
即使未达到Pod限制,Pod内的进程也会被OOMKill杀死

我们对整个 Kubernetes 世界有点陌生,但现在已经有许多服务在 GKE 中运行。今天,我们看到了一些奇怪的行为,其中一个 Pod 内部运行的进程被杀死了,即使 Pod 本身有足够的可用资源,并且远未达到其极限。
限制定义如下:
resources:
requests:
cpu: 100m
memory: 500Mi
limits:
cpu: 1000m
memory: 1500Mi
在豆荚内部,一个芹菜(Python)正在运行,这个特定的正在消耗一些相当长的运行任务。
在其中一个任务的操作过程中,芹菜进程突然被杀死,似乎是由OOM引起的。GKE集群操作日志显示以下内容:
Memory cgroup out of memory: Kill process 613560 (celery) score 1959 or sacrifice child
Killed process 613560 (celery) total-vm:1764532kB, anon-rss:1481176kB, file-rss:13436kB, shmem-rss:0kB
时间段的资源图如下所示:
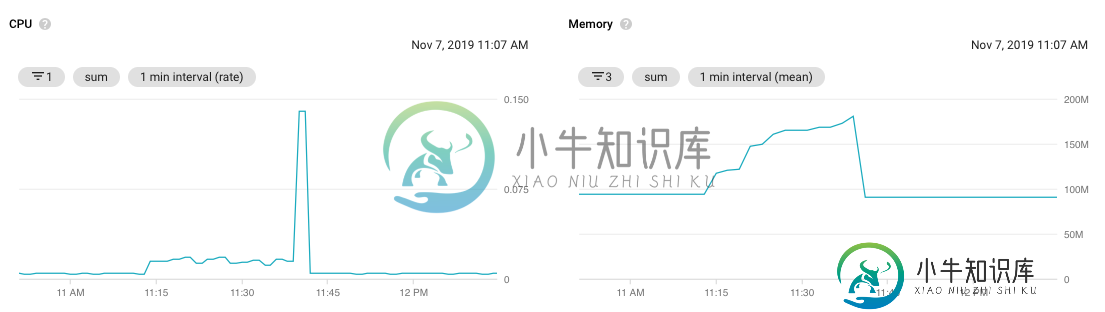
可以清楚地看到,CPU和内存使用量都没有接近Pod定义的限制,所以我们对为什么会发生OOMKilling感到困惑?也对进程本身被杀死而不是实际的Pod感到困惑?
这种特殊的OOM是否真的发生在操作系统内部,而不是库伯内特斯?如果是这样——有没有解决这个特殊问题的办法?
共有2个答案

我们有同样的问题。OOM杀死了芹菜加工过程,所以我们认为芹菜荚死了。然而,没有一个芹菜荚超过了它们的记忆极限。
起初我以为是因为https://github.com/kubernetes/kubernetes/issues/50632-可以通过OOM杀死子进程,而不杀死pod。
然而,实际的答案要简单得多。我们使用花来监测芹菜,花运行芹菜过程。经过检查,我们发现Flower的记忆限制太低了,并且由于OOM,花荚已经重新启动。

关于你的陈述:
对于进程本身被终止,而不是实际的Pod,也有点困惑?
计算资源(CPU/内存)是为容器而不是为pod配置的。
如果Pod容器被OOM杀死,则不会逐出Pod。底层容器将由kubelet根据其RestartPolicy重新启动。Pod仍将存在于同一节点上,并且Restart Count将递增(除非您使用的是RestartPolicy:从不,这不是您的情况)。
如果在pod上执行kubectl描述,新生成的容器将处于运行状态,但您可以在最后一个状态中找到上次重新启动的原因。此外,您还可以检查它重新启动了多少次:
State: Running
Started: Wed, 27 Feb 2019 10:29:09 +0000
Last State: Terminated
Reason: OOMKilled
Exit Code: 137
Started: Wed, 27 Feb 2019 06:27:39 +0000
Finished: Wed, 27 Feb 2019 10:29:08 +0000
Restart Count: 5
资源图可视化可能会偏离内存的实际使用。由于它使用1分钟间隔(平均值)采样,如果内存突然超过上限,则可以在平均内存使用量在图形上绘制为峰值之前重新启动容器。如果您的Python容器使用了短时间/间歇性的高内存,那么即使图中没有这些值,它也很容易重新启动。
使用< code>kubectl top,您可以查看为Pod注册的最后一次内存使用情况。尽管可以更精确地查看特定时间点的内存使用情况,但请记住,它从< code>metrics-server中获取值,该值具有< code> - metric-resolution:
从Kubelets抓取指标的间隔(默认为60)。
如果您的容器对内存的使用达到“峰值”,您可能仍然会看到它正在重新启动,甚至看不到< code>kubectl top上的内存使用情况。
-
我为kubernetes api服务器上的POD创建了如下限制 如果我理解正确,如果pod在创建pod时超出了用户定义的资源限制,kubernetes会拒绝pod。所以,我尝试创建一个新的pod,它通过了资源限制,然后我尝试消耗资源达到最大限制资源,但它对pod没有任何影响。LimitsRange和ResourceQuota插件是否包含在本案例中?如果没有,我如何在创建资源吊舱后限制资源吊舱?
-
我有一个配置了优雅关机的SpringBoot项目。部署在k8s这是日志, 应用程序已从库伯内特斯收到处的。根据Pods表示终止Pod已从服务的endpoint列表中删除,但它与发送信号后转发请求17秒(直到)相矛盾。是否缺少任何配置? 优雅关机 部署文件 更新时间: 添加了自定义健康检查endpoint 更改了livenessProbe, 这是更改后的日志, 使用3次故障的livenessProb
-
2.)我已经通过在kubernetes中创建LoadBalancer类型的服务向外部世界公开了我的REACT应用程序,并且我能够从浏览器访问REACT应用程序endpoint。现在,是否可以从节点内部的REACT应用程序访问EXPRESS应用程序而不向外部世界公开我的EXPRESS应用程序?如何实现这一点? 提前谢了。
-
我使用1Gi内存设置将filebeat作为守护程序集运行。我的播客崩溃,状态为“OOMKilled”。 这是我的限制设置 运行filebeat的推荐内存设置是什么? 谢谢
-
我在一个吊舱内运行一个Spring靴,配置如下。 吊舱限制: 命令参数: 如果java进程达到其最大堆限制(即1600m(Xmx1600m))会发生什么 如果Xmx对pod内的java进程没有影响,它可以上升到pod限制右(即内存:限制部分的2500Mi) 如果上面的配置是正确的,那么我们就是在浪费900Mi的内存权(2500-1600=900)
-
问题内容: 我已经为kubernetes中的front(REACT)和backend(EXPRESS NODE JS)项目泊坞窗并创建了部署和服务。我已经在Google Cloud Platform中的两个 Pod (即 一个 Pod- > REACT APP和SECOND POD-> EXPRESS NODE JS )的同一节点的Kubernetes(单节点集群)中成功部署了。 题: 1.)如何