
为什么使用Browserify后仍然包含依赖关系文件

全部:
我对Gulp和Browserify相当陌生,我所做的是转换一些jsx代码并将它们Browserify到一个bundle.js文件中。
var gulp = require("gulp");
var browserify = require("browserify");
var source = require("vinyl-source-stream");
var reactify = require("reactify");
gulp.task("default", function(){
browserify({
entries: ["js/app.js"],
debug: true
})
.transform(reactify)
.bundle()
.pipe(source("bundle.js"))
.pipe(gulp.dest("dist/js/"));
});
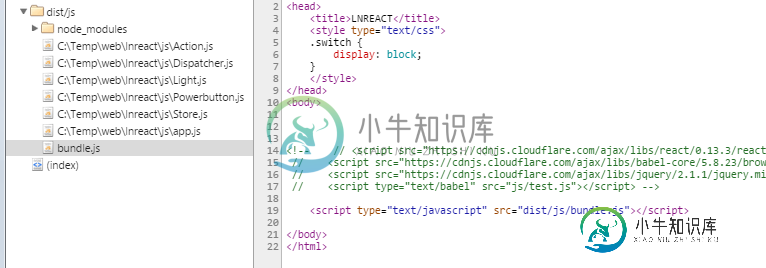
在app.js中,我指定了一些必需依赖项(每个依赖项可能需要一些其他文件),我以为browserify会解析它们并编译成一个bundle.js文件,但当我运行它时,即使我只在index.html页面中包含bundle.js,当我在Chrome source选项卡中查看时,它仍然包含所有那些依赖文件,我想这是Chrome解析bundle文件的特性给我一个依赖文件列表还是它实际上也下载了那些依赖文件(我的困惑是我实际上可以点击并打开那些依赖文件,所以我猜Chrome用bundle.js下载它们,但我不确定)?
谢谢
共有1个答案

如果我没理解错的话,您描述的是browserify中的debug:true提供的内容,也就是源映射。
--debug-d启用源映射,允许您单独调试文件。
而且
当opts.debug为true时,向包的末尾内联添加源映射。这使得调试更容易,因为如果您在一个足够现代的浏览器中,您可以看到所有原始文件。
-
问题内容: 我想分析Python包的依赖树。我如何获得这些数据? 我已经知道的事情 有时包含一个列出软件包依赖关系的字段 PyPi是Python软件包的在线存储库 PyPi有一个API 我不知道的事情 PyPi上很少有项目(大约10%)在该字段中明确列出依赖项,但仍设法下载正确的软件包。我想念什么?例如,对于统计计算的通俗图书馆,,不会列出,但仍设法安装,等....有没有一种更好的方式自动收集依赖
-
我们刚刚升级到的新版本的Spring Boot和liquibase自动配置给我们带来了一些问题,它失败了,因为它正在寻找一个不存在的liquibase文件来加载,我们过去已经使用我们自己编写的运行程序完成了liquibase配置,这些运行程序使用了不同的结构。 无论如何,有一些潜在的修复方法,其中之一是简单地禁用liquibaseAutoConfiguration类的运行。我不认为我们需要 bea
-
问题内容: 为什么我应该(或不应该)将gradle依赖项包含为, 有什么好处/缺点? 如您所见,我在支持它的下面的库中添加了@aar。但是一切似乎都还没有做完… 问题答案: 在大多数情况下,您可以使用或上载多种格式的库。 如果不指定后缀,则将以其默认格式(由作者定义,如果不是,则以默认格式)以及所有依赖项下载该库。 指定后缀时,将强制以指定的格式(可能存在或可能不存在)下载库。这很有用,例如当作者
-
我有一个漂亮的BOM,它的依赖管理部分有很多依赖项,我想创建另一个BOM来导入除一个之外的所有依赖项。我尝试这样做: POM在形式上是正确的,一切都可以编译。但是排除被简单地忽略了。我错过了什么?这种方法正确吗? 我正在使用Maven 3。
-
下面是我的代码: 和控制台输出以下内容: 我以为使用toString可以去掉[],为什么它还在那里? 编辑:如果toString不是摆脱[]的正确方法,那么正确的方法是什么?
-
编写的PHP扩展需要需要依赖另外一个扩展,在PHP-X中可以调用Extension->require来实现。 PHPX_EXTENSION() { Extension *ext = new Extension("test", "0.0.1"); ext->require("swoole"); ext->require("sockets"); return ext;