
从Azure Blob存储下载大Blob已冻结

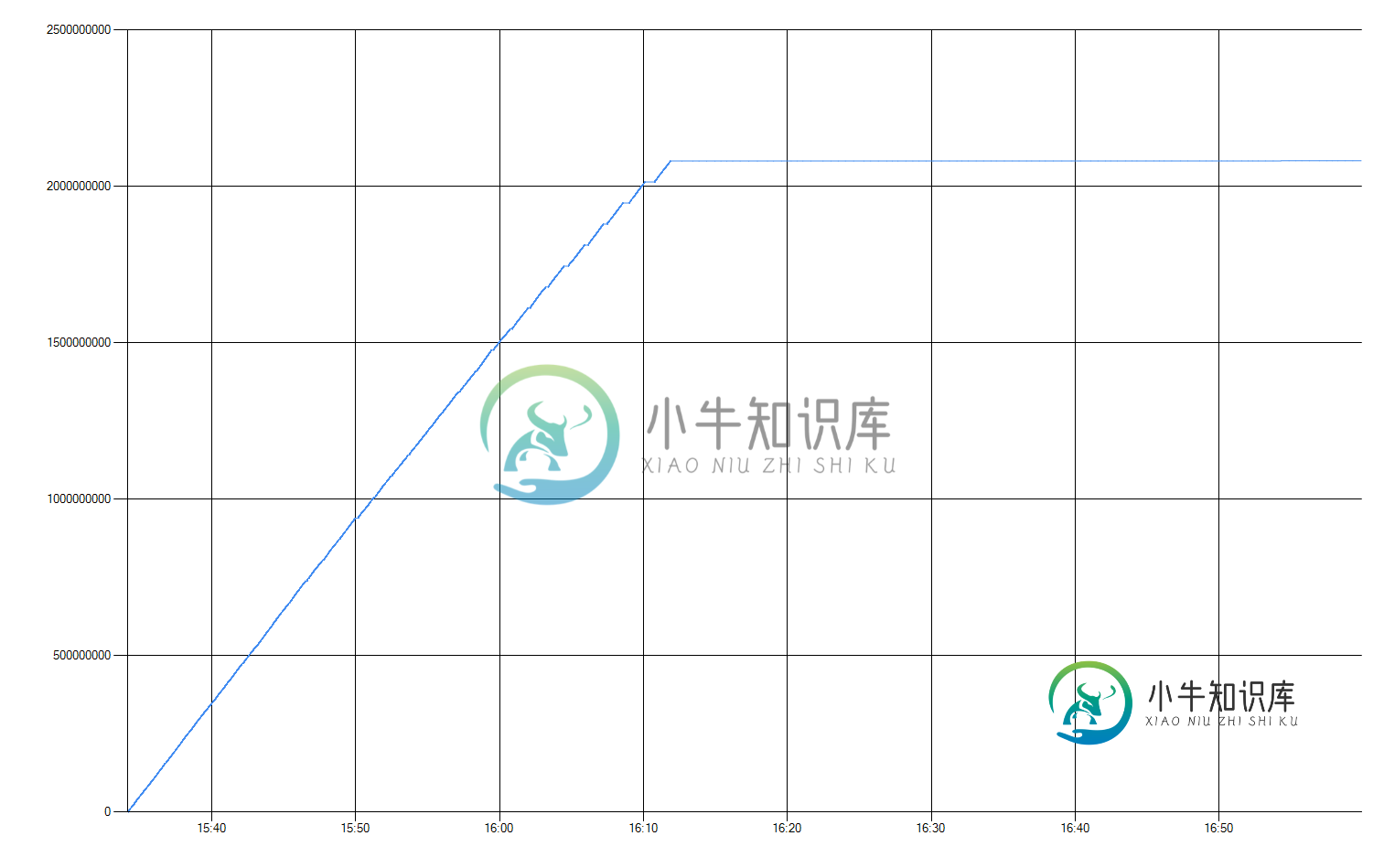
从16:00到16:12,下载有短暂的暂停。停顿之间的间隔是相同的,但长度会增加。在 16:12 时,速度变为 Kb/s,并且永远不会返回到正常值。
下面是进行下载的代码(。NET 4.0):
CloudBlobContainer container = new CloudBlobContainer(new Uri(containerSAS));
CloudBlockBlob blockBlob = container.GetBlockBlobReference(blobName);
var options = new BlobRequestOptions()
{
ServerTimeout = new TimeSpan(10, 0, 0, 0),
RetryPolicy = new LinearRetry(TimeSpan.FromMinutes(2), 100),
};
blockBlob.DownloadToStream(outputStream, null, options);
这些问题的原因可能是什么?
编辑 为了获取统计信息,我使用以下 Stream 实现:
public class TestControlledFileStream : Stream
{
private StreamWriter _Writer;
private long _Size;
public TestControlledFileStream(string filename)
{
this._Writer = new StreamWriter(filename);
}
public override void Write(byte[] buffer, int offset, int count)
{
_Size += count;
_Writer.WriteLine("{0}: ({1}, {2})", DateTime.UtcNow, _Size, count);
}
protected override void Dispose(bool disposing)
{
if (this._Writer != null)
this._Writer.Dispose();
}
}
共有1个答案

看起来您在下载大blob时遇到问题。我在下面提供了一些步骤来帮助您调试这些问题。
快速评论:您不需要为此下载指定线性重试策略。默认指数重试策略应该足以满足您的方案。通过将此重试策略允许的失败次数设置为100,您可能会延长重试无法解决的问题。您选择使用线性重试有什么原因吗?
调试Azure存储问题
- 存储分析日志是调试中有用的第一步,因为它们
为您提供有关请求的信息,例如服务器延迟或
响应状态代码。您可以在此处查看哪些信息可用,并在此处了解如何使用日志记录。 - 客户端日志记录提供了客户端特定的信息,可以帮助您缩小问题。
- 在您的客户端上使用Fiddler可以提供下载状态的可见性,例如客户端是否正在重试。请注意,这可能会混淆速度或连接问题,因为流量将通过代理运行流量。
如果您获得有关此问题的更多详细信息,我们将能够帮助您缓解您的问题。
-
我能够通过Node/Express将文件上传到Azure blob存储,没有任何问题,但我找到了关于如何下载文件的非常少的文档/完整示例。我在教程页面上找到了这个,但是运气不好: 是否有其他人使用node.js/express从Azure blob存储下载文件?您是否使用Azure或其他方法(例如请求)。您能否分享如何从Azure获取文件并将其流式传输到文件夹?
-
我可以成功地上传到Azure Blob存储,但我在下载文件(csv和pdf文件)时遇到了问题。 我的目标是将文件下载到浏览器(因为这将是一个web应用程序,我不知道下载文件的本地路径)。
-
你能帮我从下载中重命名吗?
-
我正在使用 Pyspark 尝试从 blob 存储中读取 zip 文件。我想在加载后解压缩文件,然后将解压缩的 CSV 写回 Blob 存储。 我正在遵循以下指南,该指南解释了一旦读取如何解压缩文件:https://docs.databricks.com/_static/notebooks/zip-files-python.html 但是它不能解释我是如何从blob中读取zip文件的。我有以下代码
-
简要背景:我有一个在Azure Blob存储中存储文件的web服务。该服务的用户可以一次下载多个文件。如果下载的所有文件的总文件大小相对较小,那么我在服务器上压缩文件并返回该压缩文件--这里没有问题。 场景:例如,如果一个用户想要下载3个每个1GB的文件,那么我将这些文件下载到服务器是不现实的,将它们压缩,然后将压缩文件返回到浏览器。因此,对于这些场景,我将Azure Blob Storage U