
Artemis集群消息重新分配似乎不起作用

我使用Artemis 2.6.3。我在对称拓扑中创建了2个节点。
生产者和消费者由这里描述的Spring Broker Relay处理。它写入地址/topic/notification/username/lual(多播),生成的队列是不持久的。
消费者仅在连接到节点1(产生消息的位置)时接收消息。我可以让一个连接到节点1接收消息,另一个连接到节点2不接收消息。如果两个节点都在节点2上,则无人接收消息。
我认为信息再分配不起作用,但无法找出原因。我遵循了示例和可用的文档。我在下面添加了所有配置。
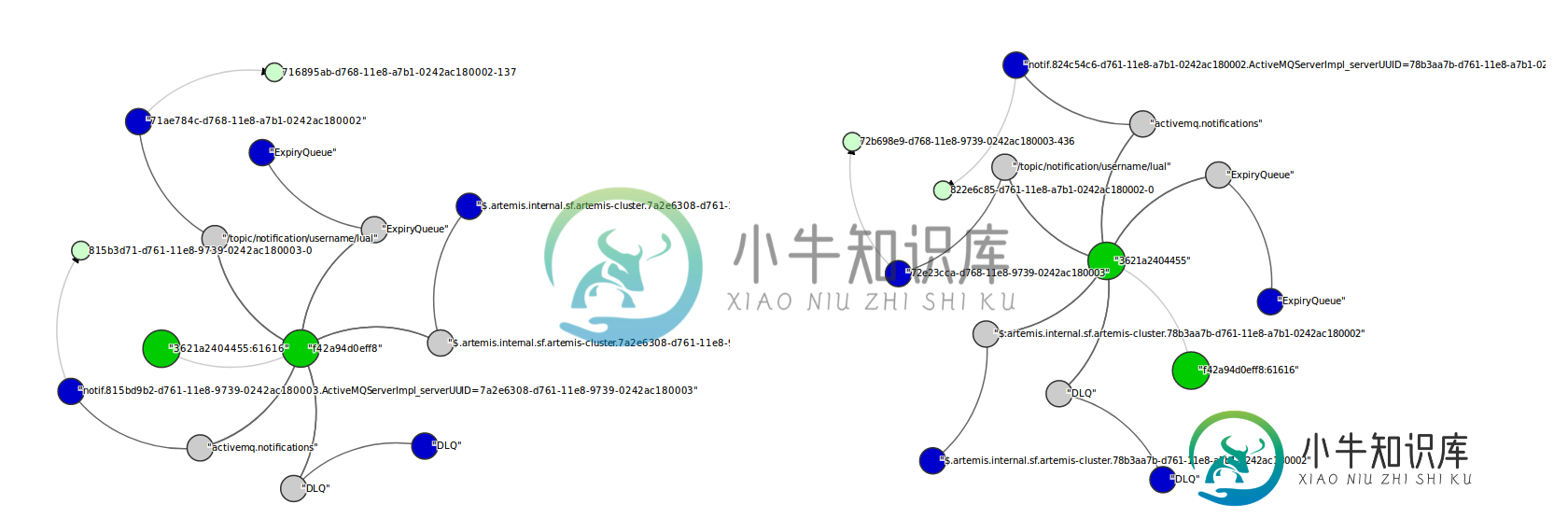
生成的图表:
经纪人。xml:
<configuration xmlns="urn:activemq"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:xi="http://www.w3.org/2001/XInclude"
xsi:schemaLocation="urn:activemq /schema/artemis-configuration.xsd">
<core xmlns="urn:activemq:core" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="urn:activemq:core ">
<name>$HOSTNAME</name>
<persistence-enabled>true</persistence-enabled>
<!-- this could be ASYNCIO, MAPPED, NIO
ASYNCIO: Linux Libaio
MAPPED: mmap files
NIO: Plain Java Files
-->
<journal-type>ASYNCIO</journal-type>
<paging-directory>data/paging</paging-directory>
<bindings-directory>data/bindings</bindings-directory>
<journal-directory>data/journal</journal-directory>
<large-messages-directory>data/large-messages</large-messages-directory>
<journal-datasync>true</journal-datasync>
<journal-min-files>2</journal-min-files>
<journal-pool-files>10</journal-pool-files>
<journal-file-size>10M</journal-file-size>
<!--
This value was determined through a calculation.
Your system could perform 0,47 writes per millisecond
on the current journal configuration.
That translates as a sync write every 2148000 nanoseconds.
Note: If you specify 0 the system will perform writes directly to the disk.
