
Java堆转储:如何找到占用内存1的对象/类。伊奥。内蒂。缓冲器Bytebuutil 2。字节[]数组

我发现我的一个spring boot项目的内存(RAM消耗)正在日益增加。当我把jar文件上传到AWS服务器时,它占用了582MB的内存(分配的最大内存是1500MB),但每天,内存都在以50MB的速度增加到100MB,而今天,5天后,它占用了835MB。目前,该项目有100-150个用户,并且正常使用Rest API。
由于RAM的增加,应用程序多次出现以下错误(从日志中发现错误):
Exception in thread "http-nio-3384-ClientPoller" java.lang.OutOfMemoryError: Java heap space
所以为了解决这个问题,我发现通过使用JAVA堆转储,我可以找到占用内存的对象/类。所以通过在命令行中使用Jmap,我创建了一个堆转储,并将其上传到堆英雄和Eclipse内存分析器工具。在它们中,我发现了以下内容:
1.总浪费内存为:64.69MB(73%)(查看下面的屏幕截图)
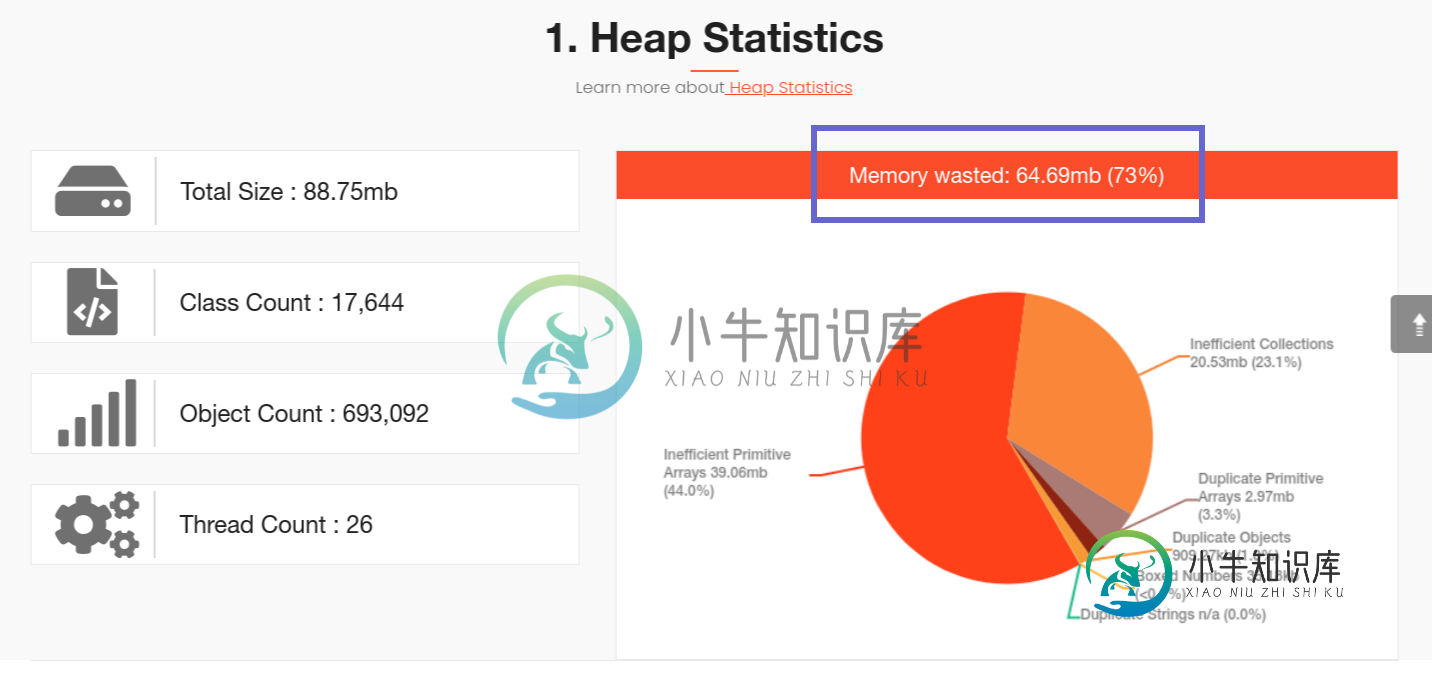
2.在这些中,34.06MB是由Byte[]数组和LinkedHashmap[]拍摄的(检查下面的截图),这是我在整个项目中从未使用过的。我在我的项目中搜索过,但没有找到。
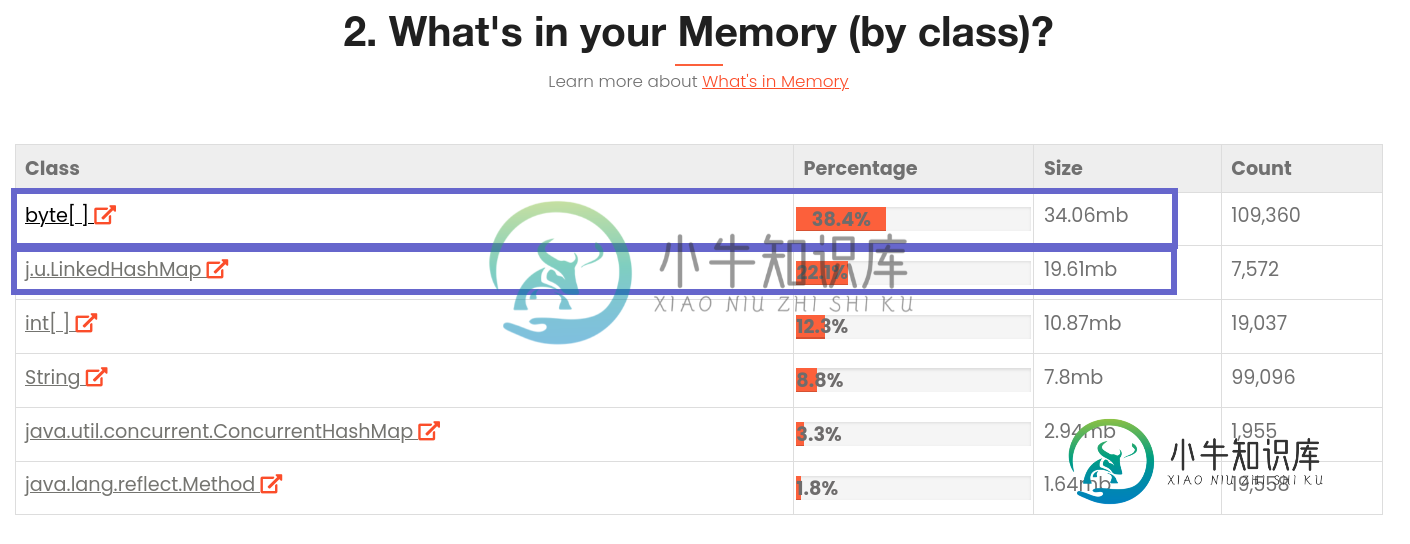
1. Java Static io.netty.buffer.ByteBufUtil.DEFAULT_ALLOCATOR
2. Java Static com.mysql.cj.jdbc.AbandonedConnectionCleanupThread.connectionFinalizerPhantomRefs`

所以我试图在我的项目中找到这个netty.buffer.,但是我没有找到任何与netty或缓冲区匹配的东西。
现在我的问题是如何减少内存泄漏,或者如何找到确切的内存消耗对象/类/变量,以便减少堆大小。
我知道很少有专家会要求提供源代码或类似的东西,但我相信,从堆转储中,我们可以找到内存泄漏或内存中可用的活动对象。我正在寻找那个选项或任何能减少堆转储的东西!
