
在Zeppelin中添加spark-csv依赖项会产生网络错误

在Zeppelin中添加spark-csv依赖项会产生网络错误。我转到Zeppelin中的Spark解释器,添加了Spark-csv依赖项。com.databricks:spark-csv_2.10:1.2.0。我还在参数选项中添加了它。
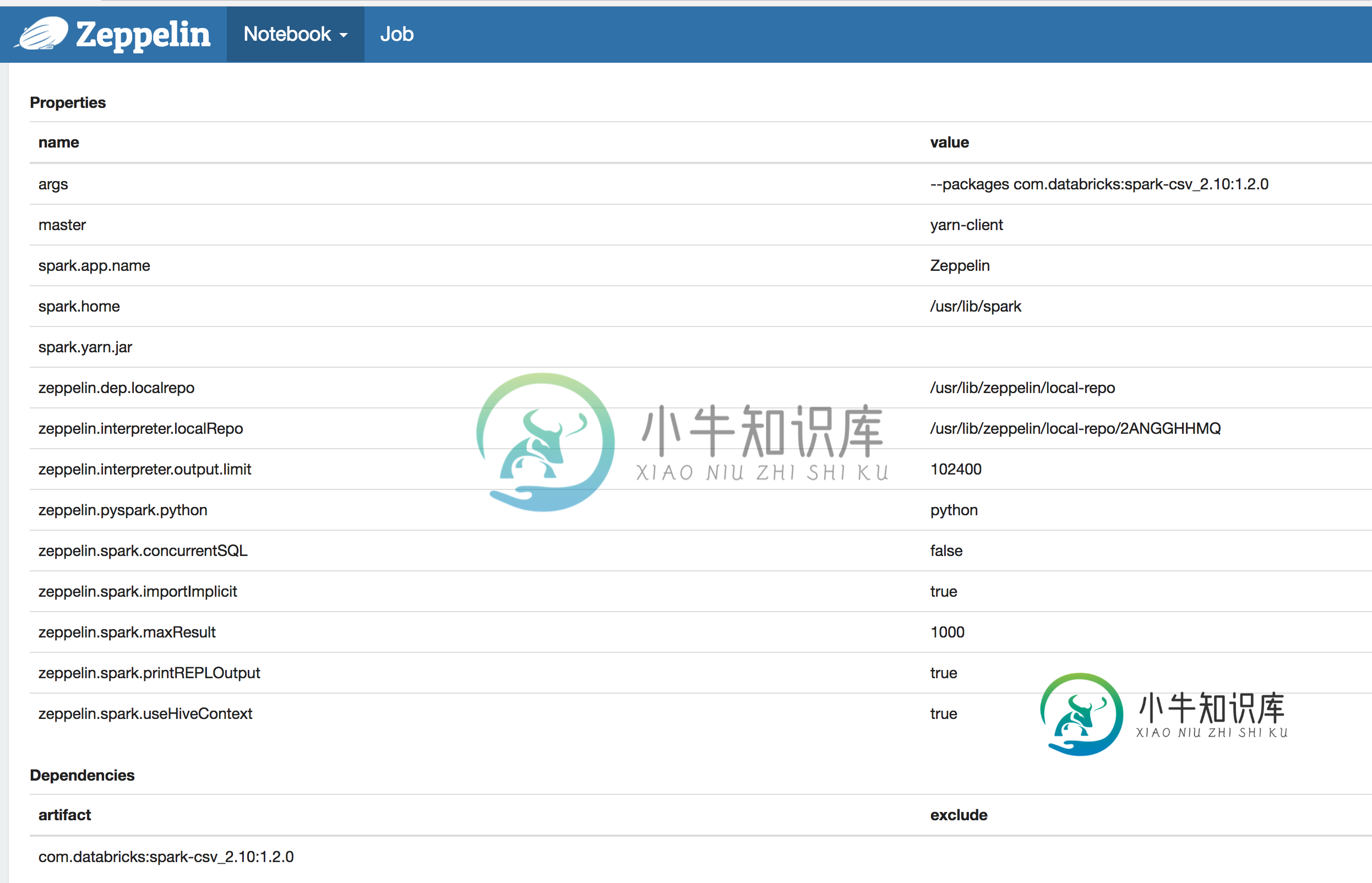
我重新启动Zeppelin并运行以下命令:
import org.apache.spark.sql.SQLContext
val sqlContext = new SQLContext(sc)
val df = sqlContext.read
.format("com.databricks.spark.csv")
.option("header", "true") // Use first line of all files as header
.option("inferSchema", "true") // Automatically infer data types
.load("https://github.com/databricks/spark-csv/raw/master/src/test/resources/cars.csv")
df.printSchema()
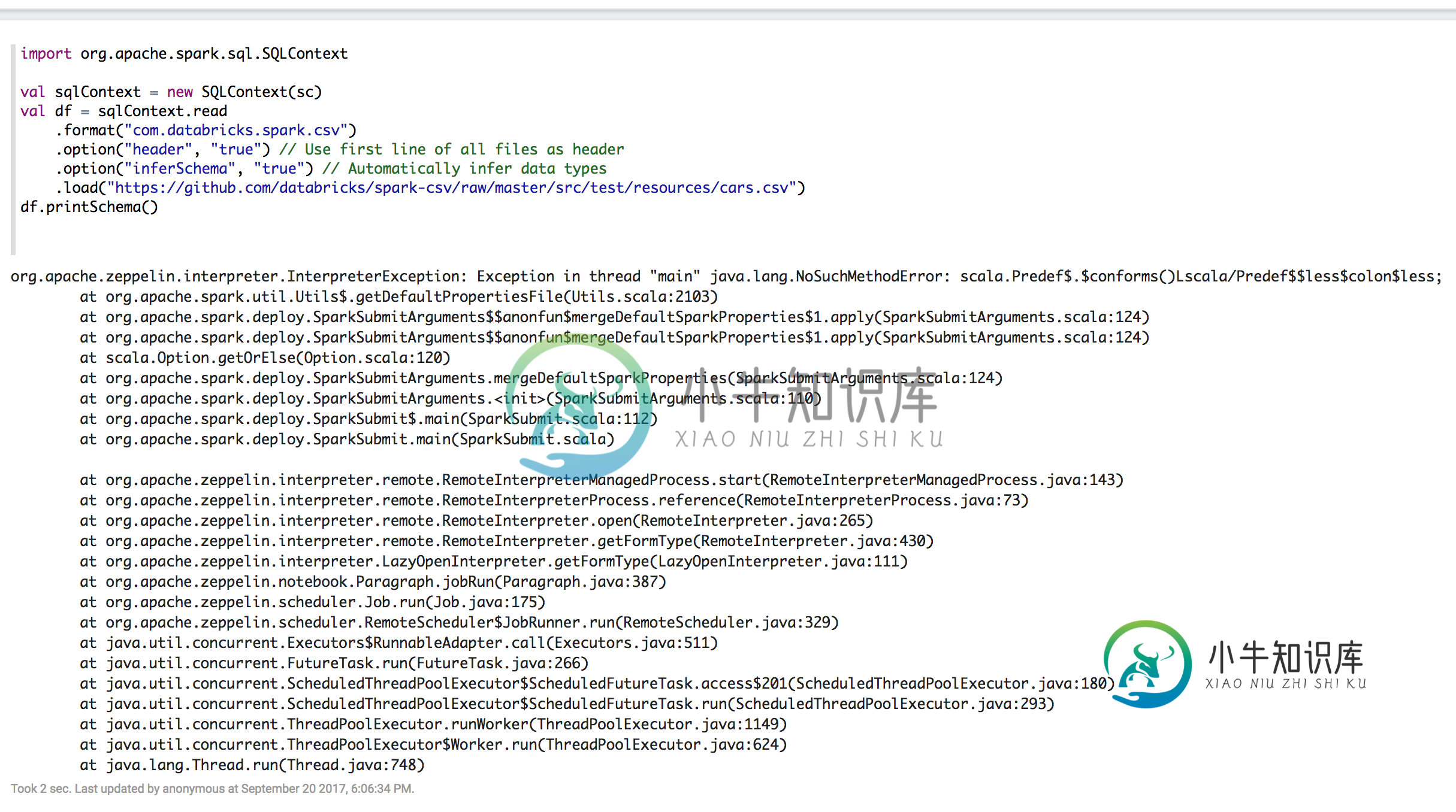
是否正确添加了依赖项?
更新
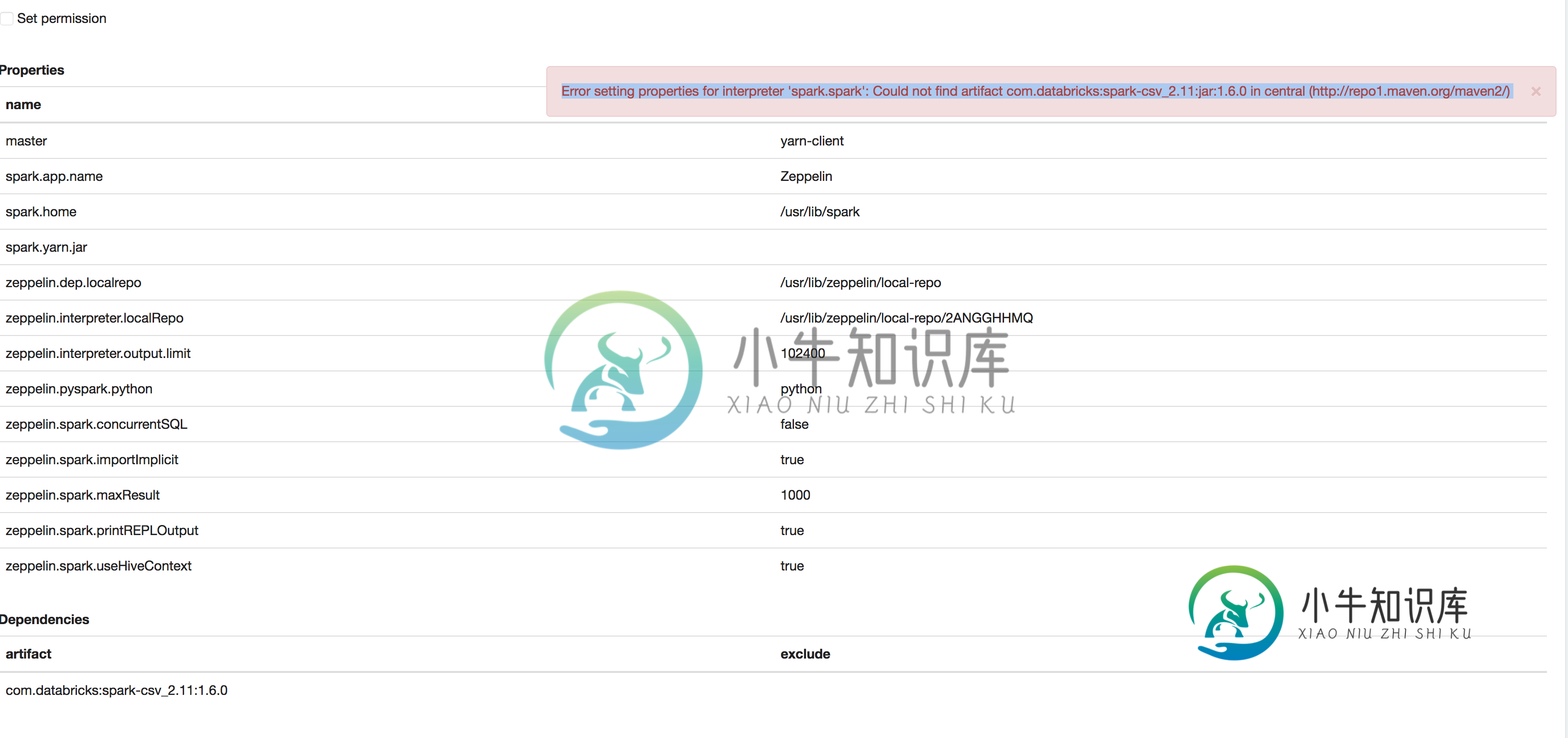
尝试将库更改为com.databricks:spark-csv_2.11:jar:1.6.0,结果如下:
设置解释器“spark.spark”的属性时出错:在central(http://repo1.maven.org/maven2/)中找不到项目com.databricks:spark-csv2.11:jar:1.6.0
共有1个答案

看起来您使用的是相当老的库版本,此外还为Scala2.10构建(您的spark似乎是2.11)。
将包更改为com.databricks:spark-csv_2.11:1.5.0,它应该可以工作。
-
我正在处理一批,我面临一个问题。我已经确定了我的问题的原因,但我无法解决它。 在pom中添加依赖项后,就会出现错误 maven依赖项是 我的pom如下所示 我得到的错误是 2017-08-14 16:18:43.676信息11676----[主]S.C.A.AnnotationConfigApplicationContext:关闭org.springFramework.Context.Annota
-
问题内容: 如何获取我拥有的jar文件并将其添加到Maven 2的依赖系统中?我将成为此依赖项的维护者,并且我的代码需要在类路径中使用此jar,以便对其进行编译。 问题答案: 您必须分两步执行此操作: 1.给您的JAR一个groupId,artifactId和版本,然后将其添加到您的存储库中。 如果您没有内部存储库,而只是试图将JAR添加到本地存储库,则可以使用任意groupId / artifa
-
我在试着设置QAF。早些时候,当我设置框架时,我可以在控制台和输出日志文件中看到驱动程序日志。但现在我看不到他们了。我没有在日志文件配置或它的目录中做任何更改。有人能给我一些建议吗?
-
从我读到的内容来看,我似乎需要一个pom.xml文件。也许我应该先以某种方式将maven添加到项目中?
-
我正在尝试使用此分步指南将OpenCV包含在我的Android Studio项目中。但是,在将OpenCV添加为模块依赖项(指南中的第4步)后,Gradle项目同步失败并出现以下错误: 我发现了这个相关的问题,并尝试在openCV构建中调整构建类型。gradle添加了一个调试字段,但它没有改变任何东西。我还试着调整应用程序的构建。渐变如下 (还有几个稍有不同的版本,因为我不完全确定我在那里做了什么
-
null 0.0.1-快照 _remote.repositories Maven-metadata-local org-utility-0.0.1-snapshot.jar org-utility-0.0.1-snapshot.pom org-utility-0.0.1-snapshot-jar-with-dependencies.jar 因此,我能够将jar“retrieve org-utili