
如何计算每个NAME/LOCATION每月的平均积雪量,然后将结果保存在Python中的. CSV文件中?

对于每个名称/位置,计算每月的平均降雪量。将结果保存在两个单独的文件夹中。csv文件(一个用于2016年,另一个用于2017年)将文件命名为average2016。csv和平均值2017。csv。
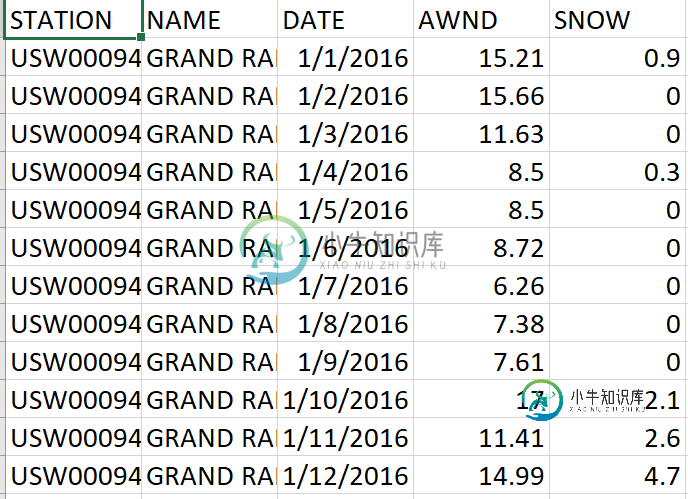
我正在使用Python3.8和pandas。
我尝试过以下代码:
import numpy as np
import pandas as pd
df = pd.read_csv('filteredData.csv')
df['DATE'] = pd.to_datetime(df['DATE'])
df['year'] = pd.DatetimeIndex(df['DATE']).year
df['month'] = pd.DatetimeIndex(df['DATE']).month
df16 = df[(df.year == 2016)]
df17 = df[(df.year == 2017)]
df_2016 = df16.groupby(df.month).mean()
df_2017 = df17.groupby(df.month).mean()
df_2016.to_csv('average2016.csv', index=False)
df_2017.to_csv('average2017.csv', index=False)
然而,它并没有完全按照我的要求去做。这是所有地点每月的平均降雪量的总和。然而,我需要每个名字/地点每月的平均降雪量。我如何才能得到每个名字/地点每个月的平均降雪量,然后将结果分别保存到2016年和2017年。CSV文件?
共有2个答案

df.groupby(['month','NAME','LOCATION']).SNOW.mean()
或
df.groupby(['year','month','NAME','LOCATION']).SNOW.mean()

如果你想要每个月每个名字/地点的平均降雪量,你必须在这两列上分组:
df_2016 = df16.groupby(['NAME', 'month']).mean()
-
对于filteredData中的每个名称。csv,计算每月的平均降雪量。将结果保存在两个单独的文件夹中。csv文件(一个用于2016年,另一个用于2017年)将文件命名为average2016。csv和平均值2017。csv。 我正在使用Python 3.8与熊猫。我尝试过: 但是我得到的只是错误。我不知道从哪里开始。 这是Filteredata的一小部分。csv
-
我需要计算每行的平均值,并存储在最后一个元素中。我设法做到了,但后面的行是前一行的累计平均值。例如: 输入: 1 2 3 0 4 5 6 0 输出: 1.00 2.00 3.00 2.00 4.00 5.00 6.00 7.00(应为5.00) 这是我的代码 提前谢谢。:)
-
问题内容: 已关闭 。这个问题需要细节或说明。它当前不接受答案。 想改善这个问题吗? 添加详细信息并通过编辑此帖子来澄清问题。 11个月前关闭。 改善这个问题 我有一个清单: 我想要另一个具有三个值均值的列表,因此新列表为: 新列表中只有6个值,因为第一个元素中只有18个元素。 我正在寻找一种精巧的方法来完成此操作,并为大量列表提供最少的步骤。 问题答案: 您可以在3个间隔中迭代使用for循环
-
Python3 实例 以下代码通过导入 calendar 模块来计算每个月的天数: # Filename : test.py # author by : www.runoob.com import calendar monthRange = calendar.monthrange(2016,9) print(monthRange) 执行以上代码输出结果为: (3, 30) 输出的是一个元
-
有没有一种方法可以简化或使R代码更优雅?
-
问题内容: 我有一张表,如下所示: 我从中创建以下视图: 现在,当我想创建每月计数以了解如何将每日总和除以得出平均列a(即特定月份中的天数)时,就会出现问题。 我知道要在PostgreSQL中获得成功,您可以: 但是我不能使用,我必须以某种方式让它知道分组完成的月份。任何建议,即什么应该取代 ??? 在此视图中: 问题答案: 更快,更短一点,您得到的是天数,而不是: 可以将多个单位合并为一个值。因