
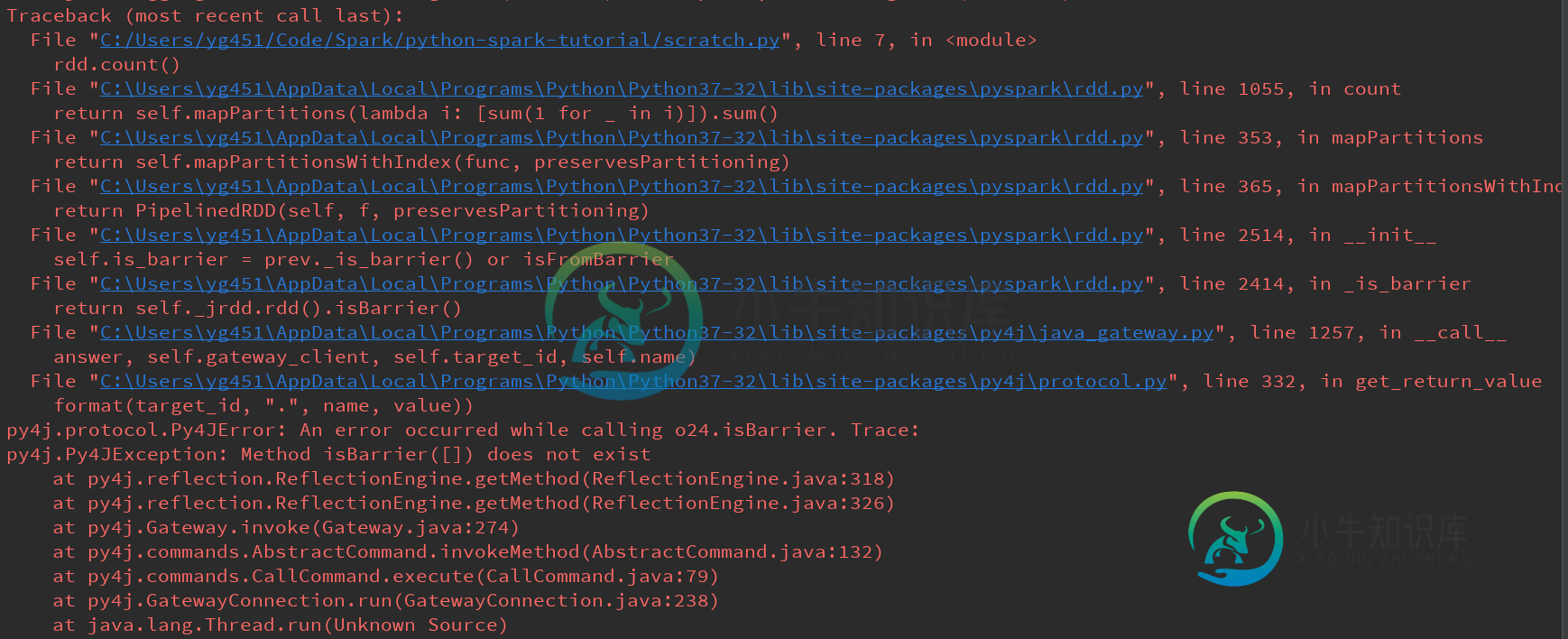
pyspark:方法isBarrier([])不存在

我正在尝试使用pyspark学习以下hello word级别的示例,例如下面的示例。我得到了一个“MethodisBarrier([])不存在”错误,代码下面包含了完整的错误。
from pyspark import SparkContext
if __name__ == '__main__':
sc = SparkContext('local[6]', 'pySpark_pyCharm')
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8])
rdd.collect()
rdd.count()
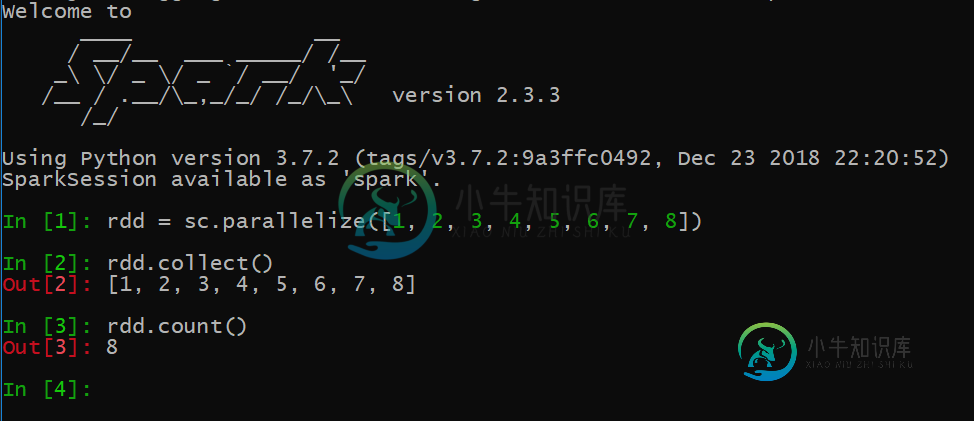
尽管如此,当我在命令行中直接启动pyspark会话并键入相同的代码时,它工作得很好:
我的设置:
- windows 10 Pro x64
共有3个答案

尝试使用Java 8(而不是更新版本),并使用
pip install findspark
然后在python脚本/会话开始时尝试导入此内容
import findspark
findspark.init()
from pyspark import SparkContext
这对我有用!


问题是Spark JVM库和PySpark版本之间不兼容。一般来说,PySpark版本必须与您的Spark安装版本完全匹配(而理论上匹配主要版本和次要版本就足够了,过去已经引入了维护版本中的一些不兼容性)。
换句话说,Spark 2.3.3与PySpark 2.4.0不兼容,您必须将Spark升级到2.4.0或将PySpark降级到2.3.3。
总的来说,PySpark不是设计用来作为独立库使用的。虽然PyPi包是一个方便的开发工具(只安装一个包通常比手动扩展PYTHONPATH更容易),但对于实际部署,最好坚持使用与实际Spark部署捆绑在一起的PySpark包。
-
