
可扩展的节点.js应用程序体系结构

过去,我在玩Node。js只在我的本地机器上,所以我只有使用单进程Node的经验。js应用程序。现在,我想创建一个可以在web上发布的web应用程序。
这个web应用程序有点像多人游戏——使用Socket。IO用于客户端-服务器通信,Express用于处理HTTP请求,grunt用于任务管理,等等——我希望使用其他NPM包来处理各种任务。
我想将此应用程序的架构设计为
-
< li >实现水平可伸缩性(以后,当我有很多访问者时,我不必重写整个应用) < li >最小化对不同执行环境的依赖性(以最大化可移植性)
我如何使用Node实现这一点?
我想高级架构将包括:
- 不同的服务器进程(每个进程将运行一个Express实例并处理传入的HTTP请求)。
- 某处应该有负载均衡器。
- 可选:可以定期运行并处理“共享数据”的后台进程
由于我的应用程序是一个多人应用程序,每个用户都可以在其中与其他在线用户交互,所以我应该将一些公共状态(“共享数据”)存储在那些进程之间可以共享的地方。
为了简单起见,起初我不必持久化这些共享数据,所以我认为我应该使用像Redis这样的内存数据存储。
大局大概是这样的:
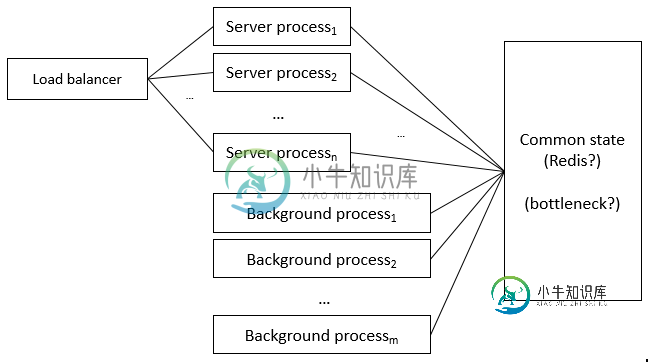
这种设计引发了一些问题:
我应该使用节点的child_process或集群模块并手动启动工作进程吗?顺便说一句,是否可以手动启动这些,例如,如果我将我的应用程序部署到Heroku或Nodejitsu?
OR:有没有更好的方法将这些信息存储在配置文件中?
我的意思是,如果我可以配置我想要多少服务器实例,而不是编辑代码,而是配置条目,那就更好了。
如果我手动生成进程,那么(我猜)所有进程都将在同一(虚拟)服务器上运行。
如果这个服务器有4个CPU核心,那么您最多可以生成4个节点实例,因为如果您生成更多,您的CPU将进行上下文切换,这会破坏整体性能。
如果需要更多流程实例,我必须做什么?假设我需要100个服务器实例。我必须将我的应用程序部署到25台服务器上,并在每台服务器上生成4个进程吗?
在我看来,像Nodejitsu这样的托管服务以某种方式向您隐藏了这个系统边界层,但我不知道它在实践中是如何工作的。
特别是有这个“共享数据”提供程序组件。我猜这个提供程序(像Redis服务器)必须在不同的服务器上运行,这样所有进程都可以使用它。但在这种情况下,它很容易成为瓶颈,不是吗?
如果我使用一些托管服务,我必须自己设置负载均衡器层吗?
