
使apache storm拓扑使用kafka的最新偏移量

我有一个kafkaspout,两个bolt用于处理数据,两个bolt用于在mongodb中存储处理过的数据
我正在使用apache flux创建拓扑,在那里我将数据从Kafka读取到spout。一切都运行得很好,但每次运行拓扑时,它都从一开始就处理kafka中的所有消息。并且一旦它处理了所有的消息,它就不会等待更多的消息和崩溃。
我如何使Storm拓扑只处理最新的消息。
这是我的拓扑文件.yaml
name: "kafka-topology"
components:
# MongoDB mapper
- id: "block-mapper"
className: "org.apache.storm.mongodb.common.mapper.SimpleMongoMapper"
configMethods:
- name: "withFields"
args: # The following are the tuple fields to map to a MongoDB document
- ["block"]
# MongoDB mapper
- id: "transaction-mapper"
className: "org.apache.storm.mongodb.common.mapper.SimpleMongoMapper"
configMethods:
- name: "withFields"
args: # The following are the tuple fields to map to a MongoDB document
- ["transaction"]
- id: "stringScheme"
className: "org.apache.storm.kafka.StringScheme"
- id: "stringMultiScheme"
className: "org.apache.storm.spout.SchemeAsMultiScheme"
constructorArgs:
- ref: "stringScheme"
- id: "zkHosts"
className: "org.apache.storm.kafka.ZkHosts"
constructorArgs:
- "172.25.33.191:2181"
- id: "spoutConfig"
className: "org.apache.storm.kafka.SpoutConfig"
constructorArgs:
# brokerHosts
- ref: "zkHosts"
# topic
- "blockdata"
# zkRoot
- ""
# id
- "myId"
properties:
- name: "scheme"
ref: "stringMultiScheme"
- name: "ignoreZkOffsets"
value: flase
config:
topology.workers: 1
# ...
# spout definitions
spouts:
- id: "kafka-spout"
className: "org.apache.storm.kafka.KafkaSpout"
constructorArgs:
- ref: "spoutConfig"
parallelism: 1
# bolt definitions
bolts:
- id: "blockprocessing-bolt"
className: "org.apache.storm.flux.wrappers.bolts.FluxShellBolt"
constructorArgs:
# command line
- ["python", "process-bolt.py"]
# output fields
- ["block"]
parallelism: 1
# ...
- id: "transprocessing-bolt"
className: "org.apache.storm.flux.wrappers.bolts.FluxShellBolt"
constructorArgs:
# command line
- ["python", "trans-bolt.py"]
# output fields
- ["transaction"]
parallelism: 1
# ...
- id: "mongoBlock-bolt"
className: "org.apache.storm.mongodb.bolt.MongoInsertBolt"
constructorArgs:
- "mongodb://172.25.33.205:27017/testdb"
- "block"
- ref: "block-mapper"
parallelism: 1
# ...
- id: "mongoTrans-bolt"
className: "org.apache.storm.mongodb.bolt.MongoInsertBolt"
constructorArgs:
- "mongodb://172.25.33.205:27017/testdb"
- "transaction"
- ref: "transaction-mapper"
parallelism: 1
# ...
- id: "log"
className: "org.apache.storm.flux.wrappers.bolts.LogInfoBolt"
