
使用Python中的selenium从浏览器下载文件

我知道这个问题已经被问了好几次了,但这些问题的解决方案对我的情况没有帮助。
我想从这个网站下载一个数据集:https://datadashboard.fda.gov/ora/cd/inspections.htm
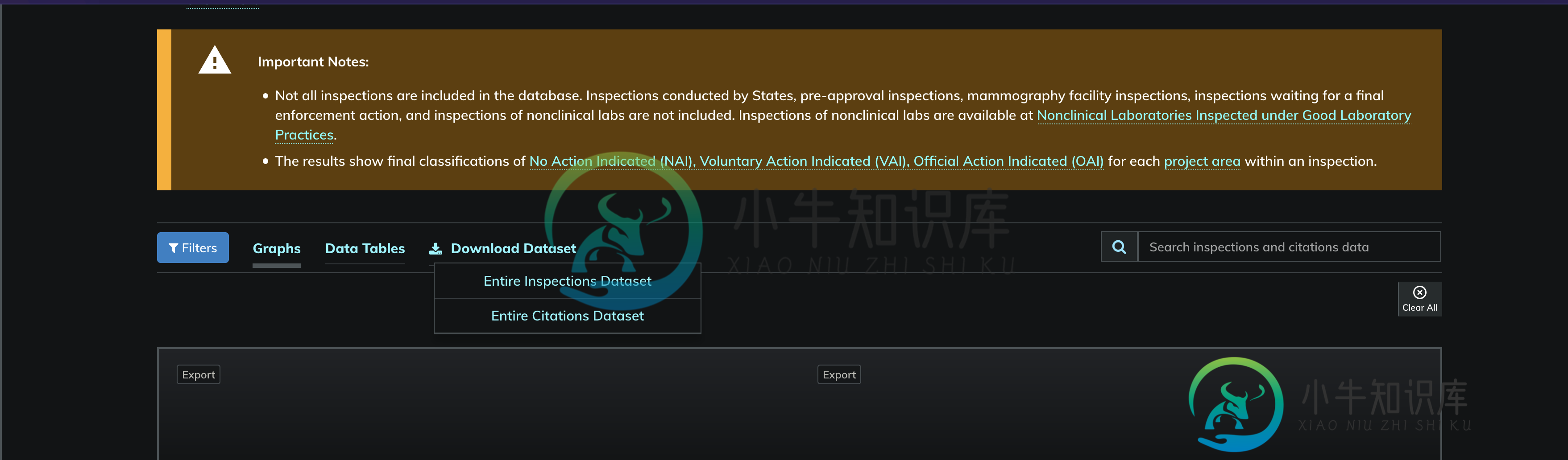
以下是“数据集”的HTML:

以下是“整个检测数据集”的 HMTL:
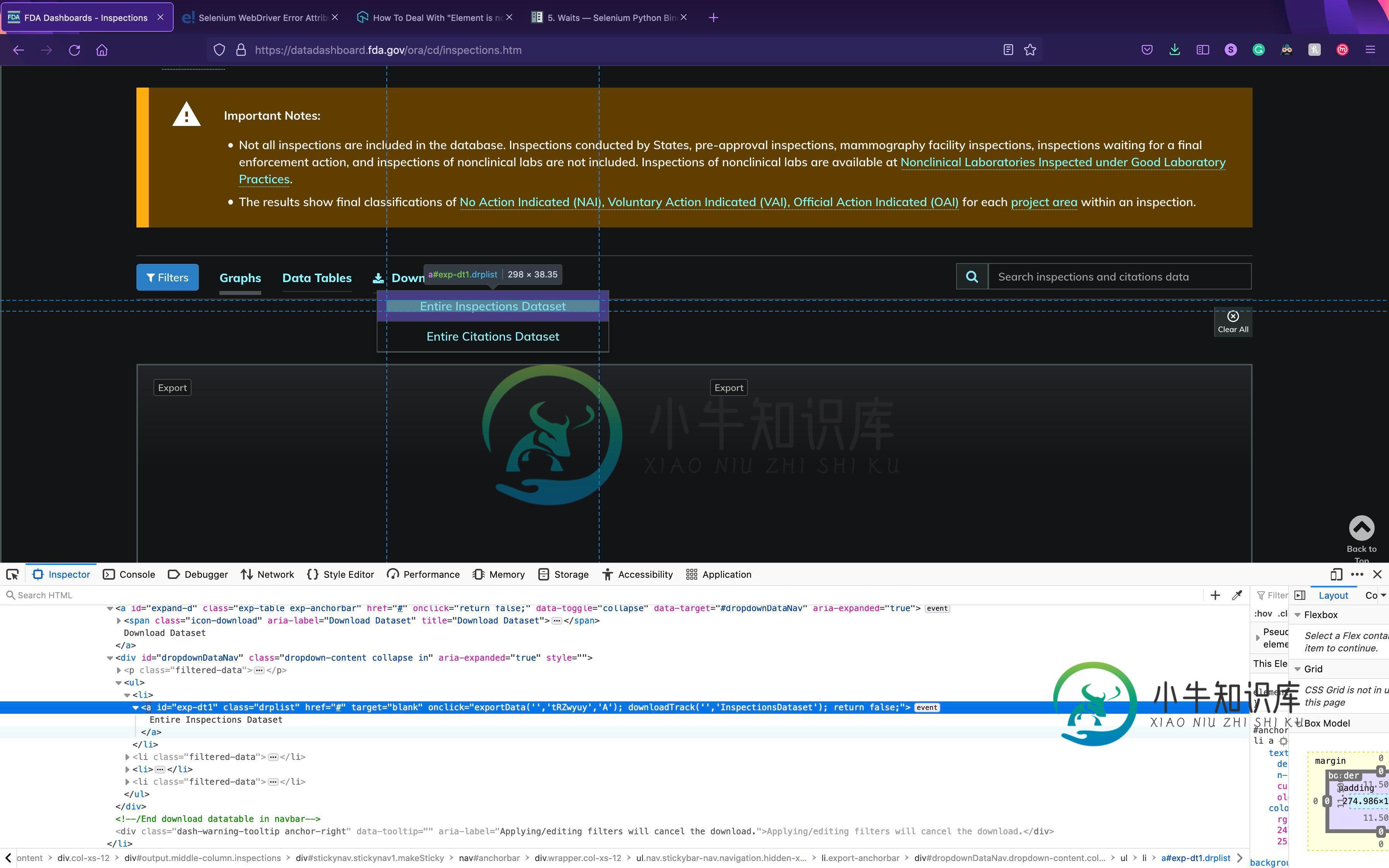
下面是我获取数据集的代码:
iconDownload = driver.find_element_by_xpath('//*[@id="expand-d"]').click()
WebDriverWait(driver, 60).until(expected_conditions.visibility_of_element_located((By.ID, "expand-d")))
downloadDataset = driver.find_element_by_xpath('//*[@id="exp-dt1"]')
downloadDataset.click()
WebDriverWait(driver, 120, 1).until(checkDownload)
我也尝试过:
iconDownload = driver.find_element_by_css_selector("span[class=\'icon-download\']").click()
但我得到这个错误:
文件“FDAComplianceDashboardInspections-GetFileHash.py”,第68行,在保存搜索结果图标下载=driver.find_element_by_xpath('//*[@id=“expand-d”]')单击() 文件“/主页/开发用户/代码/数据来源/venv/lib/python3.6/站点包/硒/网络驱动程序/远程/网络.py”,第80行,点击self._execute(Command.CLICK_ELEMENT)文件“/主页/开发用户/代码/数据来源/venv/lib/python3.6/站点软件包/硒/网络驱动程序/远程/网络.py”,第633行,_execute返回self._parent执行(命令,参数) 文件“/主页/devuser/code/data-source/venv/lib/python3.6/站点包/硒/web驱动程序/远程/web驱动程序.py”,第321行,在执行self.error_handler.check_response(响应) 文件“/主页/devuser/代码/数据源/venv/lib/python3.6/站点包/硒/web驱动程序/远程/错误处理程序.py”,第242行,check_response引发exception_class(消息,屏幕,堆栈跟踪)硒。常见.异常.WebDriver例外:消息:未知错误:元素在点 (400, 759) 不可单击(会话信息:无外设铬=65.0.3325.181)(驱动程序信息:铬驱动程序= 2.37.544315 (730aa6a5fdba159ac9f4c1e8cbc59bf1b5ce12b7),平台=Linux 5.10.25-linuxkit x86_64)
注意:我已经尝试了find_element_by_id,find_element_by_class,find_element_by_css_selector,但是都没有用。
这是我第一次使用硒,非常感谢帮助解决这个问题。
共有1个答案

