
ggplot2轴上的错乱韩文和中文字符

我无法让ggplot2在轴中正确渲染朝鲜语和中文字符,如下所示:
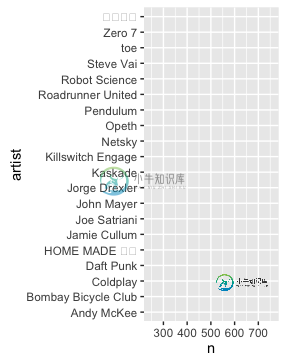
顶部的项目是韩语,而底部的第五个项目包含汉字。
您可以使用以下代码复制“绘图”:
top_artists <- structure(
list(
artist = c("John Mayer", "Jorge Drexler", "Netsky",
"Daft Punk", "Joe Satriani", "Steve Vai", "Zero 7", "Pendulum",
"Jamie Cullum", "소녀시대", "Coldplay", "Killswitch Engage",
"Andy McKee", "toe", "Bombay Bicycle Club", "Roadrunner United",
"Kaskade", "Robot Science", "HOME MADE 家族", "Opeth"),
genre = c("singer-songwriter", "singer-songwriter", "drum and bass",
"electronic", "guitar virtuoso", "guitar virtuoso",
"chillout", "drum and bass", "jazz", "k-pop",
"rock", "metalcore", "acoustic", "post-rock", "indie", "metal",
"house", "electronic", "hip-hop", "progressive metal"),
n = c(760L, 603L, 564L, 428L, 418L, 417L, 417L,
410L, 407L, 402L, 387L, 385L, 319L, 303L,
292L, 289L, 275L, 257L, 256L, 244L)),
class = c("tbl_df", "tbl", "data.frame"),
row.names = c(NA, -20L),
.Names = c("artist", "genre", "n"))
ggplot(top_artists, aes(artist, n)) + coord_flip()
我意识到我应该有地理信息来实际显示数据,但我想我会尽可能少。这个问题仍然存在于全面的情节中,包括地理信息、尺度和主题设置等...
以下是我的会议信息:
R version 3.3.0 (2016-05-03)
Platform: x86_64-apple-darwin13.4.0 (64-bit)
Running under: OS X 10.11.5 (El Capitan)
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] viridis_0.3.4 scales_0.4.0 hrbrmisc_0.0.0.9002 zoo_1.7-13 streamgraph_0.8.1
[6] ggplot2_2.1.0 lubridate_1.5.6 tidyr_0.5.1 dplyr_0.5.0
loaded via a namespace (and not attached):
[1] Rcpp_0.12.5 rstudioapi_0.6 magrittr_1.5 munsell_0.4.3 xtable_1.8-2
[6] colorspace_1.2-6 lattice_0.20-33 R6_2.1.2 stringr_1.0.0 plyr_1.8.4
[11] tools_3.3.0 xts_0.9-7 grid_3.3.0 gtable_0.2.0 miniUI_0.1.1
[16] DBI_0.4-1 htmltools_0.3.5 lazyeval_0.2.0 assertthat_0.1 digest_0.6.9
[21] tibble_1.0 gridExtra_2.2.1 shiny_0.13.2 formatR_1.4 htmlwidgets_0.6
[26] mime_0.4 memoise_1.0.0 labeling_0.3 stringi_1.1.1 httpuv_1.3.3
共有1个答案

事实证明,问题与MacOS上默认ggplot2主题使用的字体有关,该主题不支持韩语/日语。
为了修复它,我必须手动将字体设置为“HiraginoSans-W3”。
主题(axis.title=element_text(font=“HiraginoSans-W3”))
-
我有一个中文/韩文字符的超文本标记语言字符串。我想使用iText将超文本标记语言转换为PDF。我读到我们需要将FONT嵌入到PDF中,以使Unicode字符显示在PDF上。 当我尝试嵌入wts11时。ttf(带有编码标识_H)或STSong Light(带有编码Unigb-UCS2-H),我只能看到汉字,但看不到韩文字符。我试着用arialuni。ttf(带有编码标识),但仍然只能看到汉字,不能看
-
我需要用正则表达式提取单词中''之前和''之前的韩文字母。 458 138->提取“”和“” 1600->提取“” 我有[^\X00-\X7F]+(?=)[^\X00-\X7F]+(?=)。但这并不是对所有人都有效
-
我的学习应用程序需要显示朝鲜语、英语和中文。我的一个解决方案是嵌入韩文/英文字体和中文字体。然后将一个具有不同文本格式的字符串放在一起。 问题是,我确信IOS和Android设备应该已经包含原生中文、韩文和英文字体,我更愿意参考和使用这些字体,而不是打包它们。 我尝试通过使用检测字体,但是当我使用时,我没有得到true或任何东西,所以我不知道如何选择正确的设备字体。 如果这样不行,是否有包含所有这
-
问题内容: 我希望能够将中文,日文和韩文书写的字符识别为一般组和细分语言。原因如下: 将CJK视为一般团体: 我正在制作一个垂直脚本蒙古语。为此,我需要将文本行旋转90度,因为字形是水平存储在字体中的。但是,对于CJK语言,我需要再次将它们旋转回去,以使它们以正确的方向书写,而只是沿线叠放在一起。 将CJK区分为特定的语言: 我也在制作蒙古文字典,当用户输入CJK字符进行查找时,我想自动识别该语言
-
大多数 windows 平台下的 ftp服务器 使用 GB2312 编码,而 lftp 使用 UTF-8 编码,使用 lftp 访问这些服务器,中文显示为乱码。可以通过指定编码来解决 lftp >set ftp:charset gbk #设置远程编码为gbk lftp >set file:charset utf8 #设置本地编码(Linux系统默认使用 UTF-8,这一步通常可以省略) 也