
试图处理s3文件时的OOM

我试着用下面的代码从文件中下载和读取数据,不管怎么说,在读取文件时,s3文件的大小是22MB,我通过浏览器下载的是650MB,但是当我通过visual VM监控时,解压缩和读取时消耗的内存超过2GB。任何人请指导,让我找到高内存使用率的原因。谢了。
public static String unzip(InputStream in) throws IOException, CompressorException, ArchiveException {
System.out.println("Unzipping.............");
GZIPInputStream gzis = null;
try {
gzis = new GZIPInputStream(in);
InputStreamReader reader = new InputStreamReader(gzis);
BufferedReader br = new BufferedReader(reader);
double mb = 0;
String readed;
int i=0;
while ((readed = br.readLine()) != null) {
mb = mb+readed.getBytes().length / (1024*1024);
i++;
if(i%100==0) {System.out.println(mb);}
}
} catch (IOException e) {
e.printStackTrace();
LOG.error("Invoked AWSUtils getS3Content : json ", e);
} finally {
closeStreams(gzis, in);
}
线程“main”Java.lang.outofMemoryError:unzip(awsutils.Java:917)
共有1个答案

这是一个理论,但我想不出你的例子会失败的任何其他原因。
假设未压缩文件包含一个很长的行;例如,大约6.5亿个ASCII字节。
您的应用程序似乎每次只读取文件一行,并(尝试)显示已读取的兆字节的运行总数。
所以650MB可以很容易地变成>6×650M字节的堆需求
另一件需要注意的事情是,2×N数组必须是单个连续的堆节点。
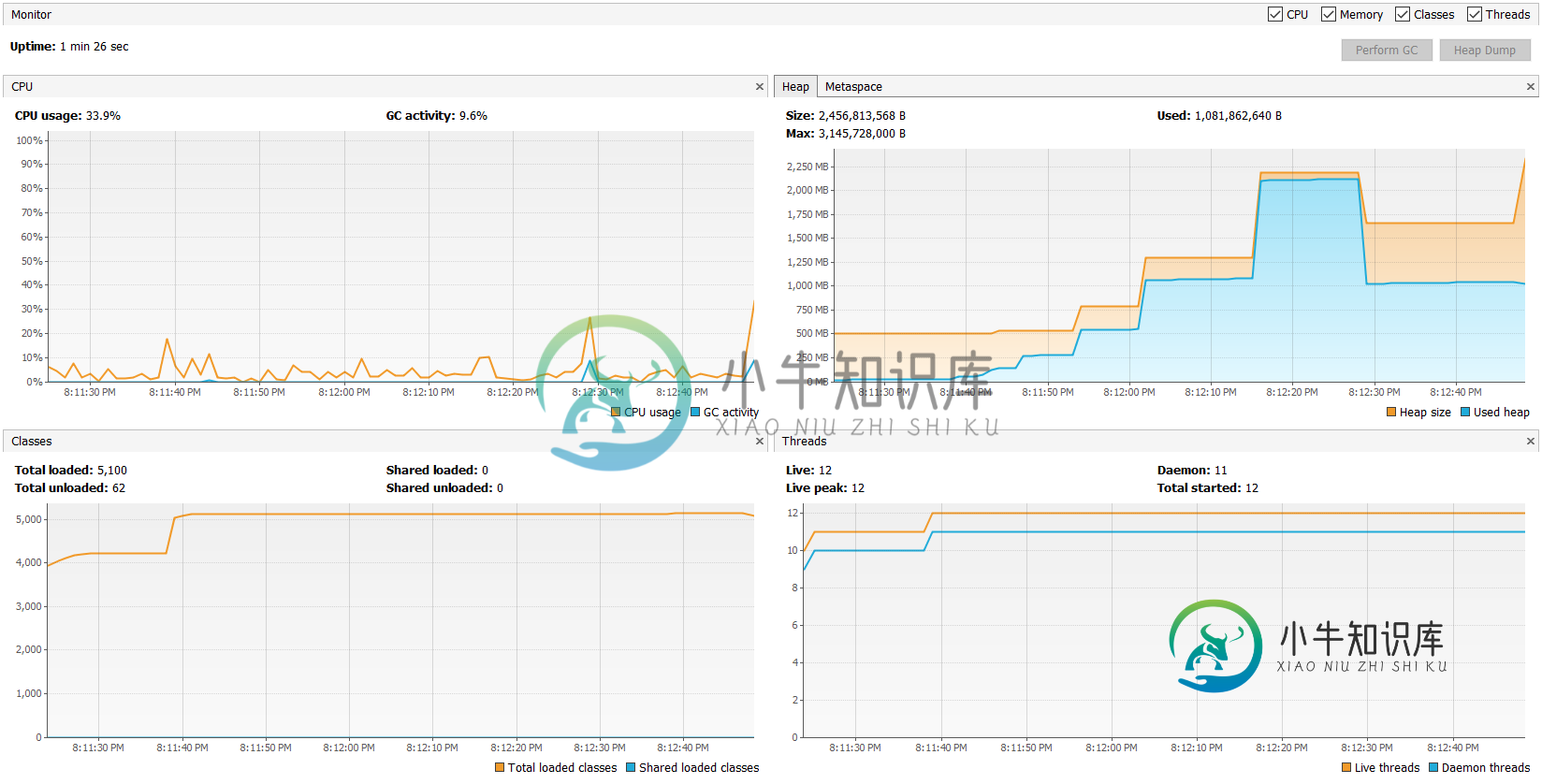
查看堆图,看起来堆在使用中达到了1GB。如果我的理论是正确的,下一个分配将是一个~2GB的节点。但是对于3.1GB的堆最大值来说,1GB+2GB是正确的。当我们考虑到连续性要求时,分配就无法进行了。
public static String unzip(InputStream in)
throws IOException, CompressorException, ArchiveException {
