
跨多个节点的服务节点端口

我在库伯内特斯集群中运行3个节点。每个节点都有相同的Pod myApp。我使用NodePort类型创建一个服务,以便所有3个节点都可以从外部访问。服务yaml如下所示
apiVersion: v1
kind: Service
metadata:
name: myService
labels:
app: myApp
spec:
selector:
app: myApp
type: NodePort
假设3个节点的节点IP端口为:
1.192.168.18.1:30010
2.192.68.18.2:30010
3.192.18.18.3:30010
我的问题是:<br>1.如果所有请求都来自IP为(192.168.18.1:30010)的单个节点,服务是否会将请求负载平衡到其他节点,或仅目标节点(IP 192.168.18.1:30010)
2.如果问题1的答案为“是”,则表示服务可以请求负载平衡。那么我们还需要任何负载平衡器吗。
谢啦
共有1个答案

>
是的,负载平衡将由kube代理提供。如果您通过描述服务来查看endpoint,您会发现该服务支持的POD的IP列在那里。因此,当请求到达任意节点IP和NodePort时,kube代理将在这些Pod之间进行负载平衡。它的工作方式是,请求到达节点IP和端口之一,然后到达集群IP,然后在集群IP后面的任何POD上实现负载平衡。
kube代理通过IP表规则在TCP层进行负载平衡。Loadbalancer在L7层(HTTP)提供负载平衡,并基于HTTP标头等提供高级路由规则。因此,如果需要,则需要使用LoadBalanceer。使用nodeport的另一个缺点是,如果节点IP发生变化,则客户端需要知道这一点,这可以通过使用通常提供DNS的负载平衡器来避免。
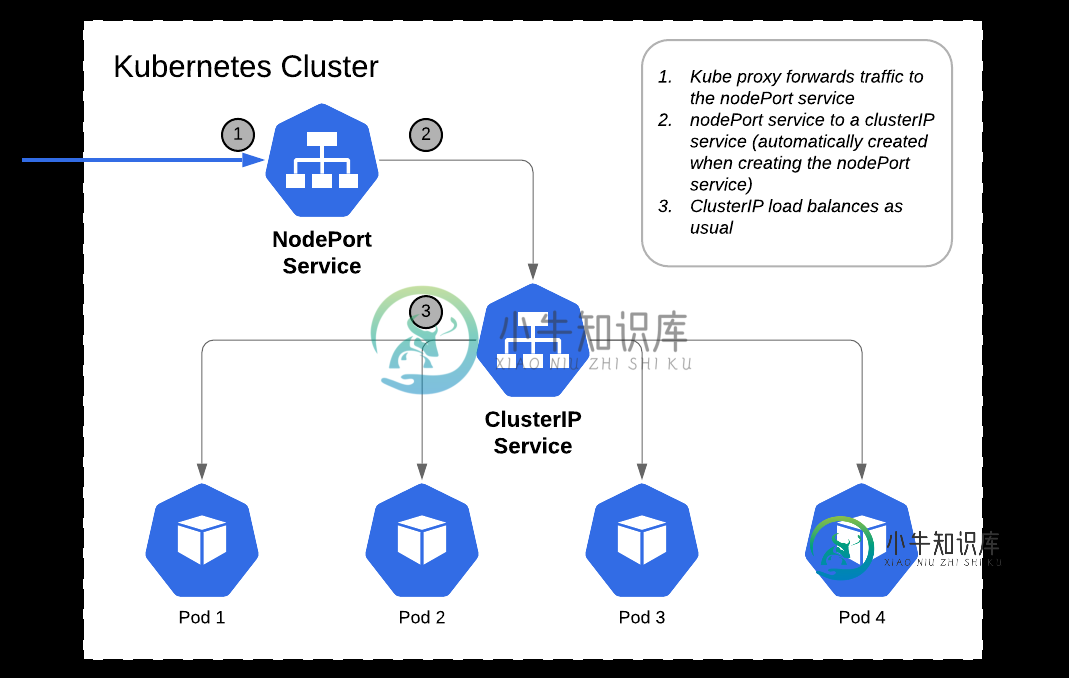
-
我有一个这样的结构` ...等等,在
-
我有一个LoadBalancer服务,它在群集外公开3300端口。我想打开一个新的端口用于内部通信,以便其他吊舱可以与此服务对话,但此端口不应暴露在集群外部。 基本上,通信如下所示:
-
我有 2 个 docker 容器运行我的 Web 应用程序和机器学习应用程序,都使用 h2o。最初,我既调用 h2o.init() 又指向同一个 IP:PORT,因此初始化了一个具有一个节点的 h2o 集群。 考虑到我已经训练了一个模型,现在我正在训练第二个模型。在此训练过程中,如果web应用程序调用h2o集群(例如,从第一个模型请求预测),它将终止训练过程(错误消息如下),这是无意的。我尝试为每
-
假设我们有一个具有10个GPU和40个CPU核的单个节点。这是否可以用来将节点拆分成10个节点,每个节点有4个核心,每个GPU,并带有显式的CPU/GPU绑定?如果是,配置需要是什么样子的?
-
问题内容: ElasticSearch中如何有多个节点?我在elasticsearch.yml中使用以下内容,但只有最后一个节点启动,浏览器抱怨:。 问题答案: 我认为最简单的方法是在命令行上指定这些参数。要启动三个节点,您只需要在elasticsearch主目录中运行以下三个命令: 另一个解决方案是创建3个不同的配置文件,并使用参数启动三个节点。
-
Java编译器特性、服务缓存以及一些初始化操作,使服务一般在刚启动时响应较慢。所以服务端启动时如果不想在注册完成后,立即被调用端按照配置权重打入流量,则可以通过设置预热时间让流量慢慢进来,从而减少因服务节点启动带来的耗时长引发失败率可能变高的问题。 实现方式是服务端将预热时间写入注册中心,调用端在服务发现后根据预热时间和服务节点启动时间计算出当前时刻的权重,随着时间的增长线性增加该节点的权重,由此