
Elasticsearch analizer在创建throw Springdata时工作,但在直接从Postman/curl创建时失败

目标:创建Elasticsearch索引,目标是加载1000万个简单文档。每个文档基本上都是“ElastiSearch ID”、“某个公司ID”和“名称”。提供suer-type搜索功能。
我可以直接从Postman(curl或任何其他不依赖Spring数据的工具)或在Spring Boot初始化期间成功地创建索引和分析器。然而,当我试图使用模拟,它似乎是忽略了一个直接从邮递员创建。
所以我的主要问题是:Springdata是否添加了一些设置,当我直接发布json stting时,我忽略了这些设置?第二个问题是:有没有办法让Springdata打印自动生成和执行的命令(类似于Hibernate whihc的方法,允许您看到打印的命令)?如果是这样,我可以直观地调试并检查有什么不同。
@EnableElasticsearchRepositories
@SpringBootApplication
public class SearchApplication {
public static void main(String[] args) {
SpringApplication.run(SearchApplication.class, args);
}
}
@Document(indexName = "correntistas")
@Setting(settingPath = "data/es-config/elastic-setting.json")
@Getter
@Setter
public class Correntista {
@Id
private String id;
private String conta;
private String sobrenome;
@Field(type = FieldType.Text, analyzer = "autocomplete_index", searchAnalyzer = "autocomplete_search")
private String nome;
}
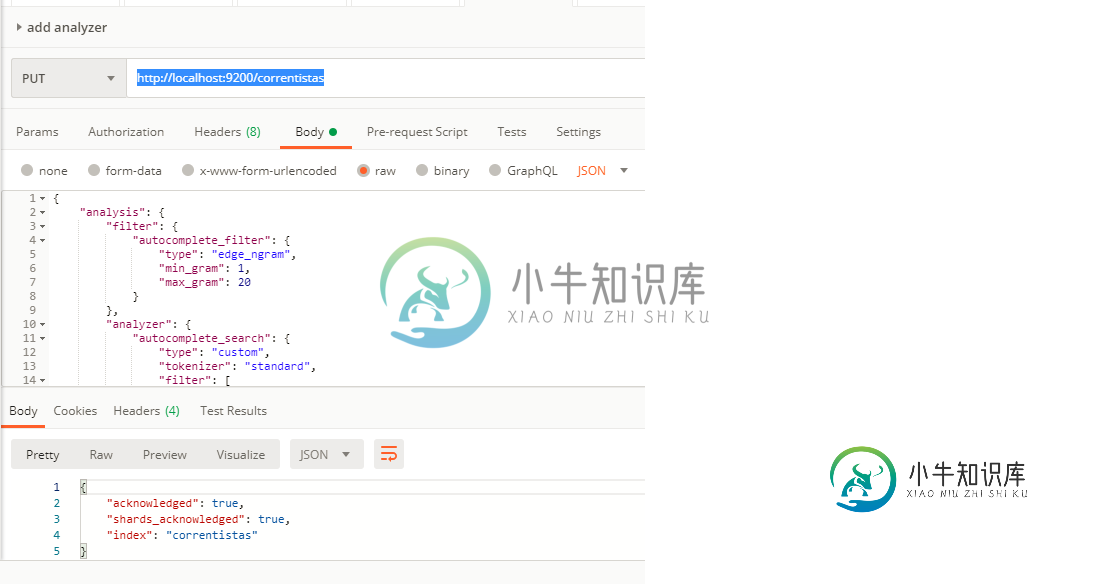
src/main/resources/data/es-config/ellastic-setting.json***注意这与我从POSTMAN发布的设置完全相同
{
"analysis": {
"filter": {
"autocomplete_filter": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 20
}
},
"analyzer": {
"autocomplete_search": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase"
]
},
"autocomplete_index": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"autocomplete_filter"
]
}
}
}
}
检查它是否成功创建,我看到:
get http://localhost:9200/correntistas/_settings
{
"correntistas": {
"settings": {
"index": {
"number_of_shards": "5",
"provided_name": "correntistas",
"creation_date": "1586615323459",
"analysis": {
"filter": {
"autocomplete_filter": {
"type": "edge_ngram",
"min_gram": "1",
"max_gram": "20"
}
},
"analyzer": {
"autocomplete_index": {
"filter": [
"lowercase",
"autocomplete_filter"
],
"type": "custom",
"tokenizer": "standard"
},
"autocomplete_search": {
"filter": [
"lowercase"
],
"type": "custom",
"tokenizer": "standard"
}
}
},
"number_of_replicas": "1",
