
为什么我的Kafka留言都在暴风里重播?

我试图弄清楚为什么每次我重新启动我的Storm拓扑时,我所有的Kafka消息都被重播。
我的理解是,一旦最后一个Bolt对元组进行了处理,spout就应该在Kafka上提交消息,因此在重新启动后我不应该看到它的重播。
我的代码是一个简单的Kafka喷口和一个螺栓,只是打印每一个消息,然后处理他们。
private static KafkaSpout buildKafkaSpout(String topicName) {
ZkHosts zkHosts = new ZkHosts("localhost:2181");
SpoutConfig spoutConfig = new SpoutConfig(zkHosts,
topicName,
"/" + topicName,
"mykafkaspout"); /*was:UUID.randomUUID().toString()*/
spoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme());
return new KafkaSpout(spoutConfig);
}
public static class PrintBolt extends BaseRichBolt {
OutputCollector _collector;
public static Logger LOG = LoggerFactory.getLogger(PrintBolt.class);
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
_collector = collector;
}
@Override
public void execute(Tuple tuple) {
LOG.error("PrintBolt.0: {}",tuple.getString(0));
_collector.ack(tuple);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("nothing"));
}
}
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("kafka", buildKafkaSpout("mytopic"), 1);
builder.setBolt("print1", new PrintBolt(),1).shuffleGrouping("kafka");
}
澄清一下,在我重新启动管道之前一切正常。下面的行为是我可以在其他(非Storm)消费者身上得到的,也是我期望从KafkaSpout身上得到的
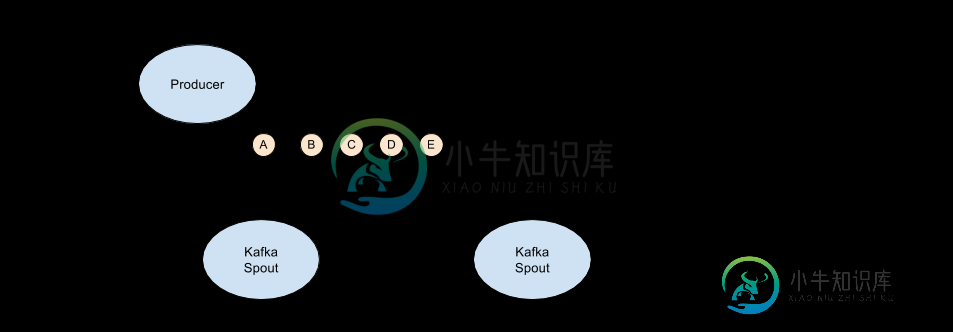
然而,Im使用默认设置获得的实际行为如下所示。消息被处理得很好,直到我停止管道,然后当我重新启动时,我得到了所有消息的重播,包括那些(a和B)我认为我已经处理过的消息
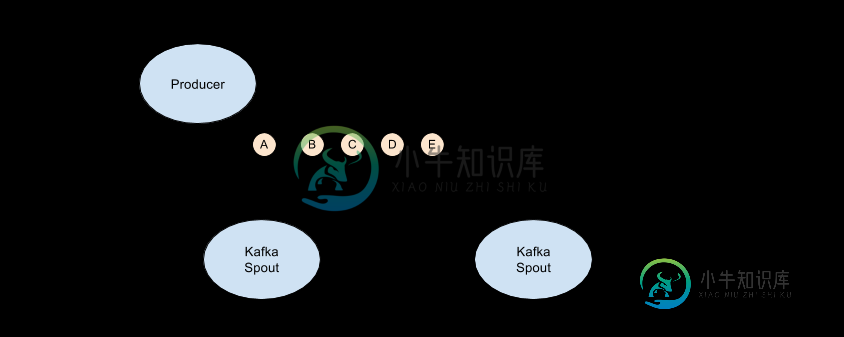
根据Matthias提到的配置选项,我可以将startoffsettime更改为latest,但这实际上是管道丢弃重新启动时产生的消息(消息“C”)的最新位置。

共有1个答案

问题出现在提交代码中--如果Storm JAR在没有拓扑名称的情况下运行,并且本地集群没有捕获状态,因此没有重播,那么用于提交拓扑的模板代码将创建LocalCluster的实例。
所以
$ storm jar myjar.jar storm.myorg.MyTopology topologyname
我将在我的单节点开发集群上启动它,其中
$ storm jar myjar.jar storm.myorg.MyTopology
-
spark作业提交到minicube创建的kubernetes集群中的spark集群后的输出: 来自spark web ui的信息: 我的文件中的foreachRDD。scala:49详细信息 组织。阿帕奇。火花流动。数据流。数据流。foreachRDD(DStream.scala:625)myfile。运行(myfile.scala:49)Myjob$。main(Myjob.scala:100)
-
谢谢你抽出时间。 通过在每个分区上使用数据进行泛洪测试,完成读取需要。 再次使用parallelism_hint=1的代码 即 其中, parallelism_hint-是应该分配给执行此spout的任务数。每个任务将在集群周围某个进程的线程上运行。
-
我试图使Kafka消费者同步消费Kafka的消息。 我遇到的实际问题是消息队列存储在Storm Spout中。 我想做的是让暴风雪等待Kafka的回复,然后让暴风雪消耗下一条信息。 我正在使用Storm KafkaSpout: 我已经更新到Storm 2.0.0,我使用Storm kafka客户端。但是如果我将Storm队列配置为50:
-
测试代码为: 测试代码为: 你知道怎么了吗?
-
我遇到JSON解析错误。我的代码如下: 我从我的检查中得到以下错误: 由于:com,无法分析JSON。谷歌。格森。JsonSyntaxException:java。lang.IllegalStateException:应为BEGIN\u对象,但在第1行第2列为BEGIN\u数组 对于我试图读取的JSON,如果成功,我的应该返回5。 我做错了什么?
-
我知道,storm并不能保证kafka主题的总体订购保证,但在许多文档中,storm保证消费/处理消息,并在分区级别维护订单。 我正在寻找一个示例storm拓扑,它使用/处理kafka主题的消息,在kafka分区级别维护消息的顺序。。不是全部订单!!只有分区级别的排序保证。 如果您知道任何示例应用程序,请分享。非常感谢!!