We recommend this to be 0 if you are using journalType=MAPPED and journal-datasync=false.
-->
<journal-buffer-timeout>2148000</journal-buffer-timeout>
<!--
When using ASYNCIO, this will determine the writing queue depth for libaio.
-->
<journal-max-io>1</journal-max-io>
<!--
You can verify the network health of a particular NIC by specifying the <network-check-NIC> element.
<network-check-NIC>theNicName</network-check-NIC>
-->
<!--
Use this to use an HTTP server to validate the network
<network-check-URL-list>http://www.apache.org</network-check-URL-list> -->
<!-- <network-check-period>10000</network-check-period> -->
<!-- <network-check-timeout>1000</network-check-timeout> -->
<!-- this is a comma separated list, no spaces, just DNS or IPs
it should accept IPV6
Warning: Make sure you understand your network topology as this is meant to validate if your network is valid.
Using IPs that could eventually disappear or be partially visible may defeat the purpose.
You can use a list of multiple IPs, and if any successful ping will make the server OK to continue running -->
<!-- <network-check-list>10.0.0.1</network-check-list> -->
<!-- use this to customize the ping used for ipv4 addresses -->
<!-- <network-check-ping-command>ping -c 1 -t %d %s</network-check-ping-command> -->
<!-- use this to customize the ping used for ipv6 addresses -->
<!-- <network-check-ping6-command>ping6 -c 1 %2$s</network-check-ping6-command> -->
<connectors>
<!-- Connector used to be announced through cluster connections and notifications -->
<connector name="artemis">tcp://$HOSTNAME:61616</connector>
</connectors>
<!-- how often we are looking for how many bytes are being used on the disk in ms -->
<disk-scan-period>5000</disk-scan-period>
<!-- once the disk hits this limit the system will block, or close the connection in certain protocols
that won't support flow control. -->
<max-disk-usage>90</max-disk-usage>
<!-- should the broker detect dead locks and other issues -->
<critical-analyzer>true</critical-analyzer>
<critical-analyzer-timeout>120000</critical-analyzer-timeout>
<critical-analyzer-check-period>60000</critical-analyzer-check-period>
<critical-analyzer-policy>HALT</critical-analyzer-policy>
<!-- the system will enter into page mode once you hit this limit.
This is an estimate in bytes of how much the messages are using in memory
The system will use half of the available memory (-Xmx) by default for the global-max-size.
You may specify a different value here if you need to customize it to your needs.
<global-max-size>100Mb</global-max-size>
-->
<acceptors>
<!-- useEpoll means: it will use Netty epoll if you are on a system (Linux) that supports it -->
<!-- amqpCredits: The number of credits sent to AMQP producers -->
<!-- amqpLowCredits: The server will send the # credits specified at amqpCredits at this low mark -->
<!-- Note: If an acceptor needs to be compatible with HornetQ and/or Artemis 1.x clients add
"anycastPrefix=jms.queue.;multicastPrefix=jms.topic." to the acceptor url.
See https://issues.apache.org/jira/browse/ARTEMIS-1644 for more information. -->
<!-- Acceptor for every supported protocol -->
<acceptor name="artemis">tcp://$HOSTNAME:61616?tcpSendBufferSize=1048576;tcpReceiveBufferSize=1048576;protocols=CORE,AMQP,STOMP,HORNETQ,MQTT,OPENWIRE;useEpoll=true;amqpCredits=1000;amqpLowCredits=300</acceptor>
<!-- AMQP Acceptor. Listens on default AMQP port for AMQP traffic.-->
<acceptor name="amqp">tcp://$HOSTNAME:5672?tcpSendBufferSize=1048576;tcpReceiveBufferSize=1048576;protocols=AMQP;useEpoll=true;amqpCredits=1000;amqpLowCredits=300</acceptor>
<!-- STOMP Acceptor. -->
<acceptor name="stomp">tcp://$HOSTNAME:61613?tcpSendBufferSize=1048576;tcpReceiveBufferSize=1048576;protocols=STOMP;useEpoll=true</acceptor>
<!-- HornetQ Compatibility Acceptor. Enables HornetQ Core and STOMP for legacy HornetQ clients. -->
<acceptor name="hornetq">tcp://$HOSTNAME:5445?anycastPrefix=jms.queue.;multicastPrefix=jms.topic.;protocols=HORNETQ,STOMP;useEpoll=true</acceptor>
<!-- MQTT Acceptor -->
<acceptor name="mqtt">tcp://$HOSTNAME:1883?tcpSendBufferSize=1048576;tcpReceiveBufferSize=1048576;protocols=MQTT;useEpoll=true</acceptor>
</acceptors>
<cluster-user>adminCluster</cluster-user>
<cluster-password>adminCluster</cluster-password>
<broadcast-groups>
<broadcast-group name="artemis-broadcast-group">
<jgroups-file>jgroups-stacks.xml</jgroups-file>
<jgroups-channel>artemis_broadcast_channel</jgroups-channel>
<!--<broadcast-period>5000</broadcast-period>-->
<connector-ref>artemis</connector-ref>
</broadcast-group>
</broadcast-groups>
<discovery-groups>
<discovery-group name="artemis-discovery-group">
<jgroups-file>jgroups-stacks.xml</jgroups-file>
<jgroups-channel>artemis_broadcast_channel</jgroups-channel>
<refresh-timeout>10000</refresh-timeout>
</discovery-group>
</discovery-groups>
<cluster-connections>
<cluster-connection name="artemis-cluster">
<address>#</address>
<connector-ref>artemis</connector-ref>
<check-period>1000</check-period>
<connection-ttl>5000</connection-ttl>
<min-large-message-size>50000</min-large-message-size>
<call-timeout>5000</call-timeout>
<retry-interval>500</retry-interval>
<retry-interval-multiplier>2.0</retry-interval-multiplier>
<max-retry-interval>5000</max-retry-interval>
<initial-connect-attempts>-1</initial-connect-attempts>
<reconnect-attempts>-1</reconnect-attempts>
<use-duplicate-detection>true</use-duplicate-detection>
<forward-when-no-consumers>false</forward-when-no-consumers>
<max-hops>1</max-hops>
<confirmation-window-size>32000</confirmation-window-size>
<call-failover-timeout>30000</call-failover-timeout>
<notification-interval>1000</notification-interval>
<notification-attempts>2</notification-attempts>
<discovery-group-ref discovery-group-name="artemis-discovery-group"/>
</cluster-connection>
</cluster-connections>
<security-settings>
<security-setting match="#">
<permission type="createNonDurableQueue" roles="amq"/>
<permission type="deleteNonDurableQueue" roles="amq"/>
<permission type="createDurableQueue" roles="amq"/>
<permission type="deleteDurableQueue" roles="amq"/>
<permission type="createAddress" roles="amq"/>
<permission type="deleteAddress" roles="amq"/>
<permission type="consume" roles="amq"/>
<permission type="browse" roles="amq"/>
<permission type="send" roles="amq"/>
<!-- we need this otherwise ./artemis data imp wouldn't work -->
<permission type="manage" roles="amq"/>
</security-setting>
</security-settings>
<address-settings>
<!-- if you define auto-create on certain queues, management has to be auto-create -->
<address-setting match="activemq.management#">
<dead-letter-address>DLQ</dead-letter-address>
<expiry-address>ExpiryQueue</expiry-address>
<redelivery-delay>0</redelivery-delay>
<!-- with -1 only the global-max-size is in use for limiting -->
<max-size-bytes>-1</max-size-bytes>
<message-counter-history-day-limit>10</message-counter-history-day-limit>
<address-full-policy>PAGE</address-full-policy>
<auto-create-queues>true</auto-create-queues>
<auto-create-addresses>true</auto-create-addresses>
<auto-create-jms-queues>true</auto-create-jms-queues>
<auto-create-jms-topics>true</auto-create-jms-topics>
