
带有非紧凑字符串的Java紧凑字符串equalsIgnoreCase计算结果为false

在解析.csv文件时,我会遍历文件的列标题,看看其中一个是否等于(忽略大小写)compare和ID:
String comparand = "id";
for (String header : headerMap.keySet()) {
if (header.equalsIgnoreCase(comparand)) {
recordMap.put("_id", csvRecord.get(header));
} else {
recordMap.put(header, csvRecord.get(header));
}
}
使用UTF-8字符集读取该文件:
Reader reader = new InputStreamReader(file.getInputStream(), StandardCharsets.UTF_8);
CSVParser csvParser = CSVFormat.DEFAULT
.withDelimiter(delimiter)
.withFirstRecordAsHeader()
.withIgnoreEmptyLines()
.parse(reader);
Map<String, Integer> headerMap = csvParser.getHeaderMap();
观察调试器会发现header值是非紧凑字符串(UTF-16),而comparand值是紧凑字符串(ASCII):
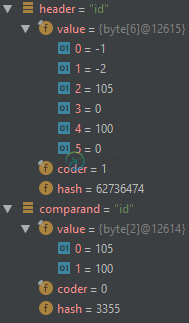
这是默认行为还是bug?如何使equalsignorecase的计算结果为true?
共有1个答案

您的标头值以UTF-16 BOMFFFE开始。读取标头时删除BOM,然后与比较和进行比较。
-
问题内容: 我正在寻找一种在Java 1.8中创建紧凑配置文件的方法。是否可以创建紧凑配置文件,因为这是说它仅适用于嵌入式版本 问题答案: 简短答案 JEP 161指出配置文件必须使用Java 8。要创建它们,请使用 应答器稍长 您怀疑配置文件可能仅存在于嵌入式平台上,并且@skiwi的评论使我有些困惑,因此我决定自己检查一下。 OpenJDK示例 为了检查配置文件是否存在,我使用了OpenJDK
-
我试图通过GridBagLayout实现以下目标: 框架将接收一组“字段”(JLabel,JTextField对),我想以“网格状”的方式排列它们,其中一行将包含两个这样的对(JLabel1 JField1 JLabel2 JField2)。当一行包含这四个组件时,下一个组件将添加到另一行。 编辑:我希望组件从面板顶部开始 我的代码生成以下布局。我希望组件的布局更紧凑(尤其是垂直距离) 下面是代码
-
问题内容: 这是我的数据库的快照。 col1和col2都声明为int。 我的ComputedColumn当前添加列1和2,如下所示… 取而代之的是,我的ComputedColumn应该将列1和2(在中间包含 ’-‘ 字符)连接起来,如下所示… 那么,正确的语法是什么? 问题答案: 您可能将计算列定义为。试试吧。 或者,如果您愿意,可以替换为或选择其他长度。
-
问题内容: 我正在阅读最近发布的The Go Programming Language ,到目前为止,这是一件令人高兴的事情(Brian Kernighan是其中的一位作者,无论如何我都不会期待别的什么)。 我在第3章遇到了以下练习: 练习3.13尽可能紧凑地通过YB 编写KB,MB的声明。 ( 注 :在此上下文中,KB,MB等表示1000的幂) 在此之前有一节,其中介绍了一种有用的常量生成器机制
-
问题内容: 我对String串联感到困惑。 输出为: 50abc20 50abc1010 我想知道为什么在两种情况下都将 20 + 30 加在一起,但是 10 + 10 需要加上括号(s1)而不是串联到String(s2)。请在此处说明String运算符的工作方式。 问题答案: 加法保持关联。以第一种情况 在第二种情况下:
-
我尝试创建一个使用压缩和删除的Kafka主题配置,以实现以下目标: 在保留期限内,保留密钥的最新版本 在保留期之后,要删除的任何早于时间戳的消息 当我在测试中将其设置为较小的量时,例如20mins、1hr等,我可以正确地看到数据在保留期后被修剪,只需调整主题上的。 我可以看到数据正按照预期的那样被正确压缩,但是如果我从一开始就阅读主题,那么在10天的保留期之后,比10天早得多的数据仍然存在。这么长