在过去的三周里,我一直在研究这个问题。任何帮助都将不胜感激。非常感谢。
共有2个答案

堆转储不足以检测内存泄漏。您需要查看调用GC后两个连续堆快照的差异。或者,您需要一个分析工具,可以为每个类提供生成计数。然后,您应该只查看在GC中幸存下来并从旧快照传递到新快照的域对象(而不是字节或字符串等通用对象)。或者,如果使用分析工具,可以查找仍然存在并在多代人中不断增长的旧域对象。
对象已经存在了很多代,并且不断增长,这意味着这些对象仍然被引用,GC无法回收它们。然而,单独生活几代并不足以导致泄漏,因为缓存或静态对象可能会停留几代。另一个重要因素是它们不断增长。
在检测到哪个对象被泄露后,您可以使用堆哑来分析这些对象并获取引用。

首先,通过添加标志-XX:NativeMemoryTracking=summary,使JVM本机内存跟踪器能够了解内存的哪个部分在增加。根据文档,有一些性能开销(5-10%),但如果这不是问题,我建议运行JVM时启用此标志,即使在生产环境中也是如此。
然后可以使用jcmd检查这些值
如果确实分配了一大块本机内存,那么很可能是Netty分配的。
您如何在AWS中运行您的应用程序?如果它在Docker映像中运行,您可能会偶然发现这个问题:什么会导致java进程大大超过Xmx或Xss限制?如果是这种情况,如果您的应用程序使用本地内存(Netty就是这样做的)并在具有大量内核的服务器上运行,您可能需要设置环境变量MALLOC_ARENA_MAX。JVM完全有可能为Netty分配这个内存,但看不出有任何理由释放它,所以它看起来只会继续增长。
如果您想控制Netty可以分配多少本机内存,可以使用JVM标志-XX:MaxDirectMemorySize(我认为默认值与Xmx)并降低它,以防应用程序不需要那么多内存。
JVM内存优化是一个复杂的过程,当涉及本机内存时,它会变得更加复杂——正如链接的答案所示,它不像简单地设置Xms和Xmx标志并期望不再使用内存那么容易。
-
我遇到了这样一个查询:在Netty4.0中创建一个关于从byte[]到ByteBuf以及从ByteBuffer到ByteBuf的转换的ByteBuf。我很想通过另一种方式了解转换: io.netty.buffer.ByteBufjava.nio.ByteBuffer 以及如何高效地执行此操作,而不进行复制?我读了一些书,经过反复试验,我发现这种转换方式效率低下(有两份副本): 我的问题是,我们可以
-
我在groovy类中有一个Restendpoint,其方法签名如下...... 是一个。在我的post请求中,我传递json。 如果我这样做,我可以看到参数(注意:我知道这是在java样式循环中打印字符串。这不是我想要的)...... 我想要的是一种转换使用groovy读取一个漂亮的Json对象,然后从Json对象读取属性? 谢谢
-
我试图理解DirectByteBuffer如何在Linux上工作,并编写了以下在strace下运行的非常简单的程序: 实际上,我期望一些mmap或sys\u brk系统调用直接从操作系统分配内存,但实际上它只是设置请求页面的读写保护。我的意思是: 这似乎是分配直接缓冲区比分配堆缓冲区慢的原因,因为每次分配都需要系统调用。 如果我错了,请纠正我,但是堆缓冲区分配(如果发生在TLAB内部)相当于返回一
-
SPARK 2.3抛出以下异常。有人能帮忙吗!!我试着加入罐子 308 [驱动程序] 错误 org.apache.spark.deploy.yarn.ApplicationMaster - 用户类抛出异常:java.lang.NoSuchMethodError: io.netty.buffer.PooledByteBufAllocator.metric()Lio/netty/buffer/Pool
-
当我研究线程及其占用的内存(线程堆栈)时,我决定做一个简单的负载测试,看看线程的数量如何影响我的计算机上的RAM。 所以,在测试中,我使用了Tomcat,在设置中。xml将最小和最大web容器线程池设置为200。在那之后,我在将pool设置为2000时也做了同样的操作。我很震惊,因为内存占用没有差异(通过Windows任务管理器进行检查),而且几乎是一样的。所以我认为这些线程可能必须处于运行状态,
-
我并不了解Java特别是Java调试,但在Jenkins中使用Monitoring进行堆转储,然后在Eclipse中使用MAT对其进行解码,显示总内存使用量为169.4MB,而在Jenkins中Monitoring似乎经常使用内存,GCs也经常运行。-XMX是4G。 为什么我只有169.4MB的mat?可能是因为在进行转储之前,Jenkins执行了GC吗?如果是,我是否可以避免它以看到完整的内存转