你能检查一下这个吗,希望对你有用
driver.get("https://datadashboard.fda.gov/ora/cd/inspections.htm")
driver.maximize_window()
driver.find_element_by_id("expand-d").click()
driver.execute_script("window.scrollBy(0,400)");
time.sleep(15)
driver.find_element_by_link_text("Entire Inspections Dataset").click()
-
我想运行和控制一个浏览器窗口从一个web应用程序,以自动化的一些事情(如帐户创建等)在另一个网站。 所以我的问题是,有没有一种方法可以直接从浏览器使用selenium来实现它,在这种情况下如何实现它? 我知道有selenium-webdriver for JS,但在常见的用例中,我们将它与Node.JS一起使用。 WebDriver介绍建议这是可能的: 它的主要目的是允许web作者编写测试,使用户
-
我的用例:我必须从pdf中读取数据,而不是在chrome浏览器中打开,并检查pdf中是否存在一些特定的数据。 由于我无法做到以上,我想到下载文件在我的电脑上,并使用PDFbox进行验证。我创建了一个chrome配置文件,带有直接下载pdf文件的设置(设置>内容设置>pdf文档)。我已经在我的selenium脚本中将其设置为chrome选项。测试工作,但当pdf打开时,它不会开始下载。PDF文件在我
-
我正在使用Selenium和Chrome来模拟点击一个下载PDF文件的按钮。一切工作如预期,Chrome显示下载成功,点击Chrome上的文件打开并充分显示文件。但是,当我试图从文件管理器或任何其他应用程序(包括作为超级用户的)访问该文件时,下载的文件并不存在。这是硒/铬故意做的吗?有什么办法可以绕过这一点吗? 我在Xubuntu 20.04.2 LTS上运行Python 3.8.5。Seleni
-
我需要在chrome浏览器上模拟文件下载,下面的链接指向我正在寻找的解决方案。 http://ardesco.lazerycode.com/index.php/2012/07/how-to-download-files-with-selenium-and-why-you-shouldnt/ https://github.com/Ardesco/Ebselen/blob/master/ebselen
-
问题内容: 我的Selenium Webdriver转到页面并等待该页面完成加载。如果30秒过去,它将超时并且脚本失败。 无论如何,是否要让网络驱动程序在30秒后停止页面加载(例如按浏览器中的“ x”)?这样可以防止驱动程序超时。 我正在使用Chromedriver。 问题答案: 这就是我遇到此问题的方式。在chrome支持之前,我将使用这种方式。 我在Chrome中安装了一个名为“停止加载”的扩
-
我的selenium webdriver转到一个页面,等待该页面完成加载。如果超过30秒,则超时,脚本失败。 是否需要webdriver在30秒后停止页面加载(如按浏览器上的“x”)?这将防止我的司机超时。 我正在使用ChromeDrive。