
Amazon RDS:用户“master”与MySQL服务器的连接尝试失败

我无法连接到我创建的MySQL Amazon RDS实例。
我正在按照AWS RDS教程进行连接并进入:
- 工作台上“主机”中的endpoint
- 包括用户名和密码的凭据
- 端口设置为3306
我得到了一个错误:
无法连接到数据库服务器
您尝试将用户“master”连接到xxxx的MySQL服务器失败。rds。亚马逊。com:3306:
无法连接到xxxx上的MySQL服务器。亚马逊。com'(10060)
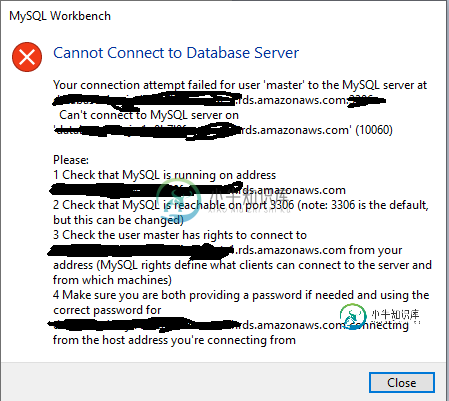
共有1个答案

检查事项:
- 由于您是从Internet连接的,因此必须在公共子网中启动亚马逊RDS数据库
-
问题内容: 环境文件: Routes.php: 我得到的错误: *Connector.php第55行中的 *PDOException : SQLSTATE [HY000] [2002]连接尝试失败,因为一段时间后连接方未正确响应,或者由于连接的主机未能响应,所以建立的连接失败。 我的问题是: 我正在尝试从计算机连接到远程MySQL服务器 而且我不明白为什么它不起作用? 我应该怎么做才能连接? 我想
-
首先,我需要指出我在我的机器上运行了Wikipedia转储的sql文件,为了能够运行,我需要更新许多关于内存中可用索引大小的设置和一些其他设置。我只想提到那些大型sql查询运行成功,在内存或超时方面没有任何问题。 现在我有了一个表pagelinks(pl_from,pl_title),它显示了出现在每个维基百科页面中的链接,例如,数据可以是(1,“title1”),(1,“title2”),(2,
-
重启MySQL后丢失Wildfly连接 我们使用2个版本MySQL版本14.14发行版5.6.51,Linux(x86_64)使用EditLine包装和MySQL版本8.0.28Linuxx86_64(MySQL社区服务器-GPL) 我们尝试了两个版本的Wildfly Wildfly-10.1.0。最终版本和wildfly-19.1.0。最终的 我们使用了JDBC数据库连接器版本is-8.0.19
-
问题内容: 这个问题已经在这里有了答案 : 7年前关闭。 可能重复: 查询期间失去与MySQL服务器的连接 我正在将一些数据从大型csv导入mysql表。在将文件导入到表的过程中,我丢失了与服务器的连接。 怎么了? 错误代码为2013:在查询过程中失去与mySql服务器的连接。 我正在从Windows服务器上的ubuntu机器远程运行这些查询。 问题答案: 我发现此问题的最简单解决方案是将MySq
-
我已经启动了spark-thrift服务器,并使用Beeline连接到thrift服务器。当尝试查询时,创建一个表在hive转移,我得到以下错误。 cassandra不是有效的Spark SQL数据源。 0:jdbc:hive2:/localhost:10000>select*from traveldata.employee_details;