
JVM堆栈、堆和线程如何映射到物理内存或操作系统

编译器手册(dragon book)解释了值类型是在堆栈上创建的,引用类型是在堆上创建的。
对于Java,JVM在运行时数据区也包含堆和堆栈。对象和数组在堆上创建,方法框架被推到堆栈。一个堆由所有线程共享,而每个线程都有自己的堆栈。下图显示了这一点:
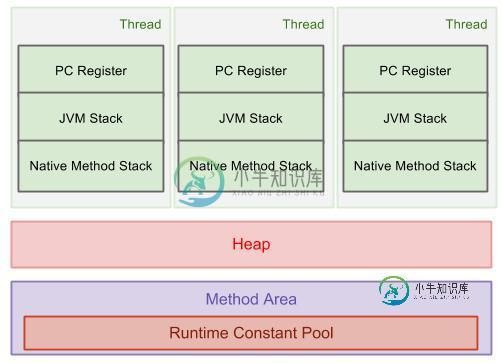
有关Java运行时数据区域的更多信息。
-
null
共有1个答案

我不明白的是,既然JVM本质上是一个软件,那么这些JVM堆、堆栈和线程是如何映射到物理机器的呢?
堆是预先分配的虚拟内存的连续区域。例如。
void* heap = malloc(Xmx); // get the maximum size.
当线程启动时,由线程库分配堆栈。同样,它是虚拟内存的一个连续区域,这是最大堆栈大小。再一次,你可以把它想象成
void* stack = malloc(Xss); // get the maximum stack size.
JVM堆、堆栈、寄存器和线程如何映射到操作系统?或者我应该问它们是如何映射到物理机器的?
同样没有魔法。JVM堆是一个内存区域,JVM堆栈与C+使用的本地堆栈相同,JVM的寄存器与C+使用的本地寄存器相同,JVM线程实际上是C+使用的本地线程。
我想你是在假设有更多的魔法或默默无闻。相反,您应该假设已经使用了最简单、高效和轻量级的设计,并且您将不会太远。
-
我们Java开发人员有时会使用来确保我们为每个特定于线程的堆栈提供了1MB的空间。现在,我经常感到困惑,JVM从哪里借用了1MB,从堆或系统内存中借用,或者Java为线程分配任何特定的内存。你能帮我理解一下吗? 此外,我们是否有一个可视化(插件)运行时工具,可以以可理解的方式显示堆和堆栈的内容? 提前感谢。
-
当我研究线程及其占用的内存(线程堆栈)时,我决定做一个简单的负载测试,看看线程的数量如何影响我的计算机上的RAM。 所以,在测试中,我使用了Tomcat,在设置中。xml将最小和最大web容器线程池设置为200。在那之后,我在将pool设置为2000时也做了同样的操作。我很震惊,因为内存占用没有差异(通过Windows任务管理器进行检查),而且几乎是一样的。所以我认为这些线程可能必须处于运行状态,
-
问题内容: 是局部变量,将其存储在堆或堆栈中的何处? 问题答案: 在堆上。每当您用来创建对象时,它都会在堆上分配。
-
我们的一个sap系统(PI ABAP JAVA stack)出现了性能问题。为机器配置的整个64GB都被占用了(还有8个内核)。每个人都在怀疑java部分,但我认为不同。 重启内存不足错误的java服务器节点。查看hprof文件,我发现当为服务器节点配置3GB(-Xms和Xmx)堆时,它们的大小只有1.2G(3个服务器节点的平均大小)。这一观察导致以下疑问。 我读到过,当Xms和Xmx设置为相同的
-
本文向大家介绍java 中堆内存和栈内存理解,包括了java 中堆内存和栈内存理解的使用技巧和注意事项,需要的朋友参考一下 Java把内存分成两种,一种叫做栈内存,一种叫做堆内存 在函数中定义的一些基本类型的变量和对象的引用变量都是在函数的栈内存中分配。当在一段代码块中定义一个变量时,java就在栈中为这个变量分配内存空间,当超过变量的作用域后,java会自动释放掉为该变量分配的内存空间,该内存
-
我的问题是,如果我从java代码调用Shell脚本,脚本使用的内存,是从JVM堆空间分配,还是使用系统内存空间。