
正则表达式以匹配引号中带有双引号的字符串

我面临一个挑战,要以以下格式匹配输入:
- 输入由key=value对组成。关键字以斜杠开头。值可以是数字或引号中的字符串。
- 该值可以选择性地包含转义引号,即引号后面跟着引号(“”)。这种转义引号应该被视为价值的一部分。不需要检查转义引号是否平衡(例如,由另一个转义引号结束)。
正则表达式应该匹配序列中给定的key=value部分,并且对于长输入(例如value是10000个字符)不应该中断。
/(\w+)=(\d+|"(?:""|[^"])+"(?!"))
/(\w+)=(\d+|"(?:""|[^"]+)+"(?!"))
/(\w+)=(\d+|".+?(?<!")(?:"")*"(?!"))
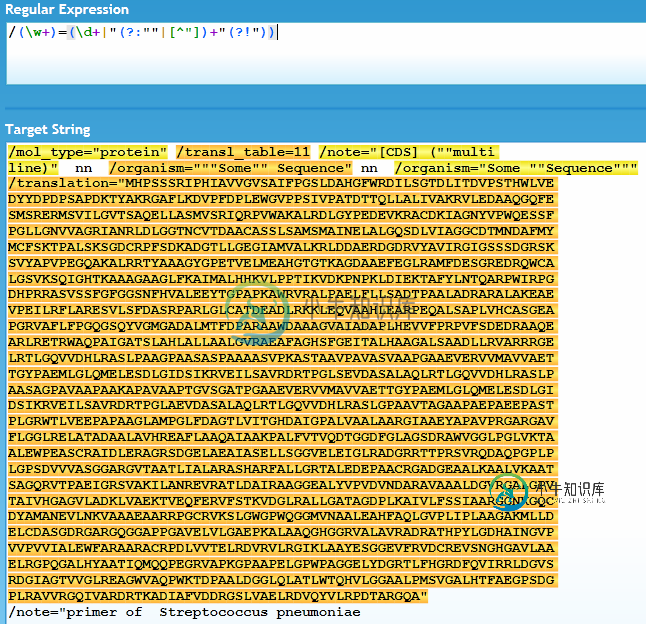
/mol_type="protein" /transl_table=11 /note="[CDS] (""multi
line)" nn /organism="""Some"" Sequence" nn /organism="Some ""Sequence"""
/translation="MHPSSSRIPHIAVVGVSAIFPGSLDAHGFWRDILSGTDLITDVPSTHWLVE
DYYDPDPSAPDKTYAKRGAFLKDVPFDPLEWGVPPSIVPATDTTQLLALIVAKRVLEDAAQGQFE
SMSRERMSVILGVTSAQELLASMVSRIQRPVWAKALRDLGYPEDEVKRACDKIAGNYVPWQESSF
PGLLGNVVAGRIANRLDLGGTNCVTDAACASSLSAMSMAINELALGQSDLVIAGGCDTMNDAFMY
MCFSKTPALSKSGDCRPFSDKADGTLLGEGIAMVALKRLDDAERDGDRVYAVIRGIGSSSDGRSK
SVYAPVPEGQAKALRRTYAAAGYGPETVELMEAHGTGTKAGDAAEFEGLRAMFDESGREDRQWCA
LGSVKSQIGHTKAAAGAAGLFKAIMALHHKVLPPTIKVDKPNPKLDIEKTAFYLNTQARPWIRPG
DHPRRASVSSFGFGGSNFHVALEEYTGPAPKAWRVRALPAELFLLSADTPAALADRARALAKEAE
VPEILRFLARESVLSFDASRPARLGLCATDEADLRKKLEQVAAHLEARPEQALSAPLVHCASGEA
PGRVAFLFPGQGSQYVGMGADALMTFDPARAAWDAAAGVAIADAPLHEVVFPRPVFSDEDRAAQE
ARLRETRWAQPAIGATSLAHLALLAALGVRAEAFAGHSFGEITALHAAGALSAADLLRVARRRGE
LRTLGQVVDHLRASLPAAGPAASASPAAAASVPKASTAAVPAVASVAAPGAAEVERVVMAVVAET
TGYPAEMLGLQMELESDLGIDSIKRVEILSAVRDRTPGLSEVDASALAQLRTLGQVVDHLRASLP
AASAGPAVAAPAAKAPAVAAPTGVSGATPGAAEVERVVMAVVAETTGYPAEMLGLQMELESDLGI
DSIKRVEILSAVRDRTPGLAEVDASALAQLRTLGQVVDHLRASLGPAAVTAGAAPAEPAEEPAST
PLGRWTLVEEPAPAAGLAMPGLFDAGTLVITGHDAIGPALVAALAARGIAAEYAPAVPRGARGAV
FLGGLRELATADAALAVHREAFLAAQAIAAKPALFVTVQDTGGDFGLAGSDRAWVGGLPGLVKTA
ALEWPEASCRAIDLERAGRSDGELAEAIASELLSGGVELEIGLRADGRRTTPRSVRQDAQPGPLP
LGPSDVVVASGGARGVTAATLIALARASHARFALLGRTALEDEPAACRGADGEAALKAALVKAAT
SAGQRVTPAEIGRSVAKILANREVRATLDAIRAAGGEALYVPVDVNDARAVAAALDGVRGALGPV
TAIVHGAGVLADKLVAEKTVEQFERVFSTKVDGLRALLGATAGDPLKAIVLFSSIAARGGNKGQC
DYAMANEVLNKVAAAEAARRPGCRVKSLGWGPWQGGMVNAALEAHFAQLGVPLIPLAAGAKMLLD
ELCDASGDRGARGQGGAPPGAVELVLGAEPKALAAQGHGGRVALAVRADRATHPYLGDHAINGVP
VVPVVIALEWFARAARACRPDLVVTELRDVRVLRGIKLAAYESGGEVFRVDCREVSNGHGAVLAA
ELRGPQGALHYAATIQMQQPEGRVAPKGPAAPELGPWPAGGELYDGRTLFHGRDFQVIRRLDGVS
RDGIAGTVVGLREAGWVAQPWKTDPAALDGGLQLATLWTQHVLGGAALPMSVGALHTFAEGPSDG
PLRAVVRGQIVARDRTKADIAFVDDRGSLVAELRDVQYVLRPDTARGQA"
/note="primer of Streptococcus pneumoniae
共有1个答案

为了在合理的时间内失败,你确实需要避免灾难性的回溯。这可以使用原子分组(?>...):
/(\w+)=(\d+|"(?>(?>""|[^"]+)+)"(?!"))
# (?>(?>""|[^"]+)+)
(?> # throw away the states created by (...)+
(?> # throw away the states created by [^"]+
""|[^"]+
)+
)
您在对永远不匹配的字符串使用(?:“”[^“]+)+时出现的问题与以下事实有关:每次匹配新的[^”]字符时,regex引擎可以选择使用内部或外部+量化词。
这导致了很多回溯的可能性,在返回一个故障之前,发动机必须尝试所有这些。
-
我想解析以下字符串: 我正在使用,所以我这里缺少的是正确的正则表达式。规则是正则表达式必须: 隔离任何单个单词 任何用双引号括起来的子字符串都是匹配的 单词中的双引号必须忽略(稍后我将用空格替换它们)。 因此,结果匹配应该是: < li>w1 w"2 < li>w3 < li>| < li>w4 < li>w"5 < li>w6 w7 双引号是否包含在双引号括起来的子字符串中是无关紧要的(例如,1
-
问题内容: 我想构建一个简单的正则表达式,以涵盖带引号的字符串,包括其中的所有转义引号。例如, 显然,类似 不起作用,因为它与第一个转义的引号匹配。 什么是正确的版本? 我想对于其他转义字符,答案是相同的(只需替换相应的字符)。 顺便说一句,我知道“包罗万象”的正则表达式 但我会尽量避免使用它,因为毫不奇怪,它的运行速度要比更具体的设备慢。 问题答案: 所有其他答案的问题是,它们只适合最初的明显测
-
我使用此模式在解析器中匹配单引号字符串: 但是我需要正则表达式,它可以找到带有 postgres 的单引号字符串,例如 bied of single qoutes(加倍单个 qoutes)。需要匹配这样的东西: 我想为以单引号开头和结尾的字符串找到最短的匹配项,因此上面的字符串意味着 3 个子字符串:
-
有没有一种方法使组的“capture”可以在regex后面引用,但其捕获的值不在匹配列表中返回? 或者其他一些方法来解决我(看似简单)的问题。
-
这是我之前问题的后续。我意识到我需要更具体地说明我的regex案例,以获得适用于我的案例的答案。 我已经与这个正则表达式斗争了很长一段时间(也使用我上一个问题的答案),我似乎无法构建我需要的东西。 我需要将所有字符串中出现的两个重复出现的单引号替换为(因此字符串内部意味着单引号)。这是因为在一种语言(语法)中,字符串中的引号使用<code>‘转义。 这里有一个例子(实际的例子可以包含用< code
-
我有一个非常好的正则表达式,它从文本中选择引用: 但是我需要一个正则表达式,它从没有引号的文本中选择引号。 例如,我有: 鲸鱼包括八个现存的家族:“鲸豚科”(白鲸),“鲸豚科”(露脊鲸),“鲸豚科”(侏儒露脊鲸),“白鲸科”(灰鲸),“独角鲸科”(白鲸和独角鲸),“抹香鲸科”(抹香鲸)。。。 我需要在引号之间提取文本: 龟甲翅目,龟甲翅目,龟甲翅目,... 要提取括号之间的文本,我使用正则表达式: