
unicode输出java windows cmd

System.out.println("سلام");
我真的很失望,我从C迁移只是为了得到一个更好的处理Unicode!
共有1个答案

我在Windows10上使用Intellij idea/Java1.8并尝试了一些杂乱无章的方法,但几乎可以使用。首先,代码如下:
import java.io.PrintStream;
import java.io.UnsupportedEncodingException;
public class Java901App {
public static void main(String[] args) {
//System.out.println("Hello world!");
//System.out.println("سلام");
try{
PrintStream outStream = new PrintStream(System.out, true, "UTF-8");
outStream.println("Hello world!");
outStream.println("سلام");
} catch(UnsupportedEncodingException e){
System.out.println("Caught exception: " + e.getMessage());
}
}
}
>
注意,PrintStream的编码设置为UTF-8。参见本帖的选定答案:在Mac终端中显示为问号的汉字
<罢工> 我添加了 基于Microsoft得本文得Windows得阿拉伯脚本补充字体: 为什么在Windows 10上的一些应用中,有些文字会以方框显示?我不确定这是否是必要的,但它肯定没有坏处。 我卸载了阿拉伯脚本补充字体,但没有任何更改,因此没有必要执行此步骤。
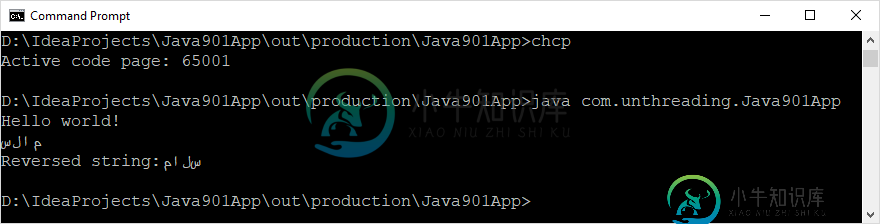
在从控制台运行应用程序之前,我调用了chcp65001。尽管PrintStream被定义为使用UTF-8,但这绝对是必不可少的,如下面的屏幕快照所示。
我尝试为命令提示符窗口设置不同的字体,方法是单击窗口左上方的图标,从下拉菜单中选择默认值,然后单击字体选项卡。有的起作用(如康索拉斯),有的没有作用(如哥特女士)。注意超级用户帖子中的评论:为了使CHCP65001工作,您必须在命令提示符中使用TrueType字体。
https://imgs.xnip.cn/cj/n/38/cc37e619-5aa8-4e94-8f2e-7702491ea309.png" width="100%" height="100%" />
因此,除了您提供的文本中的字符是以相反的顺序呈现的以外,它是正常的。有人知道如何解决这个问题吗?大概是通过在Java源代码中指定文本是从右向左的语言?
更新:
我修改了代码,以便在命令提示符窗口中正确呈现波斯语文本,尽管一个副作用是,当代码在IDE中运行时,波斯语文本不再正确呈现。以下是修改后的代码:
public static void main(String[] args) {
try{
StringBuilder persianHello = new StringBuilder("سلام");
PrintStream outStream = new PrintStream(System.out, true, "UTF-8");
outStream.println("Hello world!");
outStream.println(persianHello); // Renders backwards in console, but correctly in the IDE.
byte directionality = Character.getDirectionality(persianHello.charAt(0));
if (directionality == Character.DIRECTIONALITY_RIGHT_TO_LEFT_ARABIC) {
outStream.println("Reversed string:" + persianHello.reverse()); // Renders correctly in console, but backwards in the IDE...
}
} catch(UnsupportedEncodingException e){
System.out.println("Caught exception: " + e.getMessage());
}
}
-
我在scrapy的json输出上遇到问题。Crawler工作良好,cli输出没有问题。XML项目导出器工作正常,输出以正确的编码保存,文本没有转义。 < li >尝试使用管道并直接从那里保存项目。 < li >使用json库中的提要导出器和jsonencoder from > 这些不起作用,因为我的数据包括分支机构。 json 输出文件中的 Unicode 文本是这样转义的:“\u00d6\u01
-
编写了以下两个函数,用于存储和检索任何Python(内置或用户定义)对象,并结合使用json和jsonickle(在2.7中) 我还没有用用户定义的对象测试过这两个函数,但是当我试图保存()一个内置的字符串字典时,(即。{'Adam': 'Age 19 ',' Bill ',' Age 32'}),并且我检索相同的文件,我得到相同的unicode字典,{u'Adam': u'Age 19 ',u'
-
问题内容: 我试图输出简单的html unicode字符,例如从表达式中输出。 我尝试使用,但无法使其显示在HTML中。 html代码未注入到span balise中 不会解释html代码(html字符未出现在控制台中,但是如果我不使用控制器中的表达式并直接调用,则可以在控制台中看到正确解释的HTML字符,但仍未注入进入跨接栏杆) 如何从表达式输出html字符? 我导入脚本并将依赖项添加到我的应用
-
最近,由于浏览器支持的数据质量问题,我遇到了一个bug,我正在寻找一个安全规则,用于应用字符串转义而不需要双重大小,除非需要。 UTF-8字节序列“E2-80-A8”(U 2028,行分隔符),在Unicode数据库中是完全有效的字符。但是,该序列表示一个行分隔符(是,除“0A”外)。 而且糟糕的是,很多浏览器(包括Chrome、Firefox、Safari我没有测试其他的),无法处理一个JSON
-
使用将反斜杠作为文字反斜杠,因此我无法用unicode解析字符串输入。 我的意思是: 将之类的字符串粘贴到call中会被解释为 ,而不是两个单独的字符。 有人知道如何或如果可能的话,让它发生吗? 编辑:我将输入如上,并将其转换为ascii,如下。 根据我标记的答案,正确的解决方案是:
-
文件 std::fs::File 本身实现了 Read 和 Write trait,所以文件的输入输出非常简单,只要得到一个 File 类型实例就可以调用读写接口进行文件输入与输出操作了。而要得到 File 就得让操作系统打开(open)或新建(create)一个文件。还是拿例子来说明 use std::io; use std::io::prelude::*; use std::fs::File;