
角度 7 在下载 blob 时获取损坏的文件

使用Angular 7,我通过发布url文件来调用api,并尝试使用文件保护程序中的“saveAs”函数下载它。文件正在下载,但由于已损坏而无法打开。
我的电话如下:
var file_url = (response as any).headers['Location'] + 'files/Data.xlsx';
var filename = 'Data_' + this.getDateService.getDateFile() + '.xlsx';
const httpOptions = {
headers: new HttpHeaders({
'Content-Type': 'application/x-www-form-urlencoded'
}),
responseType: 'arraybuffer',
observe: 'response'
};
let downloadParameters = { filename: 'Data_' + this.getDateService.getDateFile() + '.xlsx', file: file_url }
this.downloadFileService.downloadFile(downloadParameters, httpOptions).subscribe(reponse => {
var blob = new Blob([(response as any).body], { type: 'application/vnd.openxmlformat-officedocument.spreadsheetml.sheet' });
saveAs(blob, filename);
})
我试过什么:
- 切换类型 MIME 应用程序/vnd.openxml格式-office文档.电子表格.工作表 按应用程序/八位字节流
- 切换响应类型数组缓冲区由 blob 或 blob 作为 json
下面是来自服务的响应标头:
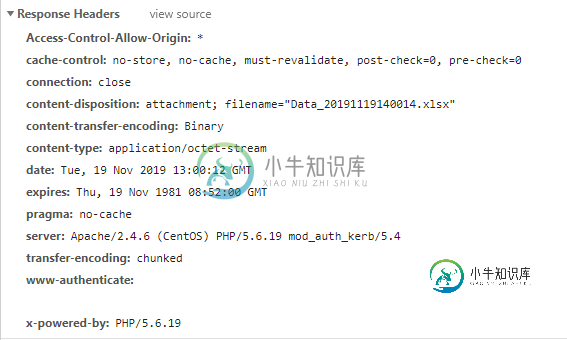
文件存在于响应正文中:
你们有什么线索吗?
共有1个答案

试试这个:
this.downloadFileService.downloadFile(downloadParameters, { responseType: 'blob' }).subscribe(blob=> {
saveAs(blob, filename);
})
-
我编写的下载文件的方法总是产生损坏的文件。 我通过adb访问这些文件,将它们传输到我的sccard,在那里我看到它们似乎有合适的大小,但没有根据例如Linux命令的类型。 你知道丢失了什么以及如何修复它吗? 谢谢。 代码的简单版本(但错误相同) 日志:< code > file . length:2485394 | content length:1399242 问题是,我从我的API单例中获得了,
-
我试图通过调用Spring RESTendpoint在Reactjs中下载Excel文件,但我遇到了损坏文件的问题。 回应呼叫... Spring控制器…… 服务 当我执行上面的代码,我得到一个Excel文件o. k……但看response.data看起来像…… 嘎嘎��由于数据不可读,无法打开文件。打开服务器上创建的文件是可以的 欢迎任何想法 干杯
-
问题内容: 我正在使用角度$ http从服务器下载文件。文件类型可以不同。我应该设置请求标头以进行身份验证。下载完成后,文件已损坏!这是我在客户端保存文件的代码: 问题答案: 我最终通过将以下配置添加到ajax请求中解决了该问题: 并将Blob类型更改为 “应用程序/八位字节流”
-
问题内容: 我有以下代码将页面附件带给用户: 问题是所有受支持的文件都可以正常工作(jpg,gif,png,pdf,doc等),但是.docx文件在下载时已损坏,需要通过Office进行修复才能打开。 起初我不知道问题是否出在解压缩包含.docx的zip文件,所以我没有保存输出文件,而是先保存了文件,然后成功打开了文件,所以我知道问题所在应该在回应写作中。 你知道会发生什么吗? 问题答案: 我也遇
-
由此下载的文件大小几乎相同,但在某些行中有所不同。每个答案都指向二进制文件类型。但这没用。有人对这个问题有什么想法吗?
-
问题内容: 我正在使用getObject api从AWS s3下载文件。简单的文本文件可以正常工作,但是在pdf下载上我的文件已损坏。我正在使用FileOutputStream并将内容保存在文件中,但是保存的pdf损坏了。 我不太确定用于此目的的正确Java API,读取的字节要写入的字节数组的大小应该是多少。 我也很好奇,直接使用SDK是否有意义,或者我可以利用Java中提供的开源包装器api。