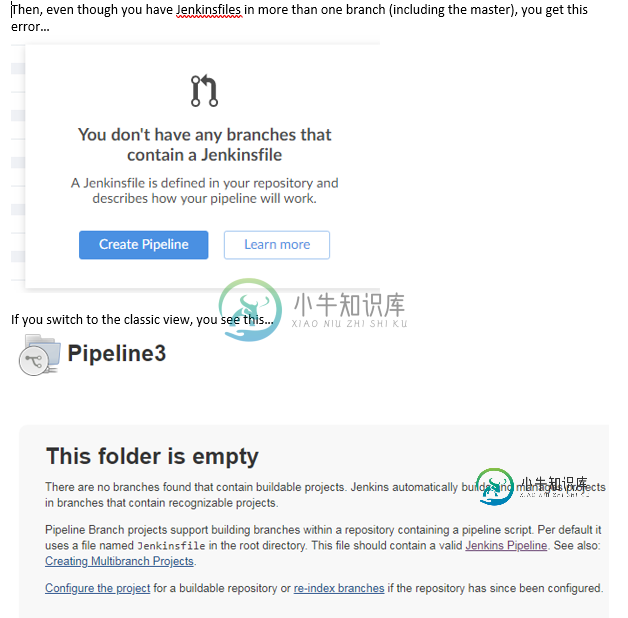
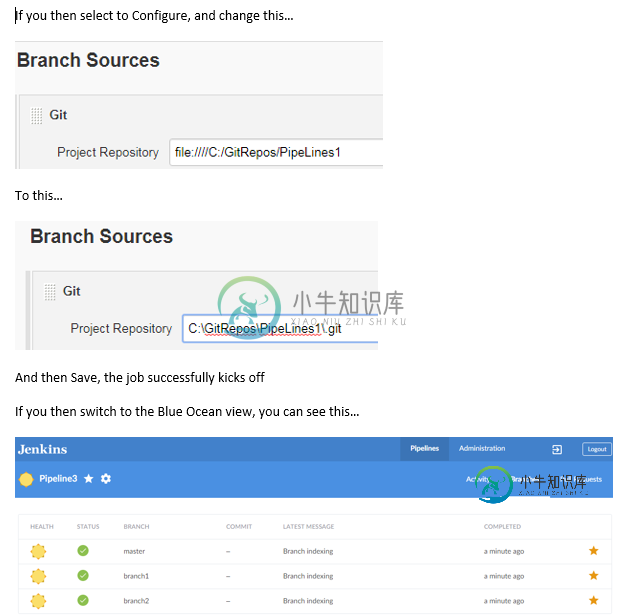
为什么会这样?
共有1个答案

如果您有一个作业要在多个分支上执行(可能有可选阶段,具体取决于分支名称或标签或其他),那么您仍然可以利用多分支管道。
总的来说,我想说范式转换主要集中在将旧作业转换为阶段,以便自动化构建过程。如果您有半自动/全自动的CI/CD流,这可能看起来像
- 多分支管道项目(所有分支),包括以下阶段(第一jenkinsfile)
-
问题内容: 我正在实现一个使用Realm在某些点(彼此之间不相关)持久化数据的应用程序。例如: 保存用户喜欢的项目。 (该应用进行聊天)保存聊天对话和最近的常量 为应用程序的某些请求实现永久性缓存 保存最近的搜索/表单以提供自动完成功能 (让这些点中的每一个都命名为模块/包) 每个模块/软件包都有一些持久性。我应该如何组织呢?从代码清洁度,性能或我应注意的任何方面考虑 选项A:使用具有唯一架构的唯
-
问题内容: 我只是想知道下面的if语句是否有效: 我的目标是确保同时满足以下2个要求:1. value [6]必须位于目标2.目标中的value [0]或value [1]如果我做了一个不好的例子,请道歉我的问题是,是否可以在一个语句中进行三个AND&OR?非常感谢! 问题答案: 使用 括号 将条件分组: 请注意,如果将定义为一组,则可以在固定时间内进行查找: 并且,正如@Pramod在评论中提到
-
问题内容: 我正在尝试优化将数据插入MySQL的代码的一部分。我应该将INSERT链接起来以制作一个巨大的多行INSERT还是更快地使用多个单独的INSERT? 问题答案: https://dev.mysql.com/doc/refman/8.0/zh-CN/insert- optimization.html 插入行所需的时间由以下因素决定,其中数字表示近似比例: 连接:(3) 向服务器发送查询:
-
问题内容: 我的javaswing应用程序中大约有3帧。如何处理这些框架的正确方法是什么?我的意思是某种模式或其他。现在,我总是有一个代表框架的类,一个代表面板的框架,这是该框架中的主要类。现在我已将帧定义为静态变量,当我想隐藏它们时,我称 这是正确的解决方案吗? 问题答案: 除了一个或多个实例的(出色)建议之外,还有一些其他策略可能会单独或组合使用,以将各种内容窗格折叠到一个框架中。 / (Tu
-
好吧,正如我试图在标题中总结的那样,下面是细节。 我们有一个相对较大的应用程序,它使用Dagger,以非常不理想的方式,所以我们决定开始编写测试,为此,我需要公开Mockito的依赖项,因此,我面临一个问题,开始使用单例工厂提供视图模型,仍然适用,并且有大量的教程可以解释这一点。 在我们的应用程序中,有许多使用单个活动实现的功能和导航组件,该单个活动有时具有创建的视图模型,我们使用该模型在容器活动
-
问题内容: 我有这个,在设定的总数时我得到一个错误。为什么我不能多次访问CTE? 问题答案: A基本上是一次性视图。它只保留一个语句,然后自动消失。 您的选择包括: 重新定义第二次。从定义的末尾到您的之前,这就像复制粘贴一样简单。 将结果放入表格或变量中 将结果具体化为真实表并引用 稍微更改一下即可,只需从您的CTE: 。