
通过PythonVirtualenvOperator在气流中多次运行成功的数据流管道

我正在运行一个Apache Beam管道(使用Google Dataflow部署),该管道正在与Apache Airflow一起编排。
DAG文件如下所示:
from airflow import DAG
from datetime import datetime, timedelta
from airflow.operators.python_operator import PythonVirtualenvOperator
import custom_py_file #beam job in this file
default_args = {
'owner': 'name',
'depends_on_past': False,
'start_date': datetime(2016, 1, 1),
'email': ['email@gmail.com'],
'email_on_failure': True,
'email_on_retry': False,
'retries': 3,
'retry_delay': timedelta(minutes=1),
}
CONNECTION_ID = 'proj'
with DAG('dag_pipeline', schedule_interval='@once', template_searchpath=['/home/airflow/gcs/dags/'], max_active_runs=15, catchup=True, default_args=default_args) as dag:
lines = PythonVirtualenvOperator(
task_id='lines',
python_callable=custom_py_file.main, #this file has a function main() where the beam job is declared
requirements=['apache-beam[gcp]', 'pandas'],
python_version=3,
dag=dag
)
lines
梁管道文件(custom\u py\u file.py)如下所示:
def main():
import apache_beam as beam
from apache_beam.options.pipeline_options import PipelineOptions
from apache_beam.options.pipeline_options import SetupOptions
import argparse
import time
class ETL(beam.DoFn):
def process(self, row):
#process data
def run(argv=None):
parser = argparse.ArgumentParser()
parser.add_argument(
'--input',
dest='input',
default='gs://bucket/input/input.txt',
help='Input file to process.'
)
known_args, pipeline_args = parser.parse_known_args(argv)
pipeline_args.extend([
'--runner=DataflowRunner',
'--project=proj',
'--region=region',
'--staging_location=gs://bucket/staging/',
'--temp_location=gs://bucket/temp/',
'--job_name=name-{}'.format(time.strftime("%Y%m%d%h%M%s").lower()),
'--setup_file=/home/airflow/gcs/dags/setup.py',
'--disk_size_gb=350',
'--machine_type=n1-highmem-96',
'--num_workers=24',
'--autoscaling_algorithm=NONE'
])
pipeline_options = PipelineOptions(pipeline_args)
pipeline_options.view_as(SetupOptions).save_main_session = True
with beam.Pipeline(options=pipeline_options) as p:
rows = (p | 'read rows' >> beam.io.ReadFromText(known_args.input))
etl = (rows | 'process data' >> beam.ParDo(ETL()))
p.run().wait_until_finish()
logging.getLogger().setLevel(logging.DEBUG)
run()
我正在使用PythonVirtualenvHandator,因为我无法将Python3和BashHandator与我当前版本的airflow(版本:1.10.2-comiler)一起使用,并且我需要Python3来运行此管道。
问题是,尽管运行成功,Airflow仍提交了另一个数据流作业。请注意,这不是重试,因为日志显示这是所有“一”个任务的运行。然而,数据流日志显示,它在成功运行一次之后,再次运行完全相同的作业。
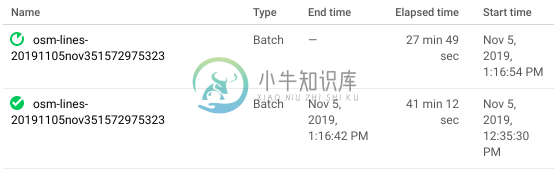
这是怎么回事?成功的数据流作业没有输出0值吗?如果运行正确,如何让它继续下一个任务?谢谢!
共有1个答案

事实上,它不被视为重试,并且一个作业在第一个作业结束后执行,这让我怀疑类似的事情。检查Python代码,我看到您用beam调用了这两个。管道()和p.run():
with beam.Pipeline(options=pipeline_options) as p:
rows = (p | 'read rows' >> beam.io.ReadFromText(known_args.input))
etl = (rows | 'process data' >> beam.ParDo(ETL()))
p.run().wait_until_finish()
这将触发两次连续处决。您可以选择其中一种(但不能同时选择两种):
with beam.Pipeline(options=pipeline_options) as p:
rows = (p | 'read rows' >> beam.io.ReadFromText(known_args.input))
etl = (rows | 'process data' >> beam.ParDo(ETL()))
p = beam.Pipeline(options=pipeline_options)
rows = (p | 'read rows' >> beam.io.ReadFromText(known_args.input))
etl = (rows | 'process data' >> beam.ParDo(ETL()))
p.run().wait_until_finish()
-
我的狗看起来像这样 我的DAG正在执行一个jar文件。jar文件包含运行数据流作业的代码,该作业将数据从GCS写入BQ。jar本身执行成功。 当我尝试执行airflow作业时,我看到以下错误 我做了更多的挖掘,我可以看到气流 正如您可以看到jobs之后的最后一个参数是asia east,因此我觉得airflow job正在尝试使用我在默认参数中提供的区域来搜索数据流job的状态。不确定这是否是正在
-
运行气流的一般说明不适用于Windows环境: 气流实用程序在命令行中不可用,我在其他地方找不到它可以手动添加。气流如何在Windows上运行?
-
有可能在流中过滤更多次吗?例如,如果我有一个带有ID的列表,我想流一个HashMap,并将HashMap的键映射到列表中的键,以及它们在哪里匹配,我想从HashMap中获取对象,并再次过滤它,例如该对象中的int字段大于3,并在最后求和。例如,如果它发现10种情况,其中列表的键和HashMap的键相等,它过滤这10种情况,并发现3种情况,例如int字段大于3,它最终返回这些的总和。 到目前为止,这
-
我有一个容器Airflow安装程序,使用LocalExector在马拉松上运行。我运行了一个运行状况检查,可以ping Airflow网络服务器上的endpoint。它目前有5个cpu分配给它,网络服务器正在运行4个Gunicorn。昨晚我有大约25个任务同时运行。这导致健康检查失败,没有一条有用的错误消息。容器刚刚收到一个SIGTERM。我想知道是否有人可以提出导致健康检查失败的可能罪魁祸首?是
-
我正在尝试为基于代理的模型(Repast)启动GUI,以便能够多次运行该模型。我将基于GUI中不同运行的不同分布生成输入参数。通常我们应该在不同的运行中使用批处理文件。然而,出于这个原因,我想使用GUI,因为我的GUI可以处理一次运行,但不能处理多次运行。你能帮我说说你在这方面的想法吗?
-
我试图创建和运行一个豆荚使用气流kubernetes豆荚操作员。下面的命令被尝试并确认有效,我正试图在本地使用kubernetes pod操作符复制相同的命令 有没有办法将serviceaccount标志传递给airflow kubernetes操作员? 谢了!