
如何在MySQL Workbench上执行耗时更长的99,999秒的SQL查询?

更新:问题现已修复。
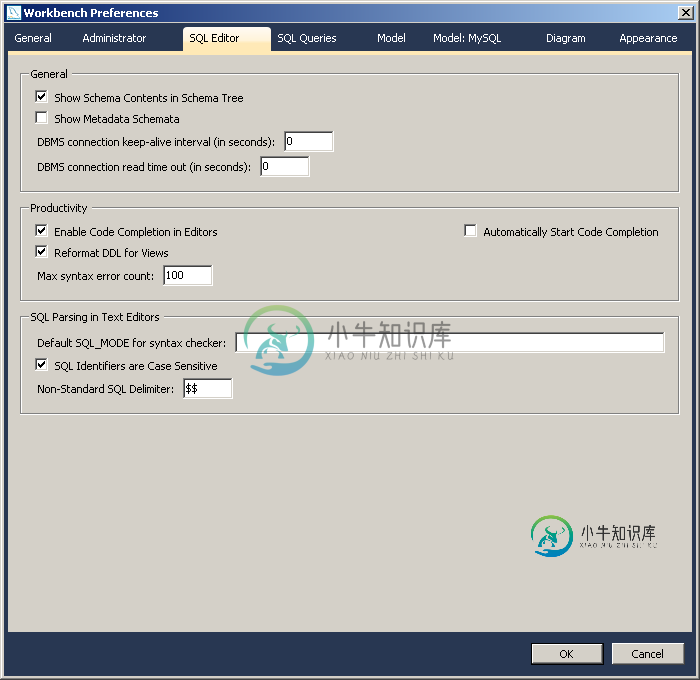
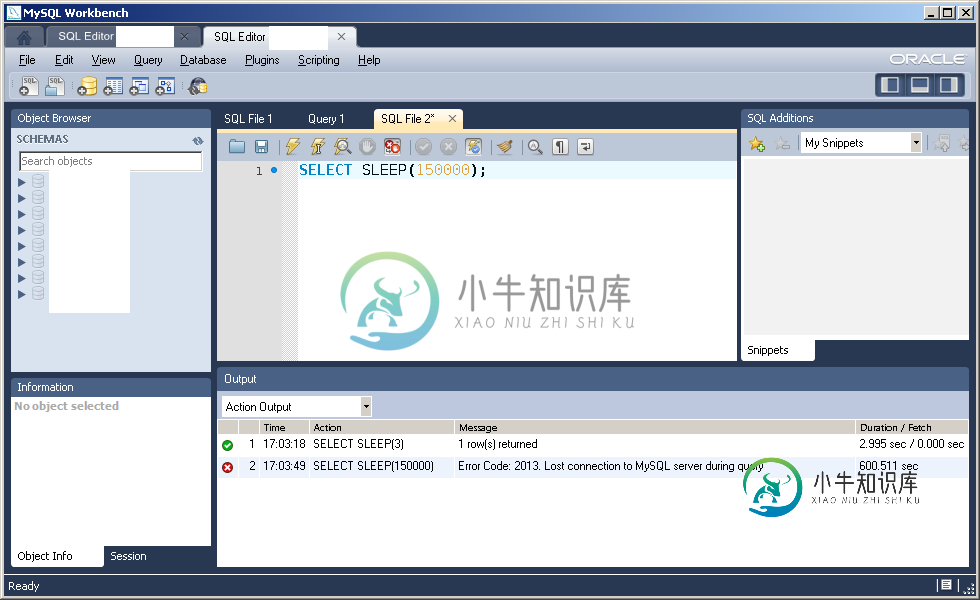
我想执行一个执行时间超过99,999秒的查询(例如SELECT SLEEP(150000);)。要更改MySQL Workbench中的超时,我们必须转到编辑→首选项→SQL编辑器→DBMS连接读取超时(以秒为单位)。但是,DBMS连接读取超时字段最多只接受5个数字,将该字段设置为0相当于默认参数(600秒)。如果查询花费的时间超过超时,我收到错误消息:错误代码:2013。在查询过程中与MySQL服务器失去连接
因此,我的问题是:有没有可能将这一限制增加到99,999秒以上?我用的是Windows 7 64位旗舰版和MySQL Workbench 5.2.47 CE。
共有3个答案

在欧洲,我们认为逗号是小数分隔符。你真的是指100k秒吗?我在你的评论中看到你正在处理50 GB。即便如此,如果你需要超过一个小时,你还是错过了Indeces。你必须知道它们不会在一个查询中得到正确的重建,所以如果你加入一个大规模的插入,你会得到扫描行的笛卡尔乘积——换句话说,你的查询可能会运行几周甚至几个月。
解决方案:
-
< li >填写基本数据,此处不使用连接。 < li >更改表以设置索引。 < li >运行<代码>分析
如果您觉得执行该过程有困难,请在Query之前添加EXPLAIN关键字,然后发布结果。
(我有一个cronjob,每30分钟导入大约80GB-MySQL肯定可以处理这个。)

此问题现已在 MySQL 工作台 6.0.3 (2013-07-09) 中得到解决:请参阅错误报告和更改日志。

可能没人想过你会需要这么长的超时时间,所以你被限制在当前可设置的范围内。但在上打开功能请求http://bugs.mysql.com建议使用0完全禁用超时或允许更大的值。
-
问题内容: 这不是连接超时,因为与数据库的连接正常。问题是我正在调用的存储过程花费的时间超过30秒,并且会导致超时。 该函数的代码如下所示: ExecuteScalar调用正在超时。如何延长此功能的超时时间? 对于快速存储过程,它可以正常工作。但是,其中一个功能需要一段时间,并且调用失败。当以这种方式调用ExecuteScalar函数时,我似乎找不到任何延长超时时间的方法。 问题答案: 如果您正在
-
我目前使用的是mysql 我有两个名为person和zim_list_id的表,这两个表都有超过200万行
-
问题内容: 该应用程序具有占用大量CPU资源的长进程,当前该进程在客户端请求时在一台服务器(EJB方法)上串行运行。 从理论上讲,理论上可以将流程分为N个块并并行执行,只要可以收集所有并行作业的输出并将其合并在一起,然后再将其发送回启动该流程的客户端即可。我想使用这种并行化来优化性能。 如何使用EJB实现这种并行化?我知道我们不应该在EJB方法中创建线程。相反,我们应该发布消息(每个作业一个),以
-
问题内容: 说我长时间运行更新查询 some_table中的modification_time的值是什么?它们是相同还是不同(例如,执行查询花了2天的时间)。 如果它们不同,如何编写此查询以使它们都相同? 问题答案: 它们都是一样的,因为NOW()在查询开始时被锁定了。 答案太短了吗? 好的,更多信息有关NOW()的MySQL参考 NOW()返回一个 恒定时间 ,该时间指示该语句 开始执行的时
-
下面是目前为止我所想到的伪代码。任何帮助都将不胜感激!谢谢! 我检查了Table API,但对于流,似乎不支持很多操作,例如OrderBy。
-
问题内容: 我有一个.sql文件,其中包含一堆要在heroku上的postgres数据库上执行的插入命令。但我不知道该怎么做: 如果我有权访问postgres控制台,请输入以下内容: 但似乎heroku不支持此命令。我尝试过 但这不能让我输入文件。 还有其他选择吗? 问题答案: 对于种子数据库之类的事情,我推荐理查德·布朗(Richard Brown)的答案:可以说,最好使用Rails种子机制之类