
在 AWS EBS 微服务 Docker 环境中使用 Kafka,以避免丢失用户请求并处理更多并发命中

目前,我正在使用AWS EBS微服务docker环境部署用Scala和Akka编写的微服务。如果微服务docker中的任何一个崩溃并重新启动。在这种情况下,我们将丢失用户请求,并且服务不会返回任何响应。我当前的架构可以毫无问题地处理多达1000个并发请求。为了避免这个问题,我计划使用Kafka来存储和检索所有的请求和响应。
因此,我想使用Kafka来管理我所有Web服务的请求和响应,并包括一个单独的服务或Web套接字来处理所有请求并将响应再次存储到Kafka。在这种情况下,如果我的核心进程 Docker 崩溃或重新启动。它不会在任何时间点丢失任何请求和响应。它将再次开始读取来自Kafka的请求并对其进行处理。
所有的web服务将请求存储在Kafka的相关主题中,并从相关的响应主题中获得响应,然后返回给API响应。我在Scala web services中找到了下面这个使用Kafka的库。
https://github.com/akka/reactive-kafka/
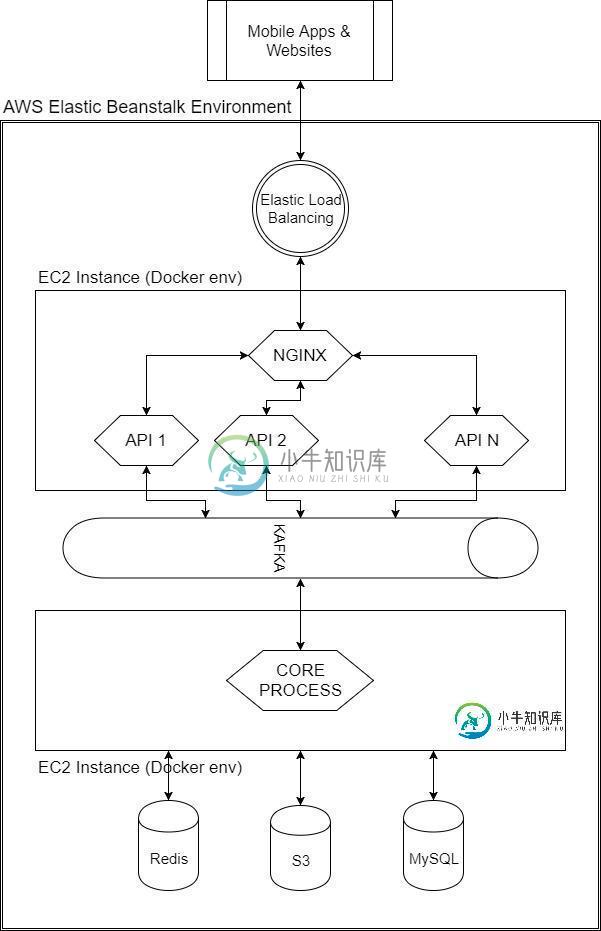
请查看随附的体系结构图,我将使用它来有效地处理来自客户端应用的大量并发请求。这是一个好的方法吗?我是否需要更改体系结构中的任何内容?
我在对Kafka和微服务dockers进行了更多研究后创建了这个架构。如果这个架构有什么问题,请告诉我。
共有1个答案

这是Kafka的面包和黄油,所以我认为你不会遇到任何架构问题。请注意,Kafka有相当大的运营开销。一个很好的入门资源是Kafka:Confluent编写的权威指南(https://www.confluent.io/wp-content/uploads/confluent-kafka-definitive-guide-complete.pdf)它详细介绍了许多他们在文档中没有提到的常见操作问题。
-
并发请求处理 我创建了一个服务器,并使用s.listenandserve()来处理请求。据我所知,这些请求是同时送达的。我使用一个简单的处理程序来检查它: 我看到,如果我发送了几个请求,我将看到所有的“1”出现,只有在一秒钟后所有的“2”出现。但是如果删除Hibernate行,我会看到程序在完成前一个请求之前从不启动请求(输出为1 2 1 2 1 2...)。所以我不明白,如果它们是并发的还是不是
-
我正在使用Spring Boot构建一个RESTful web服务。我的IDE是Eclipse Oxygen。 这里是我的控制器代码: 我的控制台输出是: 控制台输出显示每5秒调用一次控制器。但我每隔两秒就发送一次请求。 是否可以接受来自同一会话的并发多个请求? 谢谢!
-
寻找设计我的Kafka消费者的最佳方法。基本上,我想看看什么是避免数据丢失的最佳方法,以防在处理消息期间出现任何异常/错误。 我的用例如下。 a)我使用SERVICE来处理消息的原因是 - 将来我计划编写一个ERROR处理器应用程序,该应用程序将在一天结束时运行,它将尝试再次处理失败的消息(不是所有消息,而是由于任何依赖项(如父级缺失)而失败的消息)。 b)我想确保没有消息丢失,所以我会将消息保存
-
我们正在使用SpringBoot在JAVA中开发基于grpc的服务。 我们正在跟进https://github.com/LogNet/grpc-spring-boot-starter @GrpcService:用于服务器端服务 @GrpcClient:用于客户端存根 我可以测试这个应用程序。 问题:在生产过程中,我们每秒将收到大约5000个请求,每个请求可能需要25毫秒到1秒。 客户端:如何实现连
-
我有一个java项目,我正试图扩大我的项目,所以想旋转单个微服务的3个实例。 但我有个问题 解释一下 当用户登录时,从用户界面,每10秒一个api请求(针对特定用户)进入后端,该请求给出了Spring批处理作业的状态(对于已登录的特定用户,正在运行或未运行)。这仅适用于1个实例。 但是当我有 3 个实例(实例 1、2 假设10秒的第一个请求到达实例1,并且登录用户的作业正在运行-它返回作业正在运行
-
问题内容: 我正在几个平台上尝试并发请求处理。 实验的目的是对某些选定技术的能力范围进行 广泛的 测量。 我成立了一个Linux VM我的机器上有一个基本的围棋http服务器(香草中的默认包)。然后,服务器将计算 fasta 算法的修改版本,该版本将线程和进程限制为1,并返回结果。N设置为100000。该算法运行大约2秒钟。我在Google App Engine项目上使用了 相同的 算法和逻辑。