
使用dataframe python以矩阵格式显示列

我有下表
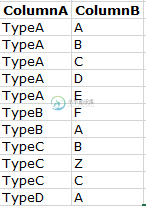
我想使用python将int转换成矩阵,看起来像下面这样:

我能知道从哪里开始吗?我使用pandas读取两个数据帧并合并它们以创建我所显示的初始表(一个有两列)。
我使用的代码如下:
import pandas as pd
from pyexcelerate import Workbook
import numpy as np
import time
start = time.process_time()
excel_file = 'Test.xlsx'
df = pd.read_excel(excel_file, sheet_name=0, index_col=0)
print(df.columns)
print(df.index)
newdf= (df.pivot(index='ColumnB',columns='ColumnA', values='ColumnB'))
myNewDF = newdf.transform(lambda x: np.where(x.isnull(), '', 'yes'))
aftercalc = time.process_time()
print(aftercalc - start)
myNewDF.to_excel("1.xlsx")
print(time.process_time() - aftercalc)
打印输出为:
索引(['列B'], dtype='对象')索引(['TypeA','TypeA','TypeA','TypeA','TypeA','TypeB','TypeB','TypeC','TypeC','TypeD'], dtype='对象', name='列A')
运行此操作时出现的错误是:
Traceback(最近一次调用最后一次):文件"C:_data\学\Minicon da\lib\site-包\熊猫\core\索引\base.py",第2657行,get_loc返回自己。_engine.get_loc(键)文件"熊猫/_libs/index.pyx”,第108行,在熊猫中。_libs.index.IndexEngine.get_loc文件“熊猫/_libs/index.pyx”,第132行,在熊猫中。_libs.index.IndexEngine.get_loc文件"熊猫/_libs/hashtable_class_helper.pxi",第1601行,在熊猫中。_libs.hashtable.PyObjectHashTable.get_item文件"熊猫/_libs/hashtable_class_helper.pxi",第1608行,在熊猫中。_libs.hashtable.PyObjectHashTable.get_item关键错误:'列'
在处理上述异常期间,发生了另一个异常:
回溯(最后一次调用):文件“test.py”,第10行,在newdf=(df.pivot(index='ColumnB',columns='ColumnA',values='ColumnB'))文件“C:_data\learn\Miniconda\lib\site packages\pandas\core\frame.py”,第5628行,在pivot返回pivot(sel,index=index,columns=columns,values=values)文件中“C:_data\learn\Miniconda\lib\site packages\pandas\core\reforme\pivot.py”,pivot index=MultiIndex中的第379行。来自_数组([index,data[columns]])文件“C:_data\learn\Miniconda\lib\site packages\pandas\core\frame.py”,getitem indexer=self.columns.get_loc(key)文件中的第2927行”C:_data\learn\Miniconda\lib\site packages\pandas\core\indexes\base.py”,第2659行,在get_loc return self._engine.get_loc(self._maybe_cast_indexer(key))文件“pandas/_libs/index.pyx”,第108行,在pandas._libs.index.IndexEngine.get_loc文件“pandas/_libs/index.pyx”,第132行,在pandas._libs.index.IndexEngine.IndexEnginepandas/_libs/hashtable_class_helper.pxi”,第1601行,在pandas中。_libs.hashtable.PyObjectHashTable.get_项目文件“pandas/_libs/hashtable_class_helper.pxi”,第1608行,在pandas中。_libs.hashtable.PyObjectHashTable.get_项目
共有2个答案

我们可以做
pd.crosstab(df.ColumnA,df.ColumnB).astype(bool)

这能解决问题吗?
newdf= (df.pivot(index='ColumnB',columns='ColumnA', values='ColumnB'))
newdf
Out[28]:
ColumnA TypeA TypeB TypeC TypeD
ColumnB
A A A NaN A
B B NaN B NaN
C C NaN C NaN
D D NaN NaN NaN
E E NaN NaN NaN
F NaN F NaN NaN
Z NaN NaN Z NaN
newdf.transform(lambda x: np.where(x.isnull(), '', 'yes'))
Out[29]:
ColumnA TypeA TypeB TypeC TypeD
ColumnB
A yes yes yes
B yes yes
C yes yes
D yes
E yes
F yes
Z yes
修改代码
import pandas as pd
#from pyexcelerate import Workbook
import time
import numpy as np
start = time.process_time()
excel_file = 'C:\\Users\\ss\\Desktop\\check.xlsx'
df = pd.read_excel(excel_file, sheet_name=0, index_col=0)
print(df.columns)
print(df.index)
newdf= (df.pivot(index='ColumnB',columns='ColumnA', values='ColumnB'))
myNewDF = newdf.transform(lambda x: np.where(x.isnull(), '', 'yes'))
aftercalc = time.process_time()
print(aftercalc - start)
myNewDF.to_excel("C:\\Users\\ss\\Desktop\\output.xlsx")
-
问题内容: 如何以矩阵框格式打印出简单的int [] [],就像我们在其中手写矩阵的格式那样。简单的循环运行显然无效。如果有帮助,我正在尝试在linux ssh终端中编译此代码。 问题答案: 产生:
-
问题内容: 我在印度编号系统中显示以下代码。 正在获取此输出:。 我需要这样的输出:。 请帮我解决这个问题。 问题答案: 对于整数: 对于浮点数:
-
1.我有一个格式需要在JSP中显示。其中的行应按行显示。 我有一个格式,但不能张贴它的图像,请让我知道如何可以上传的格式。 这些数据应该以相同的格式从数据库中获取。使用arraylist、JSP。 现在我已经试着把我正在尝试的代码,请帮助我的答案,谢谢你提前!!!
-
问题内容: 我有以下情况: 提供输出 Tue May 31 00:00:00 SGT 2019 但我希望输出是 31/05/2019 我需要在这里使用解析,因为日期需要按日期而不是字符串进行排序。 有任何想法吗 ?? 问题答案: 怎么样:
-
请指导我的混淆矩阵的热图显示。我尝试了不同的图大小,但没有得到正确的显示。我的代码如下和屏幕截图
-
问题内容: 如何利用System.out.print(ln/f)一种方式将我的输出格式化为表格? 如果要使用printf,我应该指定哪种格式来获得以下结果? 我要打印的示例表: ``` n result1 result2 time1 time2 5 1000.00 20000.0 1000ms 1250ms 5 1000.00 20000.0 1000ms 1250ms 5 1000.00 200