
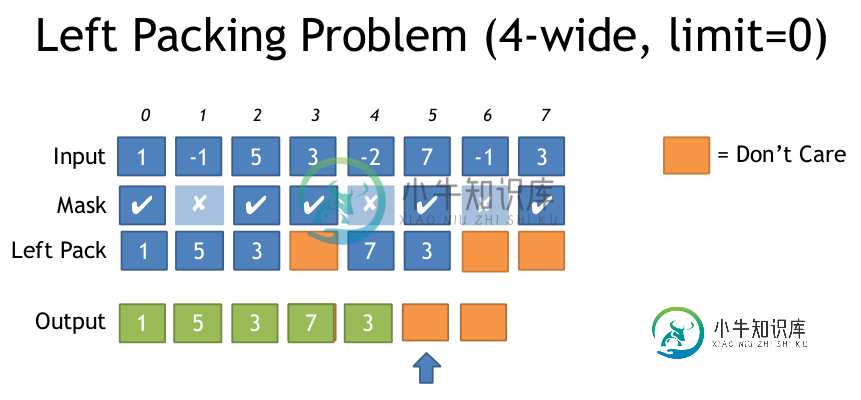
AVX2什么是最有效的方式包装左边的基础上一个面具?

如果你有一个输入数组和一个输出数组,但你只想写那些通过某个条件的元素,在AVX2中做这件事最有效的方法是什么?
__m128i LeftPack_SSSE3(__m128 mask, __m128 val)
{
// Move 4 sign bits of mask to 4-bit integer value.
int mask = _mm_movemask_ps(mask);
// Select shuffle control data
__m128i shuf_ctrl = _mm_load_si128(&shufmasks[mask]);
// Permute to move valid values to front of SIMD register
__m128i packed = _mm_shuffle_epi8(_mm_castps_si128(val), shuf_ctrl);
return packed;
}
对于4宽的SSE来说,这似乎很好,因此只需要一个16个条目的LUT,但是对于8宽的AVX,这个LUT变得相当大(256个条目,每个32字节,或者8K)。
我很惊讶,AVX似乎没有一个简化这个过程的指令,比如一个带包装的蒙面商店。
我认为通过一些位洗牌来计算设置在左边的符号位的数量,可以生成必要的排列表,然后调用_mm256_permutevar8x32_ps。但这也是相当多的指示,我认为…
谢谢
共有1个答案

AVX2+BMI2。请参见我对AVX512的另一个答案。(更新:以64位版本保存了pdep)
我们可以使用AVX2vpermps(_mm256_permutevar8x32_ps)(或等效的整数vpermd)来执行跨车道变量shuffle。
我们可以动态生成掩码,因为BMI2pext(Parallel Bits Extract)为我们提供了所需操作的按位版本。
对于具有32位或更宽元素的整数向量:1)_mm256_movemask_ps(_mm256_castsi256_ps(compare_mask).
或2)使用_mm256_movemask_epi8并将第一个PDEP常数从0x01010101010101更改为0x0f0f0f0f0f0f,以分散4个连续位的块。将乘法改为expanded_mask=expanded_mask<<4;或expanded_mask*=0x11;)。无论哪种方式,都可以使用带有VPERMD而不是vpermps的洗牌掩码。
对于64位整数或double元素,一切仍然正常工作;compare-mask碰巧总是有两对相同的32位元素,因此所产生的洗牌将每个64位元素的两个一半放在正确的位置。(所以您仍然使用VPERMPS或VPERMD,因为VPERMPD和VPERMQ只能与直接控制操作数一起使用。)
对于16位元素,可以使用128位向量进行调整。
对于8位元素,请参见左打包字节元素的高效sse洗牌掩码生成以获得另一个技巧,即将结果存储在多个可能重叠的块中。
从一个由3个位索引组成的常量开始,每个位置持有自己的索引。即[7 6 5 4 3 2 1 0],其中每个元素为3位宽。0b111'110'101'...'010'001'000。
如果我们使用每个字节一个索引,而不是打包的3位组,我们可以简化解包。由于我们有8个索引,这只有在64位代码中才可能。
在Godbolt编译器资源管理器上查看这个和一个仅32位的版本。我使用了#ifdefs,因此它可以使用-M64或-M32进行最佳编译。gcc浪费了一些指令,但clang的代码非常好。
#include <stdint.h>
#include <immintrin.h>
// Uses 64bit pdep / pext to save a step in unpacking.
