
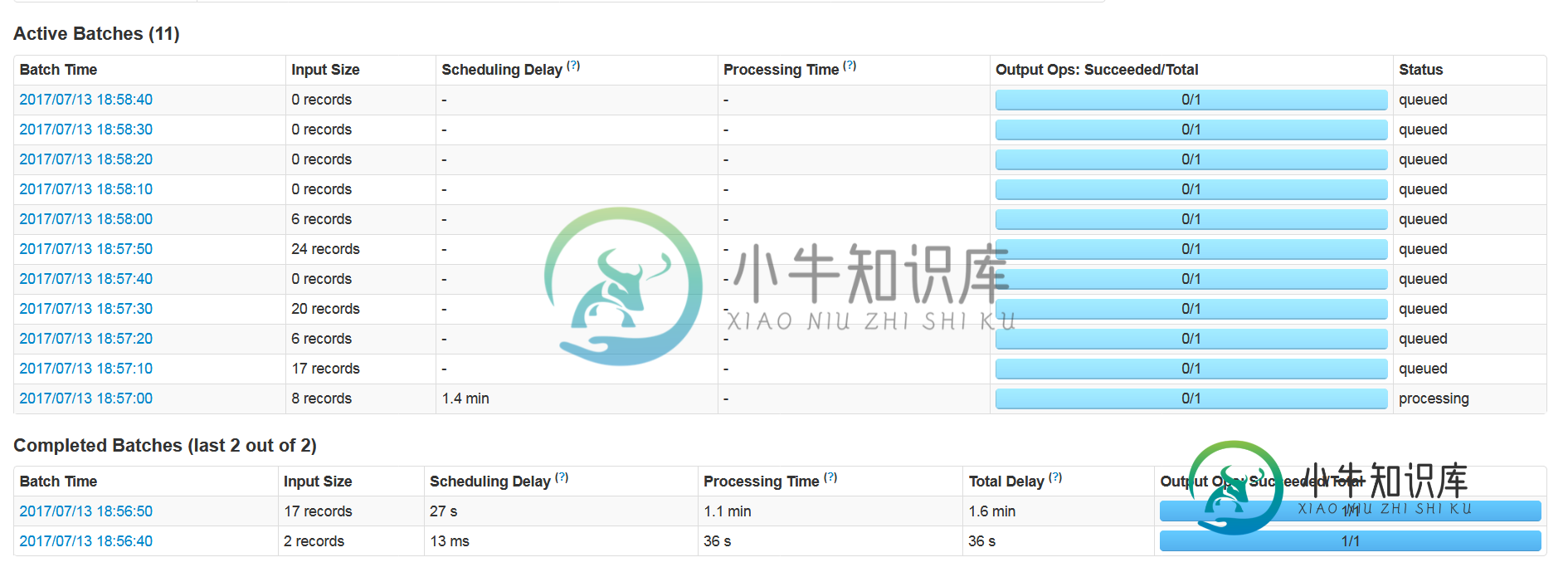
Spark Streaming:微批并行执行

我们正在接收来自Kafka的星火流数据。一旦在Spark Streaming中开始执行,它只执行一个批处理,其余的批处理开始在Kafka中排队。
我们的数据是独立的,可以并行处理。
我们尝试了多个配置,有多个执行器,核心,背压和其他配置,但到目前为止没有任何工作。排队的消息很多,每次只处理一个微批处理,其余的都留在队列中。
// Start reading messages from Kafka and get DStream
final JavaInputDStream<ConsumerRecord<String, byte[]>> consumerStream = KafkaUtils.createDirectStream(
getJavaStreamingContext(), LocationStrategies.PreferConsistent(),
ConsumerStrategies.<String, byte[]>Subscribe("TOPIC_NAME",
sparkServiceConf.getKafkaConsumeParams()));
ThreadContext.put(Constants.CommonLiterals.LOGGER_UID_VAR, CommonUtils.loggerUniqueId());
JavaDStream<byte[]> messagesStream = consumerStream.map(new Function<ConsumerRecord<String, byte[]>, byte[]>() {
private static final long serialVersionUID = 1L;
@Override
public byte[] call(ConsumerRecord<String, byte[]> kafkaRecord) throws Exception {
return kafkaRecord.value();
}
});
// Decode each binary message and generate JSON array
JavaDStream<String> decodedStream = messagesStream.map(new Function<byte[], String>() {
private static final long serialVersionUID = 1L;
@Override
public String call(byte[] asn1Data) throws Exception {
if(asn1Data.length > 0) {
try (InputStream inputStream = new ByteArrayInputStream(asn1Data);
Writer writer = new StringWriter(); ) {
ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(asn1Data);
GZIPInputStream gzipInputStream = new GZIPInputStream(byteArrayInputStream);
byte[] buffer = new byte[1024];
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
int len;
while((len = gzipInputStream.read(buffer)) != -1) {
byteArrayOutputStream.write(buffer, 0, len);
}
return new String(byteArrayOutputStream.toByteArray());
} catch (Exception e) {
//
producer.flush();
throw e;
}
}
return null;
}
});
// publish generated json gzip to kafka
cache.foreachRDD(new VoidFunction<JavaRDD<String>>() {
private static final long serialVersionUID = 1L;
@Override
public void call(JavaRDD<String> jsonRdd4DF) throws Exception {
//Dataset<Row> json = sparkSession.read().json(jsonRdd4DF);
if(!jsonRdd4DF.isEmpty()) {
//JavaRDD<String> jsonRddDF = getJavaSparkContext().parallelize(jsonRdd4DF.collect());
Dataset<Row> json = sparkSession.read().json(jsonRdd4DF);
