
为什么ANTLR语法文件中类似的规则会产生完全不同的树?

我在https://github.com/antlr/grammars-v4/blob/master/sql/tsql/TSqlParser.g4.使用语法文件它有一个built_in_functions语法规则。我想解析一个新函数DAYZ作为内置函数。我在. g4中这样介绍了它
built_in_functions
// https://msdn.microsoft.com/en-us/library/ms173784.aspx
: BINARY_CHECKSUM '(' '*' ')' #BINARY_CHECKSUM
// https://msdn.microsoft.com/en-us/library/ms186819.aspx
| DATEADD '(' datepart=ID ',' number=expression ',' date=expression ')' #DATEADD
| DAYZ '(' date=expression ')' #DAYZ

对于DAYZ,我得到以下树
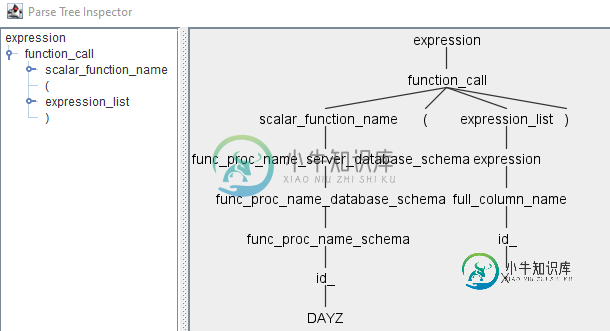
为什么解析器不像对待DATEDIFF那样将DAYZ视为满足规则built_in_functions?如果解析器最终将DAYZ识别为_Id,它应该对DATEDIFF做同样的事情。我将DAYZ引入语法的方式一定有问题,但我无法弄清楚。感谢任何帮助。如果我没有使用正确的ANTLR术语,请道歉。我是ANTLR的新手。我正在使用antlr-4.9.2-complete.jar
共有1个答案

将DAYZ的lexer规则移动到TSqlLexer. g4文件中的ID规则之前。
由于id_u规则识别令牌,因此必须将其标记为id令牌。如果DAYZ规则定义在ID规则定义之后,就会发生这种情况。
当ANTLR找到两个与同一输入字符字符串(即“DAYZ”)匹配的词法分析器规则时,它将使用语法中首先出现的规则。
-
我得到了这个解析器语法,我还想用它来使用类似于Javascript模板的东西-字符串。 这个lexer语法 我不明白,为什么甚至可以匹配一些像空映射或像“world`”这样的映射,因为映射需要在中间有一个“:”。并且为什么规则模板字符串不匹配整个“Hello World”从一个滴答到另一个滴答? 编辑: 当我注意到Lexer没有被重新生成时,我得到了这样的错误:“不能为string literal
-
ANTLR语法中解析器和词法分析器规则的调用顺序是什么?例如,在以下语法中,输入 223 始终标识为APLHANUMERIC而不是数字
-
我有一个antlr语法,它有多个与同一个单词匹配的词法规则。在词法分析过程中无法解决这个问题,但通过语法,它就变得毫不含糊了。 示例: 输入:<代码>1英寸(米) 单词“in”与lexer规则和匹配。 如何在保持语法文件可读性的同时解决此问题?
-
正如维基百科关于解析的文章所指出的,这个过程有三个阶段: null 除了上面阶段(3)中的小困惑之外,我想验证我对ECMAScript过程的理解是否正确。 那么,下面的流程是正确的吗? 输入:Unicode码点流<--词法中的终端符号 输出:有效标记<--词法语法中的非终结符号 语法应用 分析每个Unicode码点(字符),每次一个 通过应用适当的产生式规则,将最长的终端符号序列替换为非终端符号
-
注意:这是一个自我回答的问题,旨在提供一个关于ANTLR用户最常见的错误之一的参考。 当我测试这个非常简单的语法时: 在这种情况下,ANTLR为什么不将识别为? 它应该很好地匹配模式。 如果我颠倒定义和的顺序,这似乎是可行的,但为什么顺序首先重要呢?
-
查看文档,ANTLR2过去有一种叫做谓词法的东西,下面的例子是这样的(灵感来自Pascal): 在我看来,这实际上是规则开头的一个积极的前瞻性断言:如果前瞻性与匹配,那么第一个规则将被应用(并与该输入的部分匹配),依此类推。 我还没有在ANTLR4中找到这样的东西。2到3迁移指南似乎没有提到这一点,而3到4更改文档指出: ANTLR3和4之间最大的区别是ANTLR4接受您给出的任何语法,除非该语法