System.out.println("Unzipping.............");
try (
GZIPInputStream gzis = new GZIPInputStream(in);
InputStreamReader reader = new InputStreamReader(gzis);
BufferedReader br = new BufferedReader(reader);
) {
int ch;
long i = 0;
while ((ch = br.read()) >= 0) {
i++;
if (i % (100 * 1024 * 1024) == 0) {
System.out.println(i / (1024 * 1024));
}
}
} catch (IOException e) {
e.printStackTrace();
LOG.error("Invoked AWSUtils getS3Content : json ", e);
}
-
目前,我将不得不手动转录,这是不理想的。 谢了!
-
是否有可能使用TYPO3的图像操作工具在TYPO3后端裁剪图像,以便在前端也为PDF文件使用? 图像操作工具只显示消息: 无法确定图像尺寸。 无法提供图像操作,因为图像的原始尺寸未知。 也许我需要另一个服务器端模块?但是我找不到关于这个话题的任何信息。
-
这是如何使用公共类frome的一个后续步骤。其他处理选项卡中的java文件?;使用来自的Usage类中的示例。java文件-有完整的文档吗?-处理2。x和3。x论坛,我有这个: /tmp/Sketch/Foo.java 这个例子运行得很好,但是如果我取消注释import peasy。组织 行,则编译失败: 当然,我确实在下安装了PeasyCam,如果我导入peasy.*它工作得很好 来自草图。 我
-
python-magic
-
gulp 暴露了 src() 和 dest() 方法用于处理计算机上存放的文件。 src() 接受 glob 参数,并从文件系统中读取文件然后生成一个 Node 流(stream)。它将所有匹配的文件读取到内存中并通过流(stream)进行处理。 由 src() 产生的流(stream)应当从任务(task)中返回并发出异步完成的信号,就如 创建任务(task) 文档中所述。 const { sr
-
对于大文件,s3上的dask read_csv超时 有超时异常,如果文件很小,那么它就可以正常工作。 我认为我们需要一种设置s3fs的方法。S3FileSystem.read_timeout在远程工作人员,而不是本地代码,但我不知道如何做到这一点。 以下是堆栈跟踪的一部分: 文件"/opp/conda/lib/python3.6/site-包/dask/bytes/utils.py",第238行,