
Storm,螺栓潜伏期和总潜伏期之间的巨大差异?

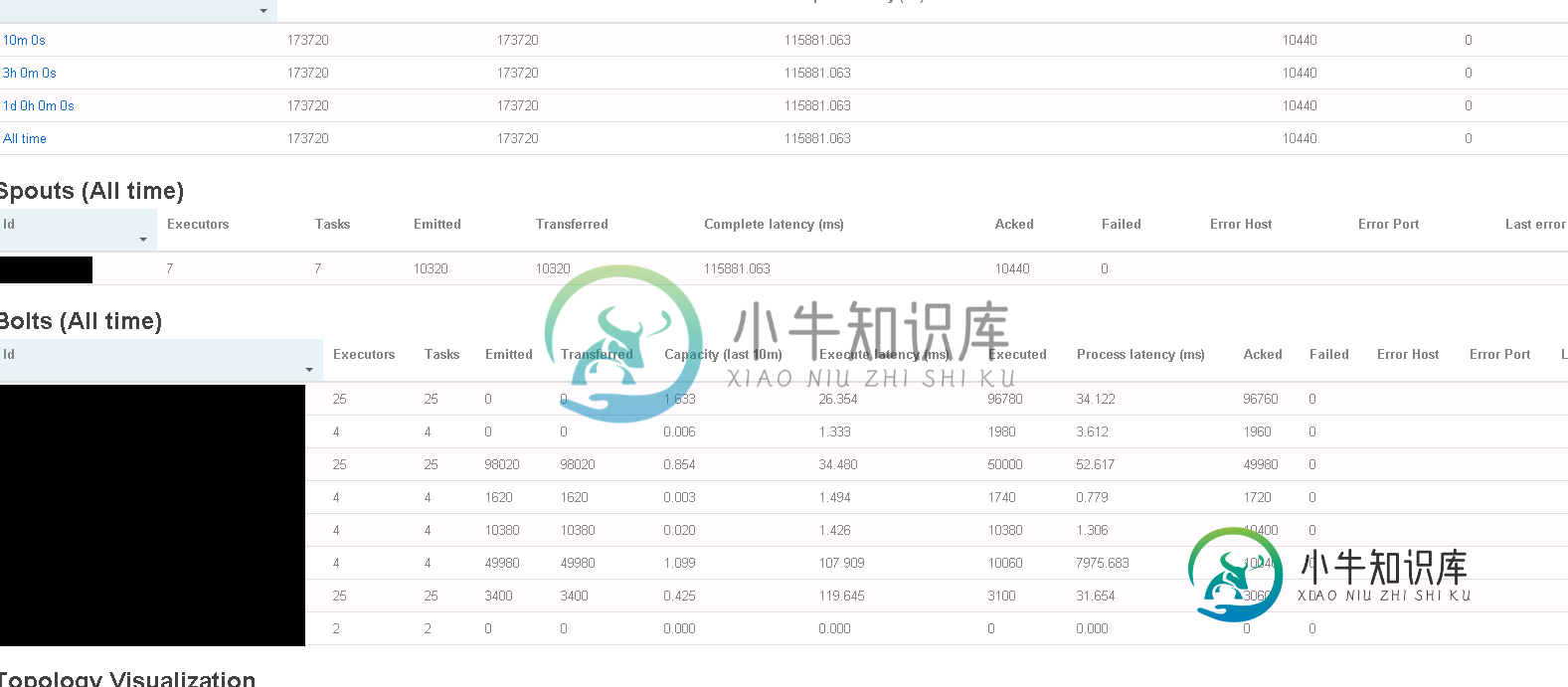
下面是我的拓扑Storm UI的截图。这是在拓扑完成处理10K消息之后拍摄的。
(拓扑配置为4个工作者并使用KafkaSpout)。
我的螺栓的“进程延迟”之和约为8100ms,而拓扑的完整延迟要长得多,为115881ms。
*请注意,在进程和执行延迟之间有很大差异的一个bolt实现了ticking bolt,批处理模式。因此这种差异是预料到的。
*编辑。我怀疑这种差异可能涉及到消息在完全处理后被喷口确认。如果我刷新StormUI时,它正在处理,我的最后一个螺栓的ack-ed数增加非常快,与对喷口的ack-ed数相比。虽然这可能是由于喷口接收的信息比最后的螺栓要少得多;最后一个螺栓接收的几百个消息可能代表喷口中的单个消息。但是,我想我应该提到这个怀疑,以获得关于它是否有可能的意见,喷口的acker任务是溢出的。
共有1个答案

可能有多种原因。首先,你需要了解这些数字是如何测量的。
- spout Complete latency:在调用
spout.ack()之前发出元组的时间。 - bolt执行延迟:运行
bolt.execute(). 所花费的时间
- bolt处理延迟:调用
bolt.execute()的时间,直到bolt对给定的输入元组执行。
如果不立即在bolt.execute中对每个传入的输入元组进行ack(这是绝对可以的),则处理延迟可能比执行延迟高得多。
-
我正在尝试测量拓扑中每个bolt的延迟。Storm给出的延迟数是不够的,因为我们想要计算百分位数。在我当前的设置中,我通过测量完成execute方法(包括发出调用)所需的时间来测量bolt的延迟。该方法的假设是,即使当前bolt实例和下一个bolt实例在拓扑结构中共享同一个执行器,收集器的emit也会立即返回,而不需要调用下一个bolt实例执行方法。
-
我用Kafka-Storm来连接Kafka和Storm。我有3台服务器运行zookeeper,kafka和Storm。Kafka中有一个主题“测试”,它有9个分区。 在storm拓扑中,KafkaSpout执行器的数量是9,默认情况下,任务的数量也应该是9。“提取”螺栓是唯一连接到KafkaSpout的螺栓,即“原木”喷口。 从用户界面来看,喷口的失败率很高。但是,bolt中执行的消息数=发出的消
-
加载和潜伏 绘图实际消耗的时间通常并不是影响性能的因素。图片消耗很大一部分内存,而且不太可能把需要显示的图片都保留在内存中,所以需要在应用运行的时候周期性地加载和卸载图片。 图片文件加载的速度被CPU和IO(输入/输出)同时影响。iOS设备中的闪存已经比传统硬盘快很多了,但仍然比RAM慢将近200倍左右,这就需要很小心地管理加载,来避免延迟。 只要有可能,试着在程序生命周期
-
Summary Also often refered to as persistent attacks, incubated testing is a complex testing method that needs more than one data validation vulnerability to work. Incubated vulnerabilities are typical
-
在我的拓扑中,当元组从spout转移到bolt或从bolt转移到bolt时,我看到大约1-2 ms的延迟。我使用纳秒时间戳来计算延迟,因为整个拓扑运行在单个Worker中。拓扑是在集群中运行的,集群运行在具有生产能力的硬件中。 根据我的理解,在这种情况下,元组不需要序列化/反序列化,因为所有东西都在单个JVM中。我已经将大多数喷流和螺栓的并行性提示设置为5,并且喷流仅以每秒100的速率产生事件。我
-
因此,如果您使用基于JUnit的单元测试,是否建议您运行一个小型模拟拓扑(?)并测试该拓扑下的(或)的隐含契约?或者,是否可以使用JUnit,但这意味着我们必须仔细模拟Bolt的生命周期(创建它、调用、嘲弄等)?在这种情况下,被测类(螺栓/喷口)有哪些一般的测试点需要考虑? 其他开发人员在创建正确的单元测试方面做了什么? 我注意到有一个拓扑测试API(参见:https://github.com/x