
Azure Databricks-无法从笔记本中读取简单的blob存储文件

我用databricks runtime Version5.1(包括Apache Spark 2.4.0、Scala 2.11)和Python 3建立了一个集群。我还在集群中安装了hadoop azure库(Hadoop-Azure-3.2.0)。
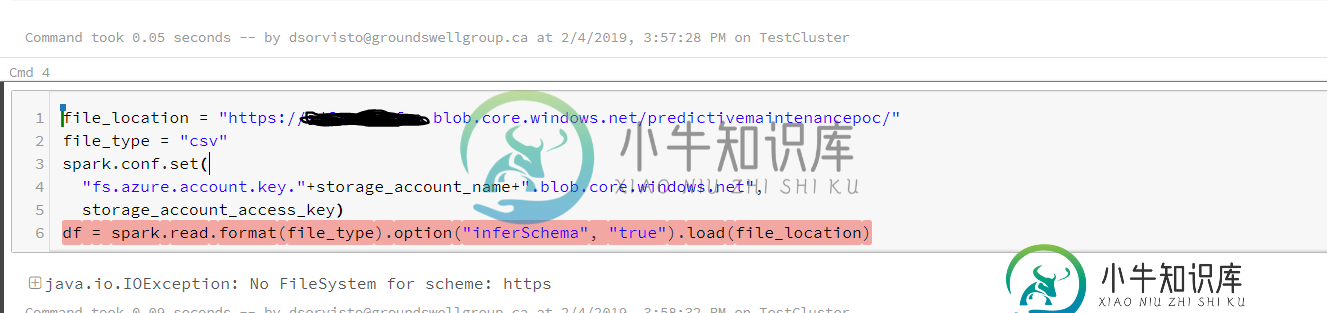
我试图读取存储在blob存储帐户中的blob,它只是一个文本文件,包含一些用空格分隔的数字数据。我使用databricks生成的模板来读取blob数据
spark.conf.set(
"fs.azure.account.key."+storage_account_name+".blob.core.windows.net",
storage_account_access_key)
df = spark.read.format(file_type).option("inferSchema", "true").load(file_location)
其中file_location是我的blob文件(https://xxxxxxxxxx.blob.core.windows.net)。
我尝试使用sc.textfile(file_location)读取rdd并得到相同的错误。
共有1个答案

您的file_location应该采用以下格式:
"wasbs://<your-container-name>@<your-storage-account-name>.blob.core.windows.net/<your-directory-name>"
参见:https://docs.databricks.com/spark/latest/data-sources/azure/azure-storage.html
-
编写了通过Spark读取文本文件的代码...在Local中运行良好...但在HDInsight中运行时产生错误->从Blob读取文本文件 org.apache.spark.sparkException:作业由于阶段失败而中止:阶段0.0中的任务0失败了4次,最近的失败:阶段0.0中丢失的任务0.3(TID 5,wn1-hchdin.bpqkkmavxs0ehkfnaruw4ed03d.dx.int
-
我正在尝试将数据从Azure存储容器加载到Azure Databricks中的Pysark数据帧。当我阅读txt或CSV文件时,它正在工作。但当我尝试读取.xlsx文件时,我会遇到以下问题。 Apache Spark 3.2.0,Scala 2.12 以下是我正在执行的步骤 它正在工作 不工作 加载xlsx文件时出现以下错误: 注意:我能够从dbfs和挂载点读取。
-
问题内容: 我需要在存储过程中读入由SSIS包创建的日志文件。 有什么好方法吗? 我尝试使用此代码,但将文件内容显示为乱码。有没有解决的编码问题?有没有更简单的方法? 问题答案: 您是否尝试过将笔直插入?例如:
-
当我试图从Google Cloud Storage(App Engine、Python和Standard Env)中读取文件内容(纯文本)时,我会得到以下跟踪: 虽然设置了“公开共享”,但我在默认的bucket中工作(根据我的理解,应用程序应该具有完全的权限),并且我能够将内容写入/上传到相同的文件中。
-
我正在通过一个对我来说是新的IDE进行一个学校项目:IntelliJ。 为了提交我的项目(通过git),我创建了一个git存储库,添加了正确的remote及其密码,并尝试将我的工作推到主分支(在成功添加/提交所述工作之后)。 一开始我收到以下错误消息: 推送失败:失败,错误:致命:无法从远程存储库读取。 下面是我的文件: 我哪里错了?