
无法使用Azure表单识别器从身份证中提取键值对信息

我正在使用表单识别器客户端库。NET从一个国家的国民身份证中提取数据。但它似乎无法从卡中获取键值对。我跟着https://docs.microsoft.com/en-us/azure/cognitive-services/form-recognizer/quickstarts/dotnet-sdk辅导的
我发现只有一个键值对,值数组包含所有的标签/文本(键和值)。
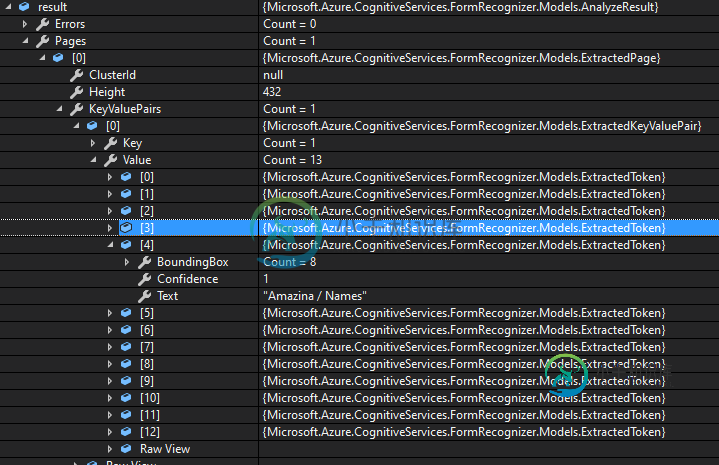
我需要用另一种方法从身份证中提取信息吗?我是否需要使用标签工具培训带有标签的模型?
共有2个答案

请注意。NET SDK目前支持表单识别器v1.0-预览版,但尚未支持表单识别器v2.0-预览版。请按照以下快速入门使用标签进行训练-https://docs.microsoft.com/en-us/azure/cognitive-services/form-recognizer/quickstarts/label-tool

是的,请尝试使用标签进行培训。
-
我正在使用来自识别器的Azure进行发票处理项目。所有发票均为PDF格式。我正在使用带有标签的自定义表单识别器。我可以从PDF中提取一些数据,如发票号、发票日期、金额等,但我想使用Azure Form Recognitor从PDF中提取表格数据,但它无法正确读取表格。 我已经标记了我需要的单元格,当表中的行数增加时,它会正确读取列,但是它无法将每行的值彼此分开,并将整列作为单个值返回。 我试图提供
-
我在用https://docs.microsoft.com/en-us/azure/cognitive-services/form-recognizer/quickstarts/curl-train-extract在不使用标签的情况下构建培训模型。 我遇到的问题是,当我通过模型运行一个文件(该文件用于训练模型)时,它没有拾取“表”部分。我的意思是,没有“表”节点。 据我所见,它应该能够将其构建为J
-
身份证识别是利用手机相机扫描二代身份证,然后通过OCR文字识别技术,将图像转换为文字,得到规范的证件信息文本。 1.功能介绍 支持身份证正反面识别。 可返回人脸截图。 可返回身份证裁剪图上的姓名和身份号码的区域位置。 支持蒙文、藏文、维文、壮文版身份证。 支持竖屏、横屏扫描(注:需在初始化时指定方向)。 扫描界面可定制。 2.身份证识别流程 3.身份证识别 SDK-Demo 当进行身份证识别时,我
-
身份证识别是利用手机相机扫描二代身份证,读取证件上的各栏位信息,然后通过 OCR 文字识别技术,将图像转换为文字,得到规范的证件信息文本。 1.功能介绍 支持身份证正反面识别。 可返回人脸截图。 可返回姓名、身份号码区域位置。 支持蒙文、藏文、维文、壮文版身份证。 支持竖屏、横屏扫描,在初始化时指定方向。 扫描界面可定制。 2.身份证识别流程 3.身份证识别 SDK-Demo 当进行身份证识别时,
-
我有这个代码在一个网页我试图刮与硒: 我试图实现这样的方法(我在SO上找到的)来获得至少一个id: 这样: 它不起作用。我假设我应该使用,但不能使用getAttribute。如何提取所有id的列表?谢谢
-
我有不同类型的pdf,其中包含多个内容,如文本,表格等。该表可以存在于pdf的任何位置(顶部,中间,底部)。我只想提取表数据(不。的列,没有。行数 到目前为止我所做的工作:- 1.我使用了iText java API来读取和提取。使用以下代码:- pdftextextractor . gettextfrompage 但它只是以文本形式返回数据。没有得到任何线索来确定表格在pdf中的位置以及如何从该