SparkAIRMainJsonProcessor airMainJsonProcessor = new SparkAIRMainJsonProcessor();
airMainJsonProcessor.processAIRData(json, sparkSession);
}
}
});
getJavaStreamingContext().start();
getJavaStreamingContext().awaitTermination();
getJavaStreamingContext().stop();
HDFS 2.7.1.2.5
YARN + MapReduce2 2.7.1.2.5
ZooKeeper 3.4.6.2.5
Ambari Infra 0.1.0
Ambari Metrics 0.1.0
Kafka 0.10.0.2.5
Knox 0.9.0.2.5
Ranger 0.6.0.2.5
Ranger KMS 0.6.0.2.5
SmartSense 1.3.0.0-1
Spark2 2.0.x.2.5
我们从差异实验中得到的统计数据:
实验1
num_executors=6
executor_memory=8g
executor_cores=12
100个文件处理时间48分钟
spark.default.parallelism=12
num_executors=6
executor_memory=8g
executor_cores=12
spark.default.parallelism=12
num_executors=6
executor_memory=8g
executor_cores=12
spark.default.parallelism=16
num_executors=6
executor_memory=8g
executor_cores=12
100个文件处理时间10分钟
请告知,我们如何处理最大值,所以没有排队。
共有1个答案

我也面临着同样的问题,我尝试了一些事情来解决这个问题,并得出了以下结论:
首先。直觉认为每个执行者必须处理一个批处理,但相反,一次只处理一个批处理,但作业和任务是并行处理的。
可以通过使用spark.streaming.concurrentJobs来实现多批处理,但它没有文档化,仍然需要一些修复。问题之一是如何保存Kafka偏移。假设我们将此参数设置为4,并且并行处理4个批处理,如果第3个批处理在第4个批处理之前完成,那么将提交Kafka偏移量。如果批处理是独立的,则此参数非常有用。
-
1.3 新版功能. 默认情况下,Fabric 会默认 顺序 执行所有任务(详细信息参见 Execution strategy ),这篇文档将介绍 Fabric 如何在多个主机上 并行 执行任务,包括 Fabric 参数设置、任务独立的装饰器,以及命令行全局控制。 它是如何运转的 由于 Fabric 1.x 并不是完全线程安全(以及为了更加通用,任务函数之间并不会产生交互),该功能的实现是基于 Py
-
:) 我已经在一个(奇怪的)情况中结束了自己,简单地说,我不想使用来自Kafka的任何新记录,因此暂停主题中所有分区的sparkStreaming消费(InputStream[ConsumerRecord]),执行一些操作,最后,恢复消费记录。 首先这可能吗? 我一直在尝试这样的事情: 但是我得到了这个: 任何帮助我理解我遗漏了什么,以及为什么当消费者明确分配了分区时我会得到空结果的帮助都将受到欢
-
我有4个@Test方法,希望每个方法都运行3次。我想在12个线程中同时执行所有这些。 我创建了一个testng。像这样的xml文件 如果我设置并行="方法",TestNG在Test1的4个线程中执行4个测试方法,之后对Test2执行相同的操作,然后对Test3执行相同的操作。但是我不想在运行Test2之前等待Test1完成。TestNG能够运行Test1、Test2 有没有办法告诉TestNG不要
-
以我的经验,一提到并发执行,90%的人都会提到线程,的确这玩意用的很广泛,综合来说各方面都还可以。虽然很多语言都内置了线程库,C++11也有了,但严格来说线程是跟操作系统相关,具体说,如果操作系统支持线程,则语言的线程库简单封装下就可以了,如果操作系统不支持(如一些unix系统),那就比较麻烦了,简单的可以去掉线程库,或接口返回异常,复杂的可能自己实现一个用户态的线程机制 一个语言实现中如果要用到
-
本文向大家介绍Python实现ssh批量登录并执行命令,包括了Python实现ssh批量登录并执行命令的使用技巧和注意事项,需要的朋友参考一下 局域网内有一百多台电脑,全部都是linux操作系统,所有电脑配置相同,系统完全相同(包括用户名和密码),ip地址是自动分配的。现在有个任务是在这些电脑上执行某些命令,者说进行某些操作,比如安装某些软件,拷贝某些文件,批量关机等。如果一台一台得手工去操作,费
-
那么我需要按照以下方式处理这些消息: 在每个消息上应用一个(couple of)函数,输出 应在消息上应用一个函数,其中 (稍后有一个传递,需要“转置”消息以跨所有a处理,但这不是这里的问题) 我如何实现这样的消息合并,从步骤1到步骤2? 它看起来像是子键上的groupby,但据我所知,方法groupby将在每个微批处理中应用。我需要的是,对于每个,等待接收到所有(假设一个简单的计数系统可以工作)