"uuid": "xtN-NOX3RQWJjeRdyC8CVA",
"version": {
"created": "6080499"
}
}
}
}
}
到目前为止还好。
***感谢Opster Elasticsearch忍者如此友好和聪明的帮助,我可以在这里添加一个额外的技巧,我从邮递员那里发帖时学到的(不知何故,我的邮递员中启用的一些标题崩溃了,出现了“...根映射定义有不支持的参数...Mapper_Parsing_Exception...”,同时尝试了下面的解决方案。我想在这里添加对未来的读者来说是有用的。
共有1个答案

由于您没有提供您在postman中使用的搜索查询,也没有提供映射,这将有助于我们调试,如果您没有在您的搜索查询中使用的字段上使用正确的分析器。此外,添加示例文档以及实际的和预期的搜索结果总是有帮助的。
Nvm,我在下面添加了你的映射和显示,如何使用邮递员以及,你会得到正确的结果。
索引def和你的完全一样
{
"settings": {
"analysis": {
"filter": {
"autocomplete_filter": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 20
}
},
"analyzer": {
"autocomplete_search": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase"
]
},
"autocomplete_index": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"autocomplete_filter"
]
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "autocomplete_index",
"search_analyzer": "autocomplete_search"
}
}
}
}
{
"name" : "opster"
}
{
"name" : "jim c"
}
{
"name" : "jimc"
}
{
"name" : "foo"
}
{
"query": {
"match": {
"name": {
"query": "ji"
}
}
}
}
"hits": [
{
"_index": "61158504",
"_type": "_doc",
"_id": "2",
"_score": 0.69263697,
"_source": {
"name": "jimc"
}
},
{
"_index": "61158504",
"_type": "_doc",
"_id": "1",
"_score": 0.6133945,
"_source": {
"name": "jim c"
}
}
]
-
我正在使用现有的Java代码,其中在部署的系统上有一个现有的JDBC连接池机制,并且有一个已经存在的获取JDBC连接的设置。我想利用这一点来创建MyBatis SqlSession对象,而不创建配置、数据源和其他东西 我的代码已经创建了对象,并为其提供了所需的资源。我想利用这一点,获得对象,并从此使用MyBatis。 我不希望MyBatis管理连接池,确定使用哪个数据源等等,这可能吗?
-
WordPress有一个管理仪表板。在仪表板中,我们可以作为管理员添加新用户。我想在管理员添加新用户时在MySQL中创建一个表。例如,我创建了一个名为John Smith的用户,其用户名为user1;当我成功添加该用户时,将在名为user1的数据库中创建一个表。
-
我正在尝试dockerize一个Spring启动服务。我开始参考这篇文章。我能够建立图像,但不能运行它。当我试图运行容器时,它失败了,错误如下。 OCI运行时创建失败:container_linux.go:345:启动容器进程导致\“exec:\\”catalina.sh\\“:在$path\”中找不到可执行文件:未知 我使用的是Windows10Docker桌面,我尝试使用其他基本图像,重置Do
-
通常kafka-configs.sh用于创建SCRAM凭据,以便使用此命令进行身份验证 有没有其他方法可以创建这些凭证,直接在zookeeper上或者通过Java?
-
我有一个具有以下版本的 Kubernetes 集群: 我有一个cron工作在我的库伯内特斯集群。 库伯内特斯集群识别cron作业的api资源。 我正在尝试为此创建一个手动作业,但是遇到了这个错误。 谁能帮忙?