
Spark:如何在保存到cassandra时配置writetime

我有一个类似于卡桑德拉表的实体。我正在使用火花将数据保存/更新到卡桑德拉中。这里的实体是提供案例类
case class Offer(offer_id: String, metadata_last_modified_source_time: Timestamp, product_type: String, writeTime: util.Date)
val offerDataset: Dataset[Offer] = ....
我将这些数据保存如下
offerDataset.write.format("org.apache.spark.sql.cassandra")
.options(Map("keyspace" -> cassandraKeyspace, "table" -> tableName))
.mode(SaveMode.Append)
.save()
cassandra表的模式是
OFFER(offer_id, metadata_last_modified_source_time, product_type)
问题是在保存/更新cassandra表时,将Offer实体的writeTime字段配置为写入时间戳。这是在《税务》中提到的-https://github.com/datastax/spark-cassandra-connector/blob/master/doc/reference.md配置
writetime=columnName
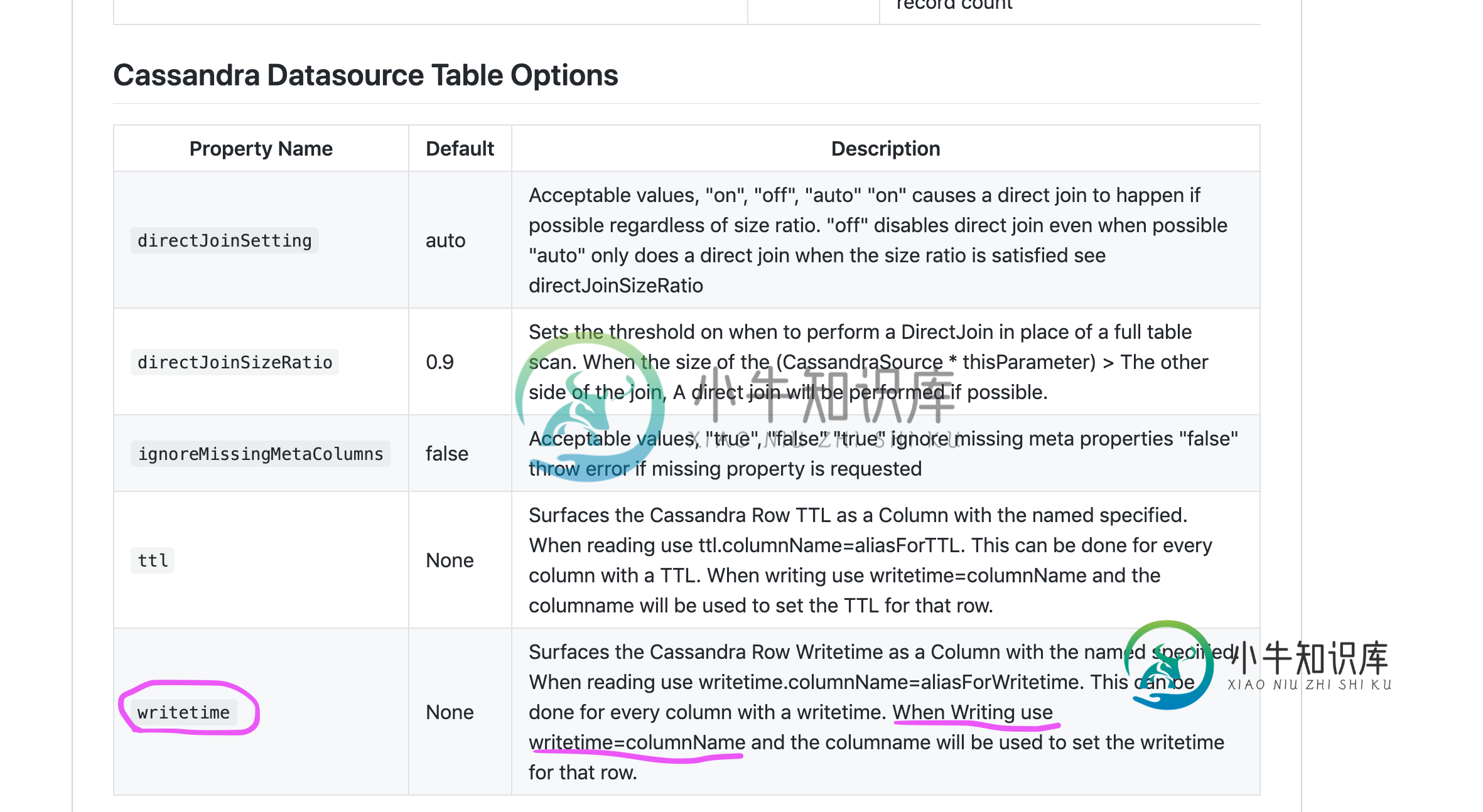
我不明白的是语法应该是什么样子。
任何帮助都将不胜感激
共有1个答案

本文档适用于Spark Cassandra连接器的alpha版本,因此请期待出现一些不起作用的情况。正如文档中所指出的,这是一个表格选项,因此您可以通过选项设置它。只需从util切换即可。日期到时间戳或长类型-Spark SQL不支持从日期类型进行编码。
使用以下定义一切工作:
import java.time.Instant
import java.sql.Timestamp
case class Offer(offer_id: String, metadata_last_modified_source_time: Timestamp,
product_type: String, writeTime: Long)
val offerDataset = Seq(Offer("123", Timestamp.from(Instant.now()), "test", 1243124234L),
Offer("456", Timestamp.from(Instant.now()), "test", 12431242366L)).toDF
或者使用Timestamp:
case class Offer(offer_id: String, metadata_last_modified_source_time: Timestamp,
product_type: String, writeTime: Timestamp)
val offerDataset = Seq(Offer("123", Timestamp.from(Instant.now()), "test", new Timestamp(1243124234L)),
Offer("456", Timestamp.from(Instant.now()), "test", new Timestamp(12431242366L))).toDF
如果我们使用以下表格结构:
create table test.wrt_test (
offer_id text,
metadata_last_modified_source_time timestamp,
product_type text,
primary key(offer_id, metadata_last_modified_source_time));
然后可以将数据保存为以下格式(仅在3.0-alpha中!):
import org.apache.spark.sql.SaveMode
import org.apache.spark.sql.cassandra._
offerDataset.write.cassandraFormat("wrt_test", "test")
.option("writetime", "writeTime") // here you specify name of the column with time!
.mode(SaveMode.Append).save()
但是,如果您使用RDD API,它在当前版本中也可以正常工作:
import com.datastax.spark.connector.writer._
offerDataset.rdd.saveToCassandra("test", "wrt_test",
writeConf = WriteConf(timestamp = TimestampOption.perRow("writeTime")))
在这两种情况下,你都会得到以下结果:
cqlsh> select offer_id, metadata_last_modified_source_time, product_type, writetime(product_type) from test.wrt_test;
offer_id | metadata_last_modified_source_time | product_type | writetime(product_type)
----------+------------------------------------+--------------+-------------------------
123 | 2020-04-16 07:28:38.905000+0000 | test | 1243124234
456 | 2020-04-16 07:28:38.905000+0000 | test | 12431242366
(2 rows)
-
我有一个spring-boot-starter-data-cassandra版本为2.1.2.release的Spring Boot应用程序。需要理解spring data Cassandra在执行insert选项时如何在实体中内部处理null。使用方法持久化这些实体。在某些情况下,这些实体的少数字段可能为空。这种方法是否会影响Cassandra的性能或墓碑可能在Cassandra中创建。或者请建
-
问题内容: 有什么方法可以在Git或其他任何地方保存管道配置或项目配置,以便当我的Jenkins机器崩溃时,我可以在新的Jenkins实例中迁移保存的配置? 问题答案: 我会(作为一个开始)让自己-https: //wiki.jenkins.io/display/JENKINS/JobConfigHistory+Plugin保留对Jobs,System config等所做的所有更改的历史记录-已为
-
使用Spark Cassandra连接器,我有一个情况,我想使用UPDATE如果表中存在,如果表中不存在,则忽略。 然而,我不清楚这是否可以在Spark Cassandra连接器中完成。有人知道这怎么做吗?
-
如何为版本设置以下属性: 本质上,我想设置它,以便应该有0个连接到我的远程dc的客户端,也应该有0个读/写。一切都应该是我正在磨合的DC本地的。 将设置为本地DC是否会达到相同的效果?
-
我正在处理一个包含uni_key和createdDate两列的数据帧。我运行一个SQL查询并将结果保存到中,现在我想将这些结果保存到csv文件中。有什么方法可以做到这一点吗?这是一个代码片段: 此代码当前出现以下错误: AttributeError:“DataFrameWriter”对象没有属性“csv”
-
当我将大数据保存到hdfs时,我正在体验OOME 我在Spark-Submit中使用这个: 当我增加框架时,现在的错误是:Java.lang.outofMemoryError:Java堆空间,所以我必须将驱动程序内存和执行程序内存增加到2G才能工作。如果累加Collection.value.length是500,000,我需要使用3G。这正常吗? 该文件只有146MB,包含200,000行(对于2