parallelism: 1
# ...
#stream definitions
# stream definitions define connections between spouts and bolts.
# note that such connections can be cyclical
# custom stream groupings are also supported
streams:
- name: "kafka --> block-Processing" # name isn't used (placeholder for logging, UI, etc.)
from: "kafka-spout"
to: "blockprocessing-bolt"
grouping:
type: SHUFFLE
- name: "kafka --> transaction-processing" # name isn't used (placeholder for logging, UI, etc.)
from: "kafka-spout"
to: "transprocessing-bolt"
grouping:
type: SHUFFLE
- name: "block --> mongo"
from: "blockprocessing-bolt"
to: "mongoBlock-bolt"
grouping:
type: SHUFFLE
- name: "transaction --> mongo"
from: "transprocessing-bolt"
to: "mongoTrans-bolt"
grouping:
type: SHUFFLE
- id: "spoutConfig"
className: "org.apache.storm.kafka.SpoutConfig"
constructorArgs:
- ref: "zkHosts"
- "blockdata"
- ""
- "myId"
properties:
- name: "scheme"
ref: "stringMultiScheme"
- name: "startOffsetTime"
ref: "EarliestTime"
- name: "forceFromStart"
value: false
共有1个答案

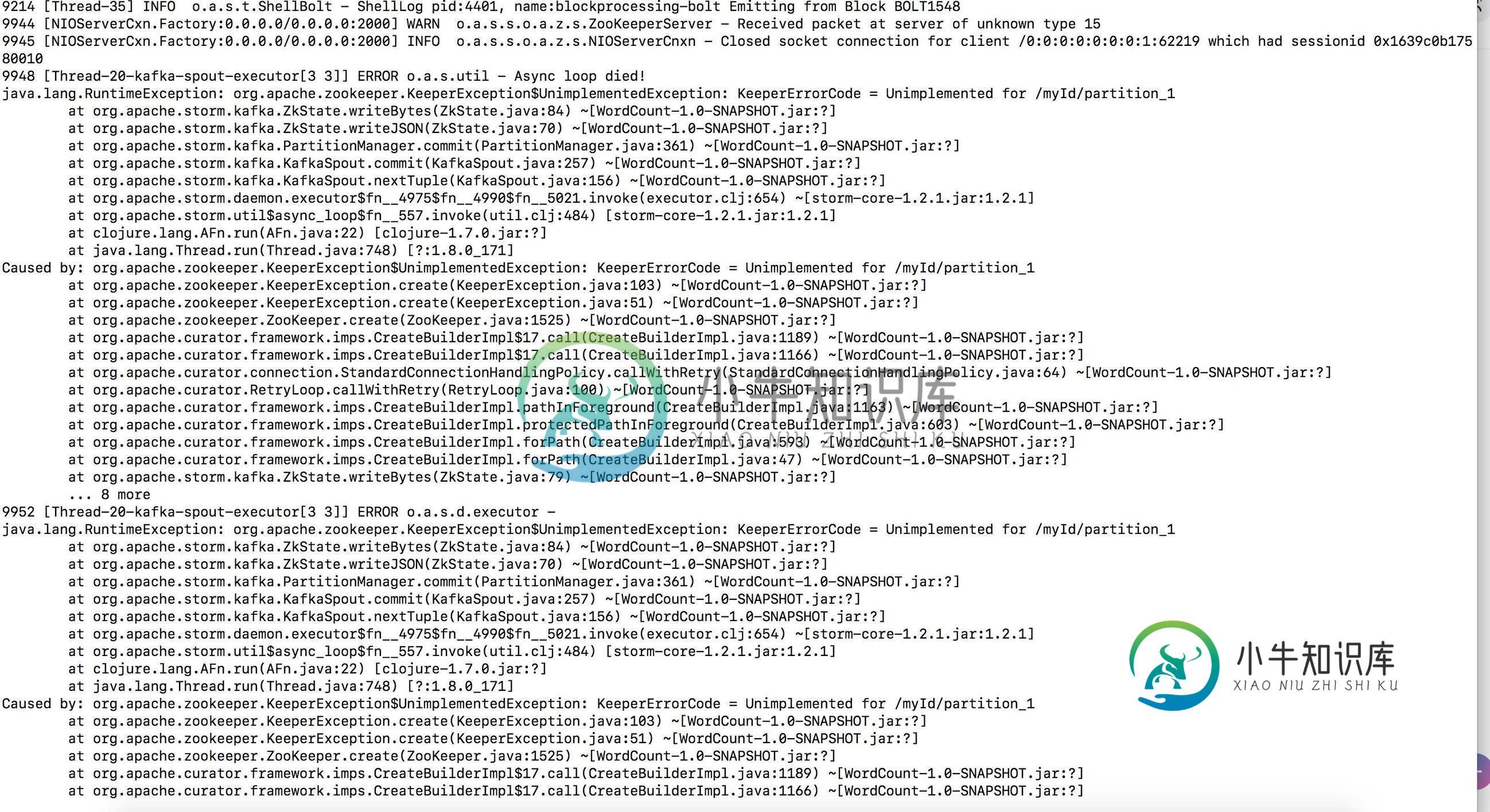
您需要将startOffsetTime设置为kafka.api.offSetRequest.LatestTime。正如您在https://github.com/apache/storm/tree/64af629a19a82591dbf3428f7fd6b02f39e0723f/external/storm-kafka#kafkaconfig上看到的,默认设置将转到可用的最早偏移量。
你碰到的例外情况似乎不相关。这看起来像是馆长和动物园管理员的不相容。
编辑:我认为您正在访问这个问题https://issues.apache.org/jira/browse/storm-2978。1.2.2应该很快就会发布,请在发布后尝试升级。
-
我正在设计一个ApacheStorm拓扑(使用streamparse),它由一个喷口(ApacheKafka喷口)和一个具有并行性的螺栓构建 螺栓分批读取信息。如果批量成功完成,我手动提交apache kafka偏移。 当mysql上的螺栓插入失败时,我不会在Kafka中提交偏移量,但是一些消息已经在喷口发送到螺栓的消息队列中。 应该删除队列中已经存在的消息,因为我无法在不丢失先前失败消息的情况下
-
我们有一个kafka streams Spring Boot应用程序(使用spring-kafka),这个应用程序目前从上游主题读取消息,应用一些转换,并将它们写入下游主题,它不做任何聚合或联接或任何高级kafka streams功能。 代码当前类似于
-
我想了解为什么我不能在LinearLayoutManager上使用scrollToPositionWithOffset方法?请看图片了解我的意思: 一点背景: 图像中的第一行(带有)是滚动RecyclerView以使位置(在本例中为50)可见-这通常意味着所选位置显示在可见的RecyclerView的底部(其中位置50在“滚动”后首先可见)。而我总是想在顶部展示它。根据我的研究,使用这个方法似乎是
-
在准备拓扑优化时,我偶然发现了以下几点: 目前,Kafka Streams在启用时会执行两种优化: 1-源KTable将源主题重新用作变更日志主题。 2-如果可能,Kafka流会将多个重新分区主题压缩为单个重新分区主题。 这个问题是关于第一点的。我不完全明白这里发生了什么。只是为了确保我没有在这里做任何假设。有人能解释一下,以前是什么状态吗: 1-KTable使用内部变更日志主题吗?如果是,有人能
-
我是Storm和Kafka的新手,我可以在一段时间后在本地虚拟机上安装它们。我目前有一个有效的wordCount拓扑,从dropBox文本文件中提取句子: 现在我想升级我的喷口,使用Kafka的文本,以便在拓扑结构中提交到我的下一个螺栓。我试图在git中遵循许多文章和代码,但没有任何成功。例如:这个Kafka喷口。谁能帮助我,给我一些方向,以便实现新的spout.java文件?谢谢你!
-
我用Kafka壶嘴来消费信息。但是,如果我必须更改拓扑并上传,那么它将从旧消息恢复还是从新消息开始?Kafka壶嘴给了我们从哪里消费的时间戳,但我怎么知道时间戳呢?