编辑:
回答一些实际问题:在第一步,我想无缝处理4-500个并发用户(Socket.IO 连接)。这是我可以实际实现的访客数量。
但我只是好奇这是否可能(如果可能,怎么办?)设计一个易于扩展的应用程序架构。比方说,我的网站将从早到晚流行起来,而不是处理几百个并发用户,第二天我必须服务几千个。
< sub >据我所知,像Heroku和Nodejitsu这样的云托管服务可以很容易地适应这些场景——你只需要增加工作人员/dyno/任何东西的数量——但只有在你有正确的应用程序架构的情况下,它才能工作。
关于共享数据:我不想持久化它。我只想把它保存在内存中。一方面,由于Socket.IO,需要一些共享数据提供者——一个用户将能够向另一个“节点”中的用户发送消息。为此,我将使用Redis作为共享数据提供者。Redis需要处理的事务数等于发送/接收消息的数量,Socket.IO,约1000-1500条消息/秒。
另一方面,需要一些共享数据提供程序,因为我想根据几个标准连接用户。稍后,后台进程将定期重新计算/优化这些连接的概率(“权重”)。我已经知道如何实现高效的数据结构来处理这个内存表中的快速插入/删除。因此,“共享数据提供程序”组件将由一些服务器端代码(可能是Node.js)组成,这些代码可以存储这些连接
我知道是TL;但我希望它能回答你关于这个问题的所有技术问题。:)
共有1个答案

好吧,这很难接受。首先,您的关注点分离是适当的,您需要一种流程通信的方式,这可以通过redis实例,或其他发布/订阅或请求/请求系统(无论是Redis、kue、zmq等)。注意:如果您的数据/消息使用量显著增长,您可能仍然需要共享数据/消息使用量,至少是尽可能地共享。如果使用更复杂的消息队列系统(Rabbit或其他AMQP ),可以缓解这种情况。
看来您主要关心的是流程管理。通常,如果您使用的是 Heroku,您应该能够扩展每个节点的单个进程,但随后您仍然需要外部的协调器节点。如果您是自我托管(不是通过heroku或类似方式),那么您应该查看pm2或永远...然后,您可以调出多个实例...
在很大程度上,您的物流/基础设施问题会因您的需求而异。更不用说涉及CI/CD、docker等新策略了。或者您数据库使用。
-
这是一个有点开放性的问题,但是,制作一个好的可扩展电子应用程序的好方法是什么?VSCode、Atom和许多其他软件都支持扩展,但它们的代码库太大,我无法理解到底发生了什么。我对Jupyterlab感到非常惊讶,据他们说,它包含一个小小的核心,而其他一切都只是它上面的扩展。所以我想知道如何构建这些应用程序。 我的具体问题是: 是否有创建可扩展架构的最佳实践 电子部分是如何“识别”延伸的?怎么装的?什
-
通常在我的代码中,我会使用一些不同的字体,比如: Arial,字体权重:400,字体样式:正常 Arial,字体权重:400,字体样式:斜体字 Arial,字体权重:700,字体样式:正常 Helvetica,字体重量:400,字体样式:正常 Helvetica,字体重量:400,字体样式:斜体字 为此我使用了CSS-IN-JS库< code>styled-components,所以没有使用一些<
-
说明 本部分说明如何在现有的机器中添加一个新的计算节点。添加节点之前,OpenShift 共有四个节点,1 个 master,1 个 infra,2 个 nodes,如下命令所示: # oc get nodes NAME STATUS ROLES AGE VERSION infra.example.com Ready infr
-
我正在做一个项目,该项目将有许多JavaFX应用程序,这些应用程序具有相似但又足够不同的功能,因此我创建了一个抽象基类来扩展Application以处理常见的功能并指示它们需要做什么,还创建了一系列具体的类来扩展这些功能。然而,当我试图跑的时候,我得到 应用程序构造函数java.lang.Reflect.InvocationTargetException位于java.base/jdk.intern
-
Node.js以单线程模式运行,但它使用事件驱动的范例来处理并发。 它还有助于创建子进程,以便在基于多核CPU的系统上利用并行处理。 子进程总是有三个流child.stdin , child.stdout和child.stderr ,它们可以与父进程的stdio流共享。 Node提供了child_process模块,该模块具有以下三种创建子进程的主要方法。 exec - child_process
-
Atom和VisualStudio代码可能是迄今为止最大的电子应用程序,它们都具有很强的可扩展性,还有其他一些较小的例子,如N1。我的意思是,它们支持插件。 问题是:我想我会在谷歌上找到一些关于如何让电子应用程序可扩展的东西,或者那些很酷的“棒极了”列表上的东西,但是我什么也没找到。此外,深入研究这些应用程序的源代码需要一段时间。 我在寻找什么(或): 我不知道的内置功能 类似于电子可扩展的库(假