
为什么使用nltk的斯坦福解析器不能正确解析句子?

我在python中使用带有nltd k的Stanford解析器,并得到Stanford Parser和NLTK的帮助来建立Stanford nlp库。
from nltk.parse.stanford import StanfordParser
from nltk.parse.stanford import StanfordDependencyParser
parser = StanfordParser(model_path="edu/stanford/nlp/models/lexparser/englishPCFG.ser.gz")
dep_parser = StanfordDependencyParser(model_path="edu/stanford/nlp/models/lexparser/englishPCFG.ser.gz")
one = ("John sees Bill")
parsed_Sentence = parser.raw_parse(one)
# GUI
for line in parsed_Sentence:
print line
line.draw()
parsed_Sentence = [parse.tree() for parse in dep_parser.raw_parse(one)]
print parsed_Sentence
# GUI
for line in parsed_Sentence:
print line
line.draw()
我得到了错误的解析和依赖树,如下例所示,它将“看到”视为名词而不是动词。
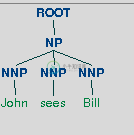
我该怎么办?当我改变句子时,它完全正确。这个句子的正确输出可以从这里查看解析树的正确输出
正确输出的示例如下所示:


共有1个答案

同样,没有模型是完美的(参见Python NLTKpos_tag没有返回正确的词性标签);P
您可以使用NeuralDependencyParser尝试“更精确”的解析器。
首先使用正确的环境变量正确设置解析器(请参阅Stanford Parser和NLTK和https://gist.github.com/alvations/e1df0ba227e542955a8a),然后:
>>> from nltk.internals import find_jars_within_path
>>> from nltk.parse.stanford import StanfordNeuralDependencyParser
>>> parser = StanfordNeuralDependencyParser(model_path="edu/stanford/nlp/models/parser/nndep/english_UD.gz")
>>> stanford_dir = parser._classpath[0].rpartition('/')[0]
>>> slf4j_jar = stanford_dir + '/slf4j-api.jar'
>>> parser._classpath = list(parser._classpath) + [slf4j_jar]
>>> parser.java_options = '-mx5000m'
>>> sent = "John sees Bill"
>>> [parse.tree() for parse in parser.raw_parse(sent)]
[Tree('sees', ['John', 'Bill'])]
请注意,NeuralDependencyParser只生成依赖关系树:
-
问题内容: 如何使用Stanford解析器将文本或段落拆分为句子? 有没有可以提取句子的方法(例如为Ruby提供的方法)? 问题答案: 您可以检查DocumentPreprocessor类。以下是一个简短的摘要。我认为可能还有其他方式可以做您想要的事情。
-
如果我从主页上举个例子: 斯坦福解析器: 交付下面的树: 我现在想拆分依赖于其结构的树以获取子句。所以在这个例子中,我想拆分树以获得以下部分: 印度有史以来最强的降雨 最强的降雨导致孟买金融中心关闭 最强的雨切断了通讯线路 最强降雨导致机场关闭 大雨迫使数千人睡在办公室 强降雨迫使数千人在夜间步行回家 所以第一个答案是使用递归算法打印所有根到叶的路径。 以下是我尝试过的代码: 当然,这段代码完全不
-
Technik NN Technik O kann VMFIN kann O 耶多克ADV耶多克O 我使用的是以下德国模型:Stanford-German-Corenlp-2018-02-27-models.jar 根据自述文件,coreNLP工具的版本是“2018-02-27 3.9.1” java版本“10.0.1”2018-04-17
-
问题内容: 我一直在搜索,只是找不到解释或原因,但DateFormat的parse(String)方法只是不能正确解析我的String。 我正在尝试将String解析为用于HTTP标头的日期格式,并尽可能地获取String,例如: 格式为: 但是,当我使用它时,我会从中得到: 哪一个都不像我想要的,为什么现在格林尼治标准时间之后的一年?为什么不再有逗号?为什么日期在一个月之后? 我现在对此完全感到
-
我有字符串格式的日期,我想解析成使用日期。 我将其解析为: 但奇怪的是,如果我通过"03-08-201309hjhkjhk"或"03-88-2013"或43-88-201378",它不会抛出错误,它会解析它。 现在,我必须编写正则表达式模式来检查日期的输入是否正确。但为什么会这样呢?? 代码:
-
我正在注释和分析一系列文本文件。 pipeline.annotate方法每次读取文件时都会变得越来越慢。最终,我得到了一个OutOfMemoryError。 管道初始化一次: 然后,我使用相同的管道实例处理每个文件(如SO和斯坦福大学在其他地方推荐的)。 明确地说,我希望问题出在我的配置上。但是,我确信失速和内存问题发生在pipeline.annotate(file)方法上。 在处理每个文件后,我