
无功Flux编程中的并行执行

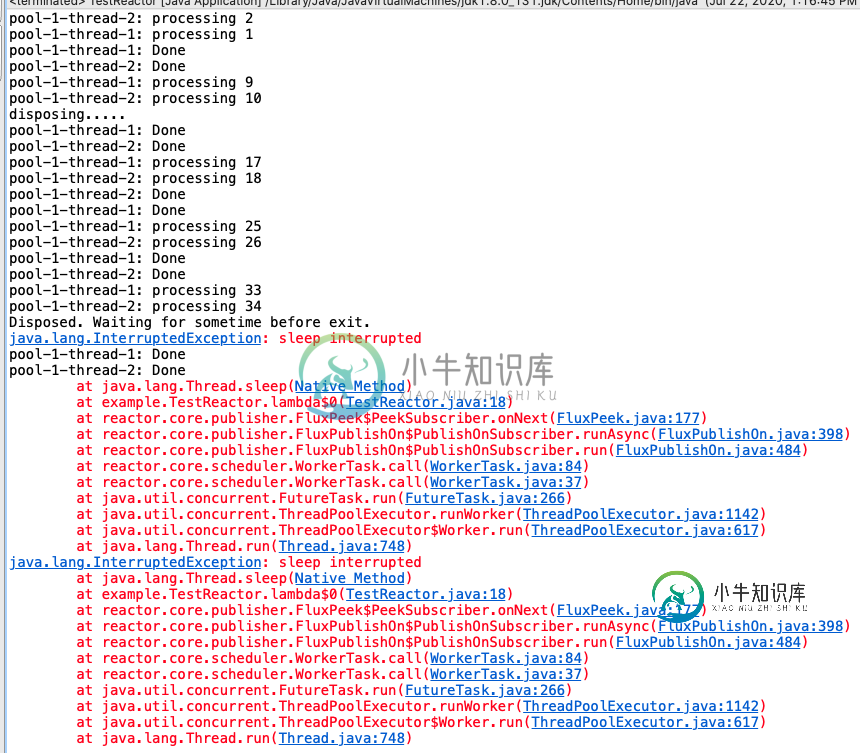
我试图避免使用阻塞线程模型,而使用反应式模型来实现高吞吐量。我的用例是这样的:有大量的传入消息。对于每条消息,我需要在不阻塞该线程的情况下执行一些I/O操作。在这里,我在一个单独的线程中处理每条消息。如果应用程序被终止,我需要完成正在进行的任务并优雅地关闭。我用的是线。在下面睡眠以模拟密集的I/O操作。代码示例如下:
public class TestReactor {
public static void main(String[] args) throws InterruptedException {
ExecutorService executor = Executors.newFixedThreadPool(2);
Disposable task = Flux.range(1, 100).parallel().runOn(Schedulers.fromExecutor(executor)).doOnNext(message -> {
System.out.println(Thread.currentThread().getName()+": processing " + message);
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+": Done");
})
.sequential()
.doOnError(e->e.printStackTrace())
.doOnCancel(()->{
System.out.println("disposing.....");
executor.shutdown();
try {
executor.awaitTermination(5, TimeUnit.SECONDS);
} catch (InterruptedException e1) {
e1.printStackTrace();
}
})
.subscribe();
Thread.sleep(4000);
task.dispose();
System.out.println("Disposed. Waiting for sometime before exit.");
Thread.sleep(20000);
}
}
当我运行这个时,通量似乎忽略了执行者。shutdown()和错误以及中断的异常。是否可以使用flux实现我的用例?
共有1个答案

您犯了一个很大的错误:在使用反应式编程时,永远不要使用任何线程操作。这是一个肮脏的黑客。当您尝试在FRP上编码时,最明显的不良设计和代码气味标记是:
- 调用操作符和副作用函数(doOn)内的
try catch块。如果你有一个例外情况-好的,没关系。调用onError操作符并在其中处理管道的行为
所以,关于这个问题及其解决方案:你做了糟糕的设计:)你不需要处理任何一次性的或线程中断。您只需删除它并添加killswitch。
那么,工作代码,这就是您想要的:
public class TestReactor {
public static void main(String[] args) throws InterruptedException {
ExecutorService executor = Executors.newFixedThreadPool(2);
Flux.generate(() -> 0,
(state, sink) -> {
sink.next("current state = " + state);
if (state == 100) sink.complete();
return state + 1;
}
)
.parallel()
.runOn(Schedulers.fromExecutor(executor))
.doOnNext(message -> {
System.out.println(Thread.currentThread().getName() + ": processing " + message);
System.out.println(Thread.currentThread().getName() + ": Done");
})
.sequential()
.doOnError(e -> e.printStackTrace())
.doOnCancel(() -> {
System.out.println("disposing.....");
})
.subscribe();
}
}
-
我已经定义了partitioner类,它返回与网格大小相同的executionContext。执行上下文={part3=start=0,part1=start=0,part2=start=0} 日志:-
-
我正在寻找一种使用Flux实现以下目标的方法: 处理1,000,000(或更多)请求流。 请求被编号(从1到1,000,000)。 请求应该使用10个线程并行启动。 请求的启动顺序由其序列号决定。 结果通量应该以与请求相同的顺序返回响应。 结果通量应该尽快发出每个响应,因为它的所有前身都是可用的。 我知道#4的答案是为计划程序使用一个执行器。然而,我不确定如何实现#6。 下面是一个示例场景: >
-
我在src/test/resources/feature/中有以下功能文件(单独的功能文件),我想并行运行它们。比如:一个功能文件必须在chrome中执行,另一个必须在另一个chrome实例中执行,如@Tags name所述。 我正在使用Java1.2。5版本,AbstractTestNGCucumberTests作为runner。我可以运行一个功能文件,但当我尝试使用cucumber jvm并行
-
并行 理论上并行和语言并没有什么关系,所以在理论上的并行方式,都可以尝试用Rust来实现。本小节不会详细全面地介绍具体的并行理论知识,只介绍用Rust如何来实现相关的并行模式。 Rust的一大特点是,可以保证“线程安全”。而且,没有性能损失。更有意思的是,Rust编译器实际上只有Send Sync等基本抽象,而对“线程” “锁” “同步” 等基本的并行相关的概念一无所知,这些概念都是由库实现的。这
-
我试图使用Selenium和TestNG进行测试设计,我将每个@test放在一个单独的类中,并对所有类使用once@beforeSuite&@afterSuite,原因是: 代码易于维护 数据驱动,以便能够选择通过文件运行的类。 案例1类: 注意:如果上面的代码在套件中使用单个运行,它就可以正常工作。 问题是它是否像下面的配置那样并行运行。
-
问题内容: 我们如何用Java进行并行编程?有什么特殊的框架吗?我们如何使这些东西起作用? 我会告诉大家我需要什么,以为我开发了一个Web搜寻器,它可以从互联网上搜寻很多数据。一个爬网系统将无法正常工作,因此我需要更多的并行系统。如果是这种情况,我可以应用并行计算吗?你们能给我一个例子吗? 问题答案: 如果您询问纯 并行编程( 即 非并发 编程),那么绝对应该尝试MPJExpress http:/