
使用StanfordCoreNLP管道而不是AnnotationPipeline提取日期

当我使用StanfordCoreNLP的SUTime功能,使用其留档中给出的代码,其中涉及使用AnnotationPipeline创建管道对象时,我能够成功地从字符串中提取TIME。


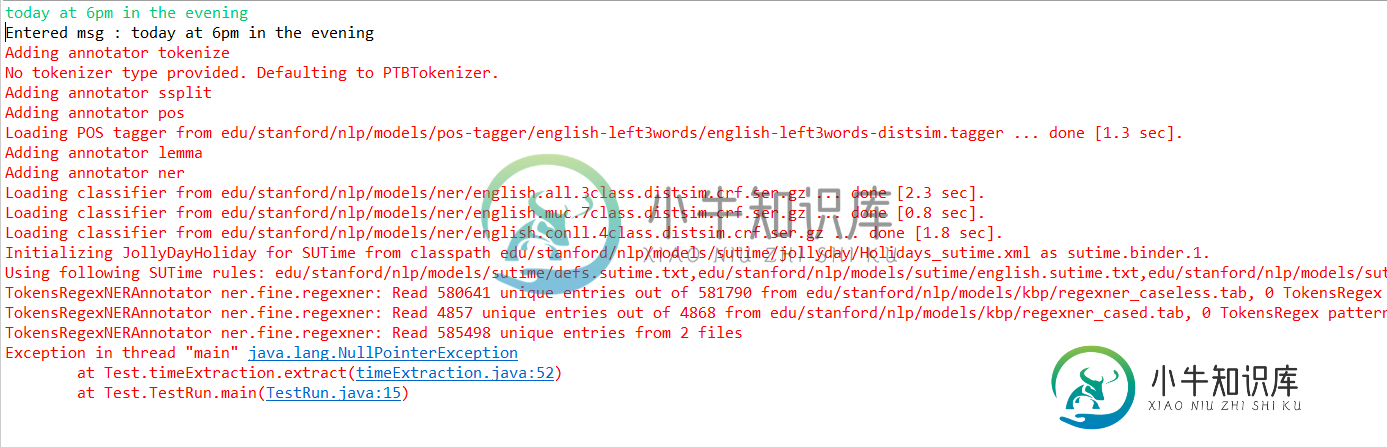
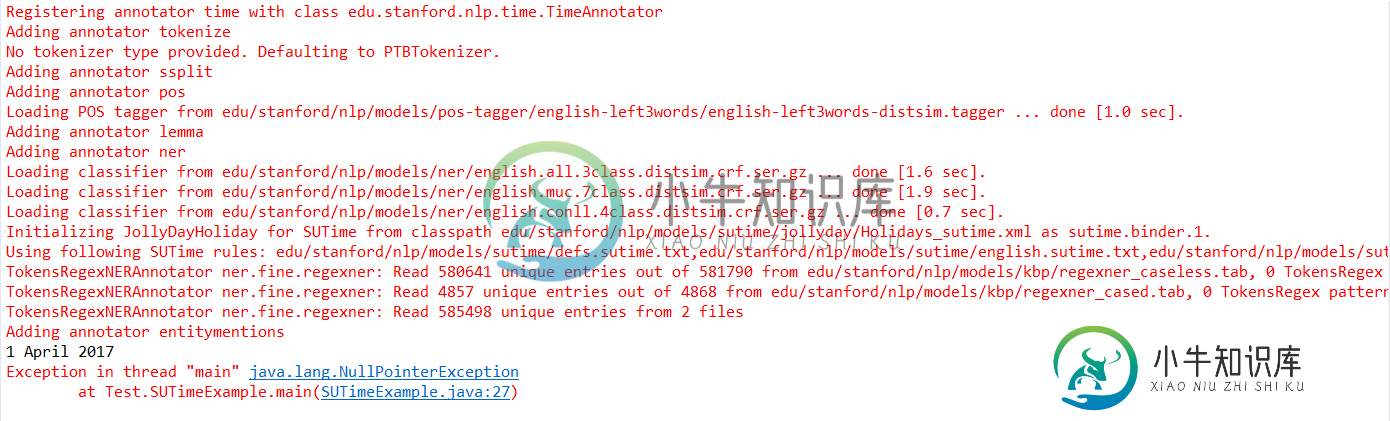
我还尝试了@StanfordNLPHelp在这个链接中建议的解决方案:使用StanfordCoreNLP管道的日期
但错误仍然存在:
共有2个答案

相同的TIMEX3格式,这是由于使用:
obj.get(TimeExpress. Annotation.class). getTemporal()---

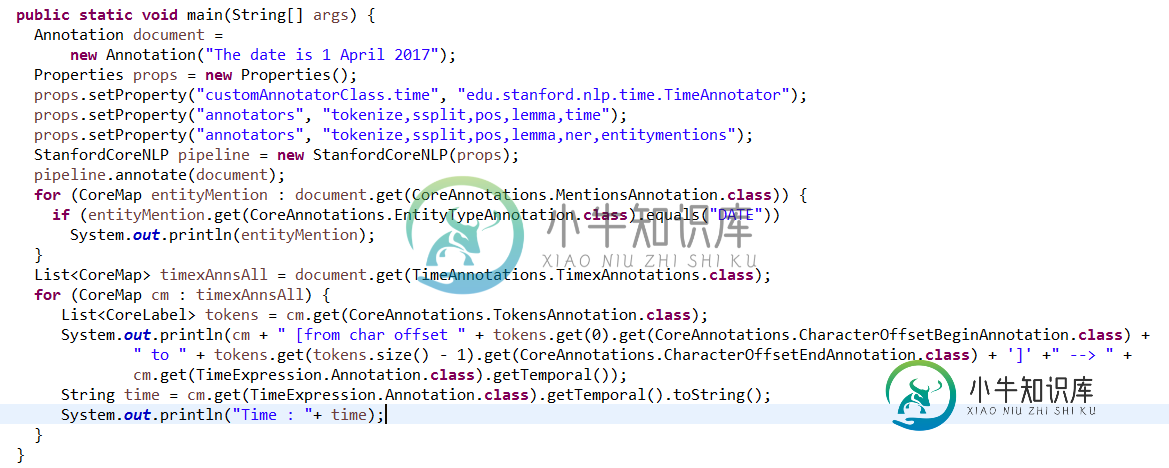
标准的ner注释器将运行SUTime。有关Java API信息,请参见以下链接:
https://stanfordnlp.github.io/CoreNLP/api.html
基本示例:
import edu.stanford.nlp.coref.data.CorefChain;
import edu.stanford.nlp.ling.*;
import edu.stanford.nlp.ie.util.*;
import edu.stanford.nlp.pipeline.*;
import edu.stanford.nlp.semgraph.*;
import edu.stanford.nlp.trees.*;
import java.util.*;
public class BasicPipelineExample {
public static String text = "Joe Smith was born in California. " +
"In 2017, he went to Paris, France in the summer. " +
"His flight left at 3:00pm on July 10th, 2017. " +
"After eating some escargot for the first time, Joe said, \"That was delicious!\" " +
"He sent a postcard to his sister Jane Smith. " +
"After hearing about Joe's trip, Jane decided she might go to France one day.";
public static void main(String[] args) {
// set up pipeline properties
Properties props = new Properties();
// set the list of annotators to run
props.setProperty("annotators", "tokenize,ssplit,pos,lemma,ner,parse,depparse,coref,kbp,quote");
// set a property for an annotator, in this case the coref annotator is being set to use the neural algorithm
props.setProperty("coref.algorithm", "neural");
// build pipeline
StanfordCoreNLP pipeline = new StanfordCoreNLP(props);
// create a document object
CoreDocument document = new CoreDocument(text);
// annnotate the document
pipeline.annotate(document);
// examples