</address-setting>
<!--default for catch all-->
<address-setting match="#">
<dead-letter-address>DLQ</dead-letter-address>
<expiry-address>ExpiryQueue</expiry-address>
<redelivery-delay>0</redelivery-delay>
<!-- with -1 only the global-max-size is in use for limiting -->
<max-size-bytes>-1</max-size-bytes>
<message-counter-history-day-limit>10</message-counter-history-day-limit>
<address-full-policy>PAGE</address-full-policy>
<auto-create-queues>true</auto-create-queues>
<auto-create-addresses>true</auto-create-addresses>
<auto-create-jms-queues>true</auto-create-jms-queues>
<auto-create-jms-topics>true</auto-create-jms-topics>
<redistribution-delay>0</redistribution-delay>
</address-setting>
</address-settings>
<addresses>
<address name="DLQ">
<anycast>
<queue name="DLQ" />
</anycast>
</address>
<address name="ExpiryQueue">
<anycast>
<queue name="ExpiryQueue" />
</anycast>
</address>
</addresses>
</core>
</configuration>
jgroups。xml:
<config xmlns="urn:org:jgroups"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="urn:org:jgroups http://www.jgroups.org/schema/JGroups-3.0.xsd">
<UDP ip_ttl="8"
max_bundle_size="64000"
ip_mcast="false"
thread_pool.enabled="true"
thread_pool.min_threads="1"
thread_pool.max_threads="10"
thread_pool.keep_alive_time="5000"
thread_pool.queue_enabled="false"
thread_pool.queue_max_size="100"
thread_pool.rejection_policy="run"
oob_thread_pool.enabled="true"
oob_thread_pool.min_threads="1"
oob_thread_pool.max_threads="8"
oob_thread_pool.keep_alive_time="5000"
oob_thread_pool.queue_enabled="false"
oob_thread_pool.queue_max_size="100"
oob_thread_pool.rejection_policy="run"
bind_addr="match-interface:eth.*"
receive_interfaces="eth0"
/>
<BPING
dest="$BROADCAST_ADDR"
port_range="10"
bind_port="8555"/>
<MERGE2 max_interval="30000"
min_interval="10000"/>
<FD_SOCK/>
<FD timeout="10000" max_tries="5" />
<VERIFY_SUSPECT timeout="1500" />
<BARRIER />
<pbcast.NAKACK
use_mcast_xmit="false"
retransmit_timeout="300,600,1200,2400,4800"
discard_delivered_msgs="true"/>
<UNICAST />
<pbcast.STABLE stability_delay="1000" desired_avg_gossip="50000"
max_bytes="400000"/>
<pbcast.GMS print_local_addr="true" join_timeout="3000"
view_bundling="true"/>
<FC max_credits="2000000"
min_threshold="0.10"/>
<FRAG2 frag_size="60000" />
<pbcast.STATE_TRANSFER/>
<pbcast.FLUSH/>
</config>
调试日志在这里
共有1个答案

我相信您的问题是集群连接中地址使用的值:
<address>#</address>
您在这里将地址视为支持通配符匹配,而实际上它不支持。留档明确说明了这一点(强调我的):
每个群集连接仅适用于与指定的地址字段匹配的地址。当一个地址以该字段中指定的字符串开头时,它在群集连接上匹配。群集连接上的地址字段还支持逗号分隔的列表和排除语法
。要防止在此群集连接上匹配地址,请在群集连接地址字符串前面加上
。
因此,通过使用#作为地址的值,你是说只有以#开头的地址才应该被集群化——可能不是你想要的。我的猜测是,您希望所有地址都被集群化,在这种情况下,您应该将地址留空。文档中的示例为空,文档说明:
在上面所示的情况下,集群连接将负载平衡消息发送到所有地址(因为它是空的)。
-
在https://access.redhat.com/documentation/en-us/red_hat_jboss_enterprise_application_platform/7.1/html/configuring_messaging/clusters_overview中的第29项之后,重新分发测试不起作用。 测试用例:1个jboss主程序和2个jboss从程序。我在artemis中创
-
我在Kubernetes有一个Artemis集群,有3组主/从: 我使用Spring boot JmsListener来使用发送到通配符队列的消息,如下所示。 master-0上通配符队列的属性如下所示: 目前使用的Artemis版本是2.17.0。下面是我在master-0中的集群配置。除了被更改以匹配代理之外,其他代理的配置是相同的: 从堆栈溢出的另一个答案中,我了解到我的高可用性拓扑是冗余的
-
我的代码看起来像 我的文件如下所示 当我运行程序时,我看到 我怎样才能修好它呢?
-
问题内容: 我在使用该功能时遇到了麻烦。 我只需要知道SQL查询是否返回零行。 我已经尝试过以下简单的语句: 类型是哪里。上面的代码似乎不起作用。无论是否为空,它将始终打印该消息。 我检查了SQL查询本身,当存在行时它正确返回了非空结果。 关于如何确定查询是否已返回0行的任何想法?我用谷歌搜索,找不到任何答案。 问题答案: ResultSet.getFetchSize()不返回结果数!从这里: 使
-
下面的方法有2个for循环。Firstloop迭代36000次,inner forloop迭代24次,因此记录插入的总数将为864000。代码执行运行了将近3.5小时并终止。(记录插入失败)只有在outer for循环结束后才会关闭会话并提交事务。发现执行过程中RAM消耗近6.9GB 我已经附上了最后几行GC日志来指示内存分配 堆PSYoungGen总计1862144K,已使用889367K[0x
-
下面是Broker.xml中artemis集群(3台服务器)的设置 我预计broker3在集群中就应该开始接收请求。