
使用Jsoup解析表元素

我试图从这个表中解析数据。例如,假设我想解析第二行中的第二个元素(称为SLO)。
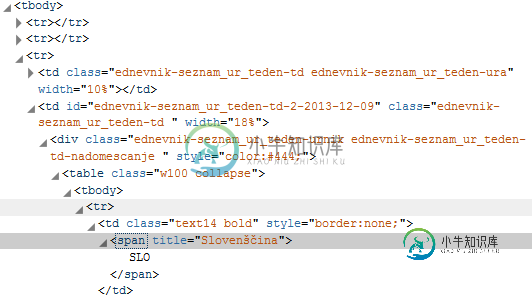
我可以看到TR里面有一个TR,而SLO这个词甚至没有ID或任何东西。我如何解析这个?
这是代码:
class Title extends AsyncTask<Void, Void, Void> {
@Override
protected void onPreExecute() {
super.onPreExecute();
tw1.setText("Loading...");
}
@Override
protected Void doInBackground(Void... params) {
try {
Document doc = Jsoup.connect("https://www.easistent.com/urniki/cc45c5d0d303f954588402a186f5cdba5edb51d6/razredi/16515").get();
Elements eles = doc.select("");
title = eles.toString();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return null;
}
@Override
protected void onPostExecute(Void result) {
super.onPostExecute(result);
tw1.setText(title);
}
}
我不知道在文档中放什么。选择(“”);因为我从未解析过这样的东西。我只解析过网页标题之类的东西。有人能帮我吗?
共有1个答案

这里有很多信息供您使用,例如类名或标题属性。您提供的URL不适用于我,我无法从您的图像复制粘贴HTML,因此我的示例将仅显示基于其标题的跨度解析:
String html = "<span title='Slovenscina'>SLO</span>";
Document doc = Jsoup.parse(html);
Elements eles = doc.select("span[title=Slovenscina]");
String title = eles.text();
System.out.println(title);
将输出:
SLO
这将在您提供的其他HTML的范围内工作。我建议您阅读更多关于Jsoup选择器语法的内容。
-
这是我试图解析的html: 我想得到
-
我想解析一个HTML表,但我不明白如何获得值。我有这张桌子: 你能为我杀一儆百吗?我要分析此表得所有值...提前谢谢! 编辑:SPAN值:
-
我是jsoup的新手,在使用非HTML元素(脚本)时遇到了一些困难。我有以下HTML: 用于显示这一点的应用程序知道如何处理 和.语句。因此,当我简单地用jsoup解析文本时,<和>被编码,html被重新组织,所以它不能正确地执行或显示。例如: 我的最终目标是添加一些css和js包含,并修改几个元素属性。那真的不是问题,我已经解决了那么多了。问题是我不知道如何保留非HTML元素,并将格式与原始格式
-
问题内容: 我正在尝试使用jsoup解析HTML。这是我第一次使用jsoup,并且我也阅读了有关它的一些教程。以下是我要解析的HTML表- 如果您看到我的下表,则它现在有3个(我只是为了理解目的将其缩短为3个表行,但总的来说会更多)。现在,我想从我的下表中提取出它的对应信息,例如-我将提取其群集状态及其状态为关闭的所有主机名。 正如你可以看到下面的群集名称,我有两个主机名和其地位,但地位。 因此,
-
正如您在下面看到的集群名称,我有两个主机名和,其中状态为,但状态为。 因此,我将打印作为集群名,并打印作为主机名,因为它已关闭。使用JSOUP可以做到这一点吗? 到目前为止,我能够使用jsoup提取整个HTML表,但不确定如何提取集群名和主机名- 更新:- 表中可能有两个集群名称,如下所示- 现在,如果您看到上面,我有两个集群名称--一个是,另一个是,所以我想找到所有仅为集群名称关闭的计算机。
-
我知道在解析HTML表方面有很多问题。然而,在做了一些研究并研究了Jsoup之后,我有点被它难倒了。 我有时间表 我想解析以取出标记的文本,但要保持某种格式。 我更愿意将数据分割成可管理的块。也许我可以做一个? 但是,这意味着没有演讲时间。除非不需要计算空格和计算时间,假设每个空格是15分钟。