
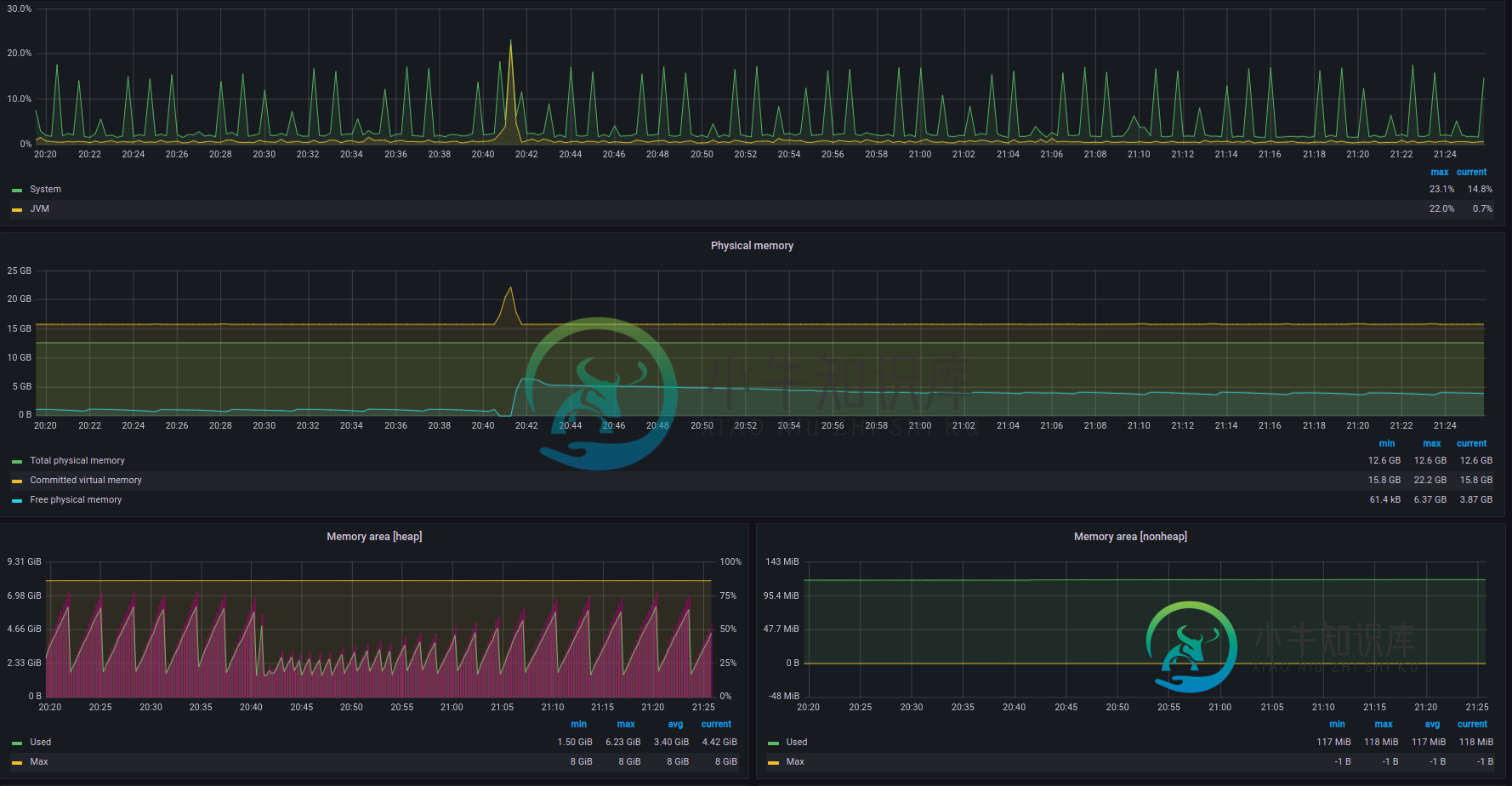
G1老一代promise记忆的突然增加和伊甸园大小的减少

出于某种原因,G1决定增加提交的旧一代内存(尽管使用的内存没有增加),并减少Eden一代提交的内存(从而减少可用空间)。这似乎导致GC年轻一代的运行激增,并使应用程序在一段时间内没有响应。
我们还可以看到CPU使用率和机器中提交的虚拟内存总量(比物理内存总量还要大)出现峰值。也可能会看到磁盘使用率和swapout/swapin的激增。
我的问题是:
- G1决定减少Eden的大小并大幅增加老一代的promise记忆是否可能导致所有这些峰值
- 它为什么这么做
- 如何防止它这样做
JVM版本:Ubuntu,OpenJDK运行时环境,11.0.11 9-Ubuntu-0ubuntu2。20.04
编辑:导致内存峰值的原因似乎是堆外JVM直接缓冲区内存池的突然增加。下图显示了4个指标的值:os_committed_virtual_memory(蓝色)、node_memory_SwapFree_bytes(红色)、jvm_buffer_pool_used_direct(绿色)和jvm_buffer_pool_used_mapped(黄色)。这些值以GB为单位。
我仍在试图找出是什么在使用这种直接缓冲内存,以及为什么它会对堆内存产生如此大的影响。

共有1个答案

该问题是由与直接内存使用有关的内存泄漏引起的。输出流在使用后未关闭。
-
G1GC老一代提交的堆随着时间的推移而上升(生产时大约5到6天)但老一代使用的堆没有。伊甸园和幸存者堆被迫减少到最低限度(总堆的5%),因此垃圾回收机制,因为越来越频繁。应用程序在一开始就缓存了一个大对象图,然后在整个运行生命周期中拥有其他时间/使用有限的缓存。它具有相当高的对象创建率,但除了缓存的对象之外,并没有向老一代推广其中的很多内容。 我已经通过gceasy运行了GC日志。io,您可以看到