问题内容: 这是代码段: 之后遇到错误: 所有其他方法都可以正常工作。试图进行大量研究但徒劳无功。任何线索将不胜感激 问题答案: 这表明Spark版本不匹配。在Spark 2.3 方法之前,仅接受两个参数: 从2.3开始,它需要三个参数: 在您的情况下,Python客户端似乎调用了后者,而JVM后端使用了较旧的版本。 由于初始化在2.4中进行了重大更改,这将导致上的失败,因此您可能使用: 2.3.
-
我正在尝试使用此代码使用代理版本0.10测试kafka流。这只是一个打印主题内容的简单代码。还没什么大不了的!但是,由于某种原因内存不足(VM中的10GB RAM)!代码: 运行火花提交: 不幸的是,结果是: java.lang.OutOfMemoryError:Java堆空间 我假设Kafka每次应该带一小部分数据来避免这个问题,对吗?那么,我做错了什么?
-
我正试图修改PySpark dataframe中的列值,如下所示: 这将生成以下异常: 调用O435时出错。跟踪:py4j.py4jException:Method或([class java.lang.string])在py4j.reflection.reflectionEngine.getMethod(reflectionEngine.java:318)在py4j.reflection.refl
-
我有一个非常奇怪的问题。当我提交表单时,它会引发服务器端验证错误。 BadMethodCallException 方法[validation必需]不存在。 我的控制器: 控制器在方法
-
我正在尝试为生产中的顶点类实现一个简单的更改。我有正确的类和正确的测试类。测试类在沙盒中成功运行,没有错误,但显然错误来自Salesforce中的TestHelper默认测试类。当尝试在生产中部署时,它会抛出错误“方法不存在或签名不正确:TestHelper类型中的空createUser(Id、String、String、Date、Intger)” 我尝试过将其引用的方法更改为public sta
-
问题内容: 我有一个很大的 pyspark.sql.dataframe.DataFrame 名为df。我需要某种枚举记录的方式- 因此,能够访问具有特定索引的记录。(或选择具有索引范围的记录组) 在大熊猫中,我可以 在这里我想要类似的东西 (并且不将数据框转换为熊猫) 我最接近的是: 通过以下方式枚举原始数据框中的所有对象: 问题: 为什么它不起作用以及如何使其起作用?如何在数据框中添加一行? 以