
KafkaMirrorMaker2自动消费偏移同步

我正在使用镜像制作器 2 进行灾难恢复。
Kafka 2.7 应支持自动消费者偏移同步
下面是我正在使用的yaml文件(我使用strimzi来创建它)
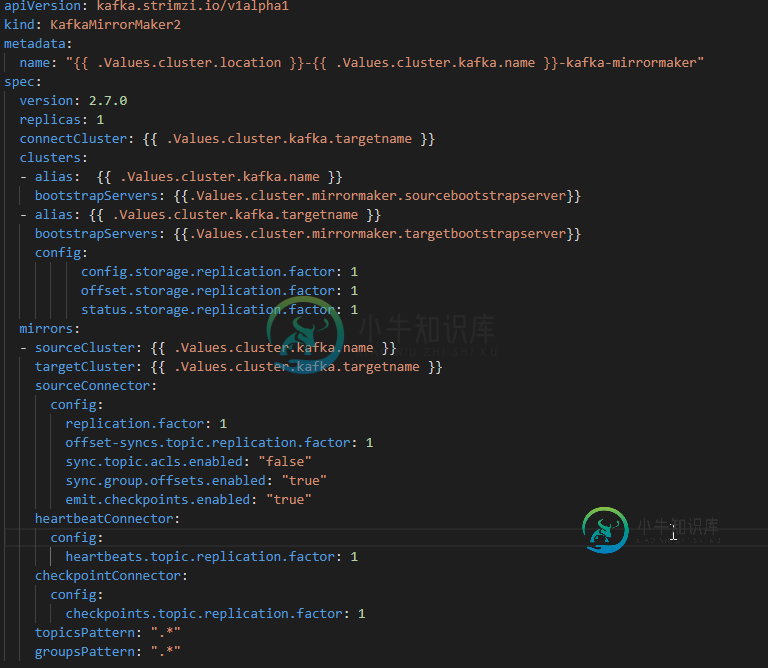
所有源群集主题都在目标群集中复制。还有…检查点。内部主题是在包含所有同步的源集群偏移量的目标集群中创建的,但我没有看到这些偏移量被转换为目标集群_consumer_offsets主题,这意味着当我在目标集群中启动消费者(同一消费者组)时,它将从一开始读取消息。
我的期望是,在允许自动消费者偏移后,同步来自源集群的所有消费者偏移,并将其翻译并存储在目标集群中_consumer_offsets主题中。
有人能澄清一下我的期望是否正确,如果不是,它应该如何工作。
共有1个答案

sync.group.offsets。已启用的设置适用于MirrorCheckpointConnector。
我不完全确定Strimzi如何运行MirrorMaker 2,但我认为您需要将其设置为:
checkpointConnector:
config:
checkpoints.topic.replication.factor: 1
sync.group.offsets.enabled: "true"
-
谢了。
-
为什么实际主题中的偏移值与同一主题中的偏移值不同?PFB偏移位置以及使用的命令。 我错过了什么?
-
试图理解消费者补偿和消费者群体补偿之间的关系。 下面的堆栈溢出链接提供了对消费群体补偿管理的极好理解<什么决定Kafka消费补偿?现在问题来了, 情节: 我们在一个消费者组组1中有消费者(c1)。 偏移值是否将存储在消费者(c1)和组(group1)两个级别?或者如果消费者属于任何消费者组,偏移量将存储在仅消费者组级别? 如果偏移值将存储在两个级别中,它是否是消费者级别偏移值将覆盖消费者组级别偏移
-
我已经将enable.auto.commit设置为true,并将auto.commit.interval.ms设置为10,000(即10秒)。现在我的问题是--消费者是每个记录的提交偏移量,还是根据10秒内消耗的记录数提交并提前偏移量?
-
我正在使用Kafka2.0版和java消费者API来消费来自一个主题的消息。我们使用的是一个单节点Kafka服务器,每个分区有一个使用者。我注意到消费者正在丢失一些消息。场景是:消费者投票主题。我为每个线程创建了一个消费者。获取消息并将其交给处理程序来处理消息。然后使用“至少一次”的Kafka消费者语义来提交Kafka偏移量来提交偏移量。同时,我有另一个消费者使用不同的group-id运行。在这个
-
我有以下代码 消费者订阅的主题会不断收到记录。有时,消费者会因处理步骤而崩溃。然后,当使用者重新启动时,我希望它从主题的最新偏移量开始使用(即,忽略在使用者关闭时发布到主题的记录)。我认为方法可以确保这一点。然而,这种方法似乎毫无效果。消费者从其崩溃的偏移量开始消费。 什么是正确的方式使用? 编辑:使用以下配置创建消费者