
将一个大文件拆分为每个文件10000行的命令是什么?

我有一个名为MovieID_NameID_Roles.txt的文件,容量为1,767,605 KB。
我需要遍历它来解析,然后填充数据库表。
我想处理几个小文件,而不是一个大文件,我找到了如何分割大文本文件的答案。
基于接受的答案,其中指出:
分成每行10000行的文件:拆分myLargeFile.txt-l 10000
...但是在第二个屏幕截图的底部,给出了这个命令的一个在我看来更“花哨”的版本,加入了一些细节:
拆分MovieID_NameID_Roles.txtMySlice-1 10000-a 5-d
所以,我下载并安装了Git / Bash,并在其中运行了这个:
split MovieID_NameID_Roles.txt MySlice -1 10000 -a 5 -d
但是,它没有像我预期(或至少希望)那样将我的非常大的文件拆分为每个10,000行的文件,而是通过1000099999生成名为1000000000的文件,每个文件的大小只有1KB;然后拆分停止工作,并显示错误消息“输出文件后缀已用尽”:
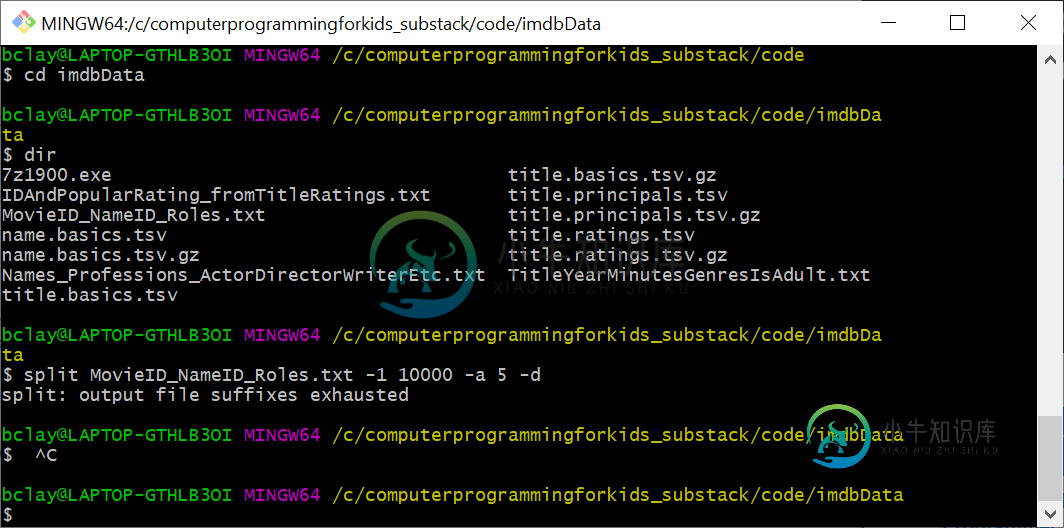
那么,我应该使用什么命令将我的文件拆分为每个10,000行的较小文件?
共有1个答案

看起来您使用的是“-1”而不是“-l”。这导致生成多个单行文件。
命令应该是:
$ split MovieID_NameID_Roles.txt MySlice -l 10000 -a 5 -d
-
问题内容: 我已经开发了一个大型点击应用程序,但是浏览不同的命令/子命令变得很困难。如何将命令组织到单独的文件中?是否可以将命令及其子命令组织到单独的类中? 这是一个我想如何分开的例子: 在里面 command_cloudflare.py command_uptimerobot.py 问题答案: 使用此功能的缺点是它会合并您的命令,并且仅适用于命令组。imho更好的替代方法是用于获得相同的结果。
-
问题内容: 我想将一个大小约为50GB的大型文本文件拆分为多个文件。文件中的数据就像这样-[x = 0-9之间的任何整数] 文件中可能只有几十亿行,我想为每个文件写例如30/40百万。我想这些步骤将是- 我要打开文件 然后使用readline()必须逐行读取文件并同时写入新文件 一旦达到最大行数,它将创建另一个文件并再次开始写入。 我想知道如何将所有这些步骤以一种高效且更快的内存方式组合在一起。我
-
问题内容: 我得到一个包含以下内容的文本文件(12 MB): 有什么办法来分流到12个* .txt文件让说,,(......)? 问题答案: 您可以使用linux bash核心实用程序 注意,或两者都OK,但大小不同。MB为1000 * 1000,M为1024 ^ 2 如果要按行分隔,可以使用参数。 更新 Kirill建议的另一种解决方案,您可以执行以下操作 请注意,是不是,有几个选项,比如,,,
-
问题内容: 有什么方法可以将.tfrecords文件直接拆分为多个.tfrecords文件,而无需回写每个Dataset示例? 问题答案: 您可以使用如下函数: 例如,要将文件分成100条记录,您可以执行以下操作: 这将创建多个较小的记录文件,等等。
-
问题内容: 我有从mongodb导出的json文件,如下所示: 大约有30000行,我想将每一行拆分成自己的文件。 (我正在尝试将我的数据转移到榻榻米群集上) 我尝试这样做: 但是我发现它似乎减少了行的负载,而当我期望30000个奇数时,运行此命令的输出仅给了我50个奇数文件! 有没有一种逻辑方法可以使此操作不使用任何适合的方法删除任何数据? 问题答案: 假设您不在乎确切的文件名,如果要将输入拆分
-
问题内容: 将Spring的配置拆分为多个xml文件的正确方法是什么? 此刻我有 /WEB-INF/foo-servlet.xml /WEB-INF/foo-service.xml /WEB-INF/foo-persistence.xml 我有以下内容: 实际问题: 这种方法正确/最佳吗? 我真的需要同时指定中的配置位置 和该板块? 我需要记住什么才能能够引用中定义的?这与 指定有关吗? 更新1: