
没有文件被发送到SAP Leonardo图像特征提取API使用FormData

我正在测试SAP Leonardo图像特征提取API(https://sandbox.api.sap.com/ml/featureextraction/inference_sync)。我有图像的bas64字符串,我想将其转换为文件对象并压缩,然后使用XMLHttpRequest将压缩后的图像文件发送到该API。但是响应文本是“服务需要(压缩)图像列表”。
我在下面的截图中附上我的HTTP请求头和参数。
虽然我们在参数中看到了混乱的代码,但这里的压缩文件下载成功创建。
如果无法下载压缩文件,请参考下面的屏幕截图。
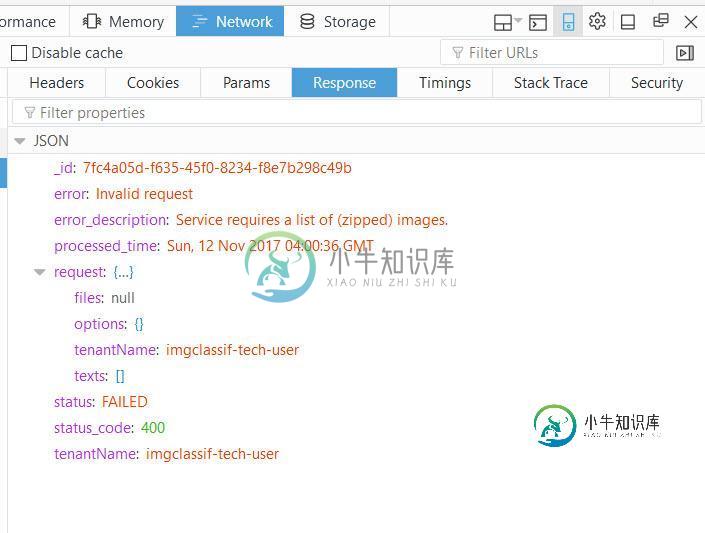
一切似乎都很好。然而,回复文本如下,状态为400。
我的javascript代码如下所示。怎么了?这让我疯狂。。。
js lang-js prettyprint-override">dataURItoBlob: function(dataURI, fileName) {
//convert base64/URLEncoded data component to raw binary data held in a string
var byteString;
if (dataURI.split(',')[0].indexOf('base64') >= 0)
byteString = atob(dataURI.split(',')[1]);
else
byteString = unescape(dataURI.split(',')[1]);
//separate out the mime component
var mimeString = dataURI.split(',')[0].split(':')[1].split(';')[0];
//write the bytes of the string to a typed array
var ia = new Uint8Array(byteString.length);
for (var i = 0; i < byteString.length; i++) {
ia[i] = byteString.charCodeAt(i);
}
var blob = new Blob([ia], {encoding:"UTF-8",type:mimeString});
//A Blob() is almost a File() - it's just missing the two properties below which we will add
blob.lastModifiedDate = new Date();
blob.name = fileName + '.' + mimeString.split('/')[1];
return blob;
},
onSubmit: function(oEvent) {
var oImage = this.getView().byId('myImage');
//oImage.getSrc() : 'data:image/png;base64,iVBORw0KGgo...'
var imageFile = this.dataURItoBlob(oImage.getSrc(), 'myImage');
var zip = new JSZip();
zip.file(imageFile.name, imageFile);
zip.generateAsync({
type:"blob",
compression: 'DEFLATE', // force a compression for this file
compressionOptions: {
level: 6,
},
}).then(function(content) {
//saveAs(content, "hello.zip");
// start the busy indicator
var oBusyIndicator = new sap.m.BusyDialog();
oBusyIndicator.open();
var formData = new FormData();
formData.append('files', content, 'myImage.zip');
var xhr = new XMLHttpRequest();
xhr.withCredentials = false;
xhr.addEventListener("readystatechange", function () {
if (this.readyState === this.DONE) {
oBusyIndicator.close();
//navigator.notification.alert(this.responseText);
console.log(this.responseText);
}
});
//setting request method
//API endpoint for API sandbox
//Destionation '/SANDBOX_API' in HCP is configured as 'https://sandbox.api.sap.com'
var api = "/SANDBOX_API/ml/featureextraction/inference_sync";
xhr.open("POST", api);
//adding request headers
xhr.setRequestHeader("Content-Type", "multipart/form-data");
xhr.setRequestHeader("Accept", "application/json");
//API Key for API Sandbox
xhr.setRequestHeader("APIKey", "yQd5Oy785NkAIob6g1eNwctBg4m1LGQS");
//sending request
xhr.send(formData);
});
},
共有1个答案

我自己解决这个问题。我提出我的解决方案只是为了让别人知道。这很简单,在发送请求之前只需删除下面的代码。我不知道为什么。如果你知道原因,请提出建议。提前谢谢!
xhr.setRequestHeader("Content-Type", "multipart/form-data");-
在机器学习中,灰度图像的特征提取是一个难题。 我有一个灰色的图像,是用这个从彩色图像转换而来的。 我实际上需要从这张灰色图片中提取特征,因为下一部分将训练一个具有该特征的模型,以预测图像的彩色形式。 我们不能使用任何深度学习库 有一些方法,如快速筛选球。。。但我真的不知道如何才能为我的目标提取特征。 以上代码的输出就是真的。 有什么解决方案或想法吗?我该怎么办?
-
问题内容: 我的问题是可以使用ajax(jquery)将图像上传到服务器吗 以下是我的ajax脚本,无需重新加载页面即可发送文本 是否可以修改它以发送图像? 问题答案: 这可行。 是您要找的东西吗?
-
Spark特征提取(Extracting)的3种算法(TF-IDF、Word2Vec以及CountVectorizer)结合Demo进行一下理解 TF-IDF算法介绍: 词频-逆向文件频率(TF-IDF)是一种在文本挖掘中广泛使用的特征向量化方法,它可以体现一个文档中词语在语料库中的重要程度。 词语由t表示,文档由d表示,语料库由D表示。词频TF(t,,d)是词语t在文档d中出现的次数。文件频率D
-
校验者: @if only 翻译者: @片刻 模块 sklearn.feature_extraction 可用于提取符合机器学习算法支持的特征,比如文本和图片。 Note 特征特征提取与 特征选择 有很大的不同:前者包括将任意数据(如文本或图像)转换为可用于机器学习的数值特征。后者是将这些特征应用到机器学习中。 4.2.1. 从字典类型加载特征 类 DictVectorizer 可用于将标准的Py
-
在许多任务中,例如在经典的垃圾邮件检测中,你的输入数据是文本。 长度变化的自由文本与我们需要使用 scikit-learn 来做机器学习所需的,长度固定的数值表示相差甚远。 但是,有一种简单有效的方法,使用所谓的词袋模型将文本数据转换为数字表示,该模型提供了与 scikit-learn 中的机器学习算法兼容的数据结构。 假设数据集中的每个样本都表示为一个字符串,可以只是句子,电子邮件或整篇新闻文章
-
卷积神经网络包括主要特征,提取。以下步骤用于实现卷积神经网络的特征提取。 第1步 导入相应的模型以使用“PyTorch”创建特征提取模型。 第2步 创建一类特征提取器,可以在需要时调用。