-
你能回答我一个关于JVM垃圾收集过程的问题吗? 为什么堆被分为伊甸园、幸存者空间和老一代? 当一个年轻的疏散被处理时,通过从根开始的引用访问对象,以找出无法到达的对象。可到达的对象标记为“活动”,不可到达的对象不标记,将被删除。 因此,所有对象都会被考虑,包括旧一代中分配的对象也会被访问并标记是否可以访问。 据我所知,同时回收年轻一代和老一代是非常困难的,因为这两代人位于内存中不同的连续部分。 但
-
在JVM重启之前,java(8)内存容量是否会减少? 我正在使用jstat-gc转储内存信息,下面是两天的快照。与第一个快照相比,第二个快照对SC1和EC的资本金更少。 有人能帮助/解释为什么我看到这种行为吗?这是预期的吗?
-
我需要帮助理解从和获得的与GC相关的数字如何与传递给Java的设置相关。我在内存为16GB的服务器上使用以下设置启动应用程序(solr): 的输出开始: 为什么、、和都这么小,而却很大?不应该吗?并且总的堆大小不应该接近吗?当设置为4时,为什么正好是的一半? 下面是输出的其余部分。它与上面的内容相匹配,并且包括一个部分,我也不知道如何解释。 此外,GC日志表明“期望的幸存者大小”是6.2MB,这也
-
问题内容: 我正在使用Java创建即时贴应用程序。 我想做的事:每次单击 增加大小时,我想增加内部文本的大小。我显然会知道如何做相反的事情。 短代码: 问题答案: 为了使代码更通用,您可以在ActionListener中执行以下操作:
-
我刚刚读了一些关于G1算法的博客。 我对记忆集的用法感到困惑。 以下是我的想法: 既然我们可以使用DFS遍历来自GC根的每个引用,为什么我们需要记住集合? 因为所有的博客都说我们使用的原因是,我们不需要检查每个区域,看看是否有一个对象被GC-Roots引用