// 10th token of the document
CoreLabel token = document.tokens().get(10);
System.out.println("Example: token");
System.out.println(token);
System.out.println();
// text of the first sentence
String sentenceText = document.sentences().get(0).text();
System.out.println("Example: sentence");
System.out.println(sentenceText);
System.out.println();
// second sentence
CoreSentence sentence = document.sentences().get(1);
// list of the part-of-speech tags for the second sentence
List<String> posTags = sentence.posTags();
System.out.println("Example: pos tags");
System.out.println(posTags);
System.out.println();
// list of the ner tags for the second sentence
List<String> nerTags = sentence.nerTags();
System.out.println("Example: ner tags");
System.out.println(nerTags);
System.out.println();
// constituency parse for the second sentence
Tree constituencyParse = sentence.constituencyParse();
System.out.println("Example: constituency parse");
System.out.println(constituencyParse);
System.out.println();
// dependency parse for the second sentence
SemanticGraph dependencyParse = sentence.dependencyParse();
System.out.println("Example: dependency parse");
System.out.println(dependencyParse);
System.out.println();
// kbp relations found in fifth sentence
List<RelationTriple> relations =
document.sentences().get(4).relations();
System.out.println("Example: relation");
System.out.println(relations.get(0));
System.out.println();
// entity mentions in the second sentence
List<CoreEntityMention> entityMentions = sentence.entityMentions();
System.out.println("Example: entity mentions");
System.out.println(entityMentions);
System.out.println();
// coreference between entity mentions
CoreEntityMention originalEntityMention = document.sentences().get(3).entityMentions().get(1);
System.out.println("Example: original entity mention");
System.out.println(originalEntityMention);
System.out.println("Example: canonical entity mention");
System.out.println(originalEntityMention.canonicalEntityMention().get());
System.out.println();
// get document wide coref info
Map<Integer, CorefChain> corefChains = document.corefChains();
System.out.println("Example: coref chains for document");
System.out.println(corefChains);
System.out.println();
// get quotes in document
List<CoreQuote> quotes = document.quotes();
CoreQuote quote = quotes.get(0);
System.out.println("Example: quote");
System.out.println(quote);
System.out.println();
// original speaker of quote
// note that quote.speaker() returns an Optional
System.out.println("Example: original speaker of quote");
System.out.println(quote.speaker().get());
System.out.println();
// canonical speaker of quote
System.out.println("Example: canonical speaker of quote");
System.out.println(quote.canonicalSpeaker().get());
System.out.println();
}
}
如果只需要日期,可以在ner之后删除注释器。
-
如果我使用TokenizerNotator、WordsToSentencesAnnotator、POSTaggerAnnotator和sutime创建一个AnnotationPipeline,我会将TimexAnnotations附加到生成的注释上。 但是,如果我创建一个StanfordCoreNLP管道,并将“annotators”属性设置为“tokenize,ssplit,pos,lemma,
-
管道A:仅由其自身回购之外的多个其他管道触发,但在同一项目中。作为被触发的结果,它对自己的回购进行更改,因此触发管道B。 pipleline B:仅由对其自身回购的更改触发,当被触发时,它将继续执行所需的任何操作 将语法流水线化 当前行为 null null 安装:https://docs.microsoft.com/en-us/azure/devops/cli/?view=azure-devop
-
在我的web应用程序中,我使用struts2和FreeMarker。区域设置是法语。在我的freemarker模板中,我在一个input元素中定义了jQuery ui,该元素的name属性指向对象的date属性。 问题是,在表单提交时,有时我会收到警告,说。作为响应,我可以看到消息这很奇怪,因为问题有时会发生,有时不会... 我尝试将中的设置为法语,这很有帮助,但仍有10%的时间可以看到这个问题。
-
传递参数 链接管道 我们可以将多个管道连接在一起,以便在一个表达式中使用多个管道。
-
假设我有+10000个句子,我想像这个例子一样分析。有可能并行处理这些和多线程吗?
-
我正在使用管道来格式化我的日期,但如果没有解决方法,我就无法获得我想要的确切格式。我是误解了管道还是根本不可能? PLNKR视图