
Spark:Executor丢失失败(添加groupBy作业后)

我得到了“ExecutorLostFailure(Executor1 lost)”。
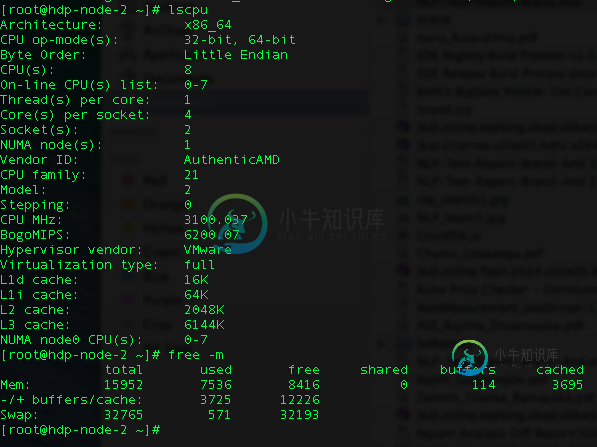
我已经尝试了大部分的Spark调优配置。我已经减少到一个执行人失去,因为最初我得到了像6个执行人失败。
以下是我的配置(我的spark-submit):
def process(in: RDD[(String, String, Int, String)]) = {
in.groupBy(_._4)
}
共有1个答案

出现了两个问题:
>
spark.shuffle.memoryfraction设置为1。为什么选择这个而不是保留默认的0.2?这可能会使其他非洗牌操作陷入困境
您只有11G可用于16个内核。只有11G的情况下,我会将工作中的工人数量设置为不超过3个--最初(为了解决执行者丢失的问题)只需尝试1个。对于16个执行器,每个执行器都有大约700MB的空间--这就不足为奇了,它们丢失了OOME/executor。
-
目前,我们试图将SonarQube分析添加到我们的jenkins工作管道中。但是每次构建作业失败时,都会出现以下消息:我们会重新安装所有插件和配置。无济于事。也许你们中有人能帮我们。 我们所做的: 从SonarQube执行本教程的所有步骤:用SonarQube扫描仪为Jenkins进行分析 > 安装SonarQube插件2.5 在管理詹金斯>配置系统下添加和配置SonarQube 在管理詹金斯>全
-
我想在阿兹卡班经营蜂巢工作
-
我目前正在尝试为一个项目设置Elasticsearch。我已经安装了,还安装了Java,即。 但是当我尝试使用以下命令启动Elasticsearch时 我得到以下错误 loaded:loaded(/usr/lib/systemd/system/elasticsearch.service;disabled;vend 活动:自世界协调时2019-11-01 06:09:54开始失败(结果:退出-代码)
-
我正在通过rest上传视频到我们的Azure媒体服务器,但编码工作失败,以下例外: 我可以看到它声明不支持文件类型,但是如果我手动上传它就没有问题了。 这就是我发布视频的方式 该文件存在于Azure服务器上,但无法播放。 谁能给我指个方向吗
-
我需要某人的帮助。 我遵循教程使用Kafka Connect和Debezium将数据从MySQL流式传输到Kafka,但是使用Debezium MySQL连接器将MySQL连接到Kafka服务器时遇到了麻烦。 这是我的设置和其他信息。 操作系统:视窗10。 Kafka连接:合流5.0。 MySQL连接器:0.8.1最终版本。 我保存文件 我添加插件路径 当我尝试连接Kafka Connect时,它
-
我正在写一个简单的流媒体地图减少工作使用Python在亚马逊电子病历上运行。它基本上是用户记录的聚合器,将每个用户标识的条目分组在一起。 制图器 减速机: 此作业应在包含五个文本文件的目录上运行。EMR作业的参数包括: 输入:[桶名]/[输入文件夹名] 输出:[存储桶名称]/Output 映射器:[Bucket name]/Mapper.py Reducer:[存储桶名称]/Reducer.py