__m256 compress256(__m256 src, unsigned int mask /* from movmskps */)
{
uint64_t expanded_mask = _pdep_u64(mask, 0x0101010101010101); // unpack each bit to a byte
expanded_mask *= 0xFF; // mask |= mask<<1 | mask<<2 | ... | mask<<7;
// ABC... -> AAAAAAAABBBBBBBBCCCCCCCC...: replicate each bit to fill its byte
const uint64_t identity_indices = 0x0706050403020100; // the identity shuffle for vpermps, packed to one index per byte
uint64_t wanted_indices = _pext_u64(identity_indices, expanded_mask);
__m128i bytevec = _mm_cvtsi64_si128(wanted_indices);
__m256i shufmask = _mm256_cvtepu8_epi32(bytevec);
return _mm256_permutevar8x32_ps(src, shufmask);
}
这将编译为没有从内存加载的代码,只有直接常量。(请参见godbolt链接以获得此版本和32bit版本)。
# clang 3.7.1 -std=gnu++14 -O3 -march=haswell
mov eax, edi # just to zero extend: goes away when inlining
movabs rcx, 72340172838076673 # The constants are hoisted after inlining into a loop
pdep rax, rax, rcx # ABC -> 0000000A0000000B....
imul rax, rax, 255 # 0000000A0000000B.. -> AAAAAAAABBBBBBBB..
movabs rcx, 506097522914230528
pext rax, rcx, rax
vmovq xmm1, rax
vpmovzxbd ymm1, xmm1 # 3c latency since this is lane-crossing
vpermps ymm0, ymm1, ymm0
ret
这可能可以管理每4个循环中一个的吞吐量,这是pdep/pext/imul加上popcnt在port1上的瓶颈。当然,由于加载/存储和其他循环开销(包括比较和movmsk),总uop吞吐量也很容易成为一个问题。
例如,我的godbolt链接中的filter循环是14个uops,带有clang,并带有-fno-unroll-loops,以便于阅读。如果我们幸运的话,它可能每4C支持一次迭代,跟上前端。
Clang6和更早的版本创建了一个循环携带的依赖项,其输出具有popcnt的假依赖项,因此它将限制compress256函数3/5的延迟。CLANG7.0和更高版本使用XOR零化来打破假依赖关系(而不是仅仅使用popcnt edx、edx或类似GCC:/)。
如果您需要在一个很长的循环中执行此操作,那么如果初始缓存未命中被分摊到足够多的迭代中,并且仅解包LUT条目的开销较低,那么LUT可能是值得的。您仍然需要movmskps,这样您就可以popcnt掩码并将其用作LUT索引,但是您保存了一个pdep/imul/pexp。
您可以使用我使用的相同整数序列解压缩LUT条目,但是@Froglegs的set1()/vpsrlvd/vpand可能更好,因为LUT条目在内存中启动并且不需要首先进入整数寄存器。(32位广播加载不需要英特尔CPU上的ALU uop)。然而,在Haswell上,可变移位是3个uops(但在Skylake上只有1个uops)。
-
问题内容: 在JavaScript中串联N个对象数组的最有效方法是什么? 数组是可变的,结果可以存储在输入数组之一中。 问题答案: 如果要连接两个以上的数组,那么这样做是为了方便和可能的性能。 对于仅连接两个数组,可以使用接受多个包含要添加到数组中的元素的参数的事实来代替将一个数组中的元素添加到另一个数组的末尾而不产生新数组。使用它也可以代替它,但是这样做似乎没有性能优势。 在ECMAScript
-
问题内容: 考虑数组 我可以做 但这需要找到所有对象才可以找到第一个。 有没有更有效的方法? 我一直在试图找出我是否可以传递参数,从而获取的第一个分类,而不是最后一次。 编辑关于[dup]。 有几个原因使这个问题不同。 该问题和答案涉及价值观的平等。这是关于。 这些答案都遭受我的答案面临的同一问题。注意,我提供了一个完全有效的答案,但强调了它的效率低下。我正在寻找解决效率低下的问题。 编辑有关第二
-
问题内容: 什么是最有效的Java Collections库? 几年前,我做了很多Java的工作,给人留下的印象是那个宝库是最好(最有效)的Java Collections实现。但是,当我阅读“最有用的免费Java库? ”这个问题的答案时,我注意到几乎没有提到trove。那么,哪个Java Collections库现在最好? 更新:为澄清起见,我主要想知道当我必须在哈希表等中存储数百万个条目时使用
-
问题内容: 我有一个图片,稍后会使用javascript用src动态填充该图片,但为简便起见,我希望该图片标签在页面加载时存在,但什么也不显示。我知道这是无效的,那么最好的方法是什么? 问题答案: 虽然没有有效的方法来省略图像的来源,但是 有些 来源不会导致服务器命中。我最近对s 遇到了类似的问题,并确定是最佳选择。不完全是! 从开始(省略协议)开始,将使用当前页面的协议,从而防止HTTPS页面中
-
问题内容: 我有一个相当大的数据集和一个需要两个联接的查询,因此查询的效率对我来说非常重要。我需要根据联接的结果从数据库中检索3个满足条件的随机行。这里指出最明显的解决方案效率低下,因为 [这些解决方案]需要对所有表进行顺序扫描(因为需要计算与每一行关联的随机值-以便可以确定最小的行),即使对于中等大小的表也可能相当慢。 但是,那里的作者建议的方法(其中num_value是ID)对我不起作用,因为
-
问题内容: 给定一个表(daily_sales),其中包含以下数据/列的10万行: 编写报告(使用SQL完整显示所有名称的两个最新条目(代表,销售,日期))的最有效方法是什么,因此输出将是: 谢谢! 问题答案: 对于MySQL,在 @Quassnoi的博客 中进行了解释,该索引是使用和使用的: