
在AWS EMR上运行WordCount示例映射缩减

我试图在AWS EMR上运行字数计数示例,但是我很难在集群上部署和运行jar。它是一个自定义的字数示例,其中我使用了一些JSON解析。输入在我的S3桶中。当我试图在EMR集群上运行我的工作时,我得到的错误是在我的Mapper类中找不到主函数。在互联网上的任何地方,字数计数示例映射减少作业的代码就像他们创建的,三个类,一个扩展Mapper的静态映射器类,然后是扩展减少器的减少器,然后是包含作业配置的主类,所以我是不知道为什么我看到了错误。我使用maven汇编插件构建代码,以便在我的JAR中包装所有第三方依赖项。这是我写的代码
package com.amalwa.hadoop.MapReduce;
import java.io.IOException;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
import java.util.HashMap;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import com.google.gson.Gson;
public class ETL{
public static void main(String[] args) throws Exception{
if (args.length < 2) {
System.err.println("Usage: ETL <input path> <output path>");
System.exit(-1);
}
Configuration conf = new Configuration();
Job job = new Job(conf, "etl");
job.setJarByClass(ETL.class);
job.setMapperClass(JsonParserMapper.class);
job.setReducerClass(JsonParserReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(TweetArray.class);
FileInputFormat.addInputPath(job, new Path(args[1]));
FileOutputFormat.setOutputPath(job, new Path(args[2]));
job.waitForCompletion(true);
}
public static class JsonParserMapper extends Mapper<LongWritable, Text, Text, Text>{
private Text mapperKey = null;
private Text mapperValue = null;
Date filterDate = getDate("Sun Apr 20 00:00:00 +0000 2014");
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String jsonString = value.toString();
if(!jsonString.isEmpty()){
@SuppressWarnings("unchecked")
Map<String, Object> tweetData = new Gson().fromJson(jsonString, HashMap.class);
Date timeStamp = getDate(tweetData.get("created_at").toString());
if(timeStamp.after(filterDate)){
@SuppressWarnings("unchecked")
com.google.gson.internal.LinkedTreeMap<String, Object> userData = (com.google.gson.internal.LinkedTreeMap<String, Object>) tweetData.get("user");
mapperKey = new Text(userData.get("id_str") + "~" + tweetData.get("created_at").toString());
mapperValue = new Text(tweetData.get("text").toString() + " tweetId = " + tweetData.get("id_str"));
context.write(mapperKey, mapperValue);
}
}
}
public Date getDate(String timeStamp){
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("E MMM dd HH:mm:ss Z yyyy");
Date date = null;
try {
date = simpleDateFormat.parse(timeStamp);
} catch (ParseException e) {
e.printStackTrace();
}
return date;
}
}
public static class JsonParserReducer extends Reducer<Text, Text, Text, TweetArray> {
private ArrayList<Text> tweetList = new ArrayList<Text>();
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for (Text val : values) {
tweetList.add(new Text(val.toString()));
}
context.write(key, new TweetArray(Text.class, tweetList.toArray(new Text[tweetList.size()])));
}
}
}
如果有人能澄清这个问题,那就太好了。我已经在我安装了hadoop的本地机器上部署了这个jar,它工作正常,但是当我使用AWS设置我的集群并为流媒体作业提供所有参数时,它就不工作了。下面是我的配置截图:
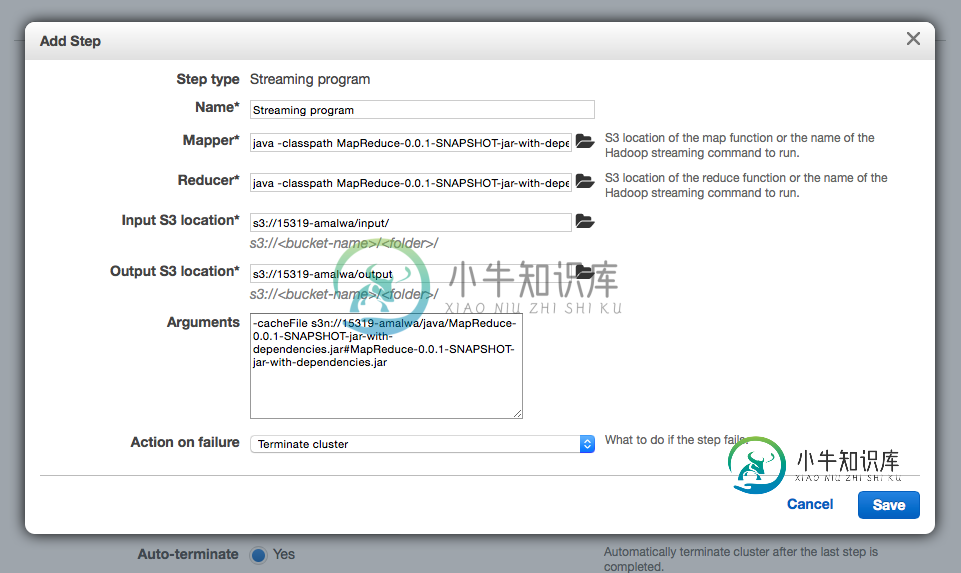
The Mapper textbox is set to: java -classpath MapReduce-0.0.1-SNAPSHOT-jar-with-dependencies.jar com.amalwa.hadoop.MapReduce.JsonParserMapper
The Reducer textbox is set to: java -classpath MapReduce-0.0.1-SNAPSHOT-jar-with-dependencies.jar com.amalwa.hadoop.MapReduce.JsonParserReducer
谢谢和问候。
共有2个答案

在创建jar文件时(我通常使用Eclipse或自定义gradle构建),检查主类是否设置为ETL。显然,默认情况下不会发生这种情况。还要检查您在ur系统上使用的Java版本。我认为aws emr可以使用高达Java7的版本。

您需要选择自定义jar步骤,而不是流式程序。
-
我正在VMware中Ubuntu12.04的单节点环境中运行hadoop wordcount示例。我运行的示例是这样的:-- 当我运行wordcount程序时,我得到以下错误:--
-
我正在尝试运行WordCount Map/Reduce作业的示例代码。我正在Hadoop1.2.1上运行它。我用我的日食来运行它。下面是我尝试运行的代码: 13/11/04 13:27:53 INFO Mapred.JobClient:任务Id:Attitt_201310311611_0005_M_000000_0,状态:失败java.lang.RuntimeException:java.lang
-
我试图在Hadoop 1.0.4和Ubuntu 12.04上用C++运行wordcount示例,但我得到以下错误: 错误消息: 13/06/14 13:50:11警告Mapred.JobClient:未设置作业jar文件。可能找不到用户类。请参阅JobConf(Class)或JobConf#setjar(String)。13/06/14 13:50:11 INFO util.NativEcodeL
-
我想我在文档上遵循了非常多的步骤,但我仍然遇到了这个异常。(唯一的不同是我从Eclipse J2EE运行它,但我不会期望这真的很重要,不是吗?) 代码:(这不是我写的,它来自梁项目示例)。我认为您必须指定一个google云平台项目,并提供访问该项目的正确凭据。然而,在这个示例项目中,我没有找到进行设置的地方。 例外情况: