
使用比堆大小(或大小正确Docker内存限制)更多内存的Java

对于我的应用程序来说,Java进程使用的内存要比堆大小多得多。
运行容器的系统开始出现内存问题,因为容器占用的内存比堆大小多得多。
堆大小设置为128 MB(-xmx128m-xms128m),而容器最多占用1GB内存。 正常情况下,需要500MB。 如果docker容器有一个以下的限制(例如mem_limit=mem_limit=400MB),则进程会被OS的out of memory killer杀死。
你能解释一下为什么Java进程比堆占用更多的内存吗? 如何正确调整Docker内存限制的大小? 有没有一种方法可以减少Java进程的堆外内存占用?
我使用JVM中的本机内存跟踪命令收集了一些关于该问题的细节。
从主机系统中,我得到容器使用的内存。
$ docker stats --no-stream 9afcb62a26c8
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
9afcb62a26c8 xx-xxxxxxxxxxxxx-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.0acbb46bb6fe3ae1b1c99aff3a6073bb7b7ecf85 0.93% 461MiB / 9.744GiB 4.62% 286MB / 7.92MB 157MB / 2.66GB 57
从容器内部,我获得进程使用的内存。
$ ps -p 71 -o pcpu,rss,size,vsize
%CPU RSS SIZE VSZ
11.2 486040 580860 3814600
$ jcmd 71 VM.native_memory
71:
Native Memory Tracking:
Total: reserved=1631932KB, committed=367400KB
- Java Heap (reserved=131072KB, committed=131072KB)
(mmap: reserved=131072KB, committed=131072KB)
- Class (reserved=1120142KB, committed=79830KB)
(classes #15267)
( instance classes #14230, array classes #1037)
(malloc=1934KB #32977)
(mmap: reserved=1118208KB, committed=77896KB)
( Metadata: )
( reserved=69632KB, committed=68272KB)
( used=66725KB)
( free=1547KB)
( waste=0KB =0.00%)
( Class space:)
( reserved=1048576KB, committed=9624KB)
( used=8939KB)
( free=685KB)
( waste=0KB =0.00%)
- Thread (reserved=24786KB, committed=5294KB)
(thread #56)
(stack: reserved=24500KB, committed=5008KB)
(malloc=198KB #293)
(arena=88KB #110)
- Code (reserved=250635KB, committed=45907KB)
(malloc=2947KB #13459)
(mmap: reserved=247688KB, committed=42960KB)
- GC (reserved=48091KB, committed=48091KB)
(malloc=10439KB #18634)
(mmap: reserved=37652KB, committed=37652KB)
- Compiler (reserved=358KB, committed=358KB)
(malloc=249KB #1450)
(arena=109KB #5)
- Internal (reserved=1165KB, committed=1165KB)
(malloc=1125KB #3363)
(mmap: reserved=40KB, committed=40KB)
- Other (reserved=16696KB, committed=16696KB)
(malloc=16696KB #35)
- Symbol (reserved=15277KB, committed=15277KB)
(malloc=13543KB #180850)
(arena=1734KB #1)
- Native Memory Tracking (reserved=4436KB, committed=4436KB)
(malloc=378KB #5359)
(tracking overhead=4058KB)
- Shared class space (reserved=17144KB, committed=17144KB)
(mmap: reserved=17144KB, committed=17144KB)
- Arena Chunk (reserved=1850KB, committed=1850KB)
(malloc=1850KB)
- Logging (reserved=4KB, committed=4KB)
(malloc=4KB #179)
- Arguments (reserved=19KB, committed=19KB)
(malloc=19KB #512)
- Module (reserved=258KB, committed=258KB)
(malloc=258KB #2356)
$ cat /proc/71/smaps | grep Rss | cut -d: -f2 | tr -d " " | cut -f1 -dk | sort -n | awk '{ sum += $1 } END { print sum }'
491080
该应用程序是一个web服务器,使用Jetty/Jersey/CDI捆绑在一个36 MB的fat far内。
使用以下版本的OS和Java(容器内)。 Docker映像基于openjdk:11-jre-slim。
$ java -version
openjdk version "11" 2018-09-25
OpenJDK Runtime Environment (build 11+28-Debian-1)
OpenJDK 64-Bit Server VM (build 11+28-Debian-1, mixed mode, sharing)
$ uname -a
Linux service1 4.9.125-linuxkit #1 SMP Fri Sep 7 08:20:28 UTC 2018 x86_64 GNU/Linux
https://gist.github.com/prasanthj/48E7063CAC88EB396BC9961FB3149B58
共有3个答案

内存的详细使用情况由本机内存跟踪(NMT)详细信息(主要是代码元数据和垃圾收集器)提供。 除此之外,Java编译器和优化器C1/C2消耗了总结中没有报告的内存。
使用JVM标志可以减少内存占用(但会有影响)。
Docker容器大小的确定必须通过测试应用程序的预期负载来完成。
共享类空间可以在容器内禁用,因为类不会被另一个JVM进程共享。 可以使用以下标志。 它将删除共享类空间(17MB)。
-Xshare:off
垃圾收集器序列具有最小的内存占用,但代价是垃圾收集处理期间的暂停时间更长(请参见一张图片中的Aleksey ShipilëV比较GC)。 可以使用以下标志使能它。 它最多可以节省使用的GC空间(48MB)。
-XX:+UseSerialGC
可以使用以下标志禁用C2编译器,以减少用于决定是否优化某个方法的分析数据。
-XX:+TieredCompilation -XX:TieredStopAtLevel=1
代码空间减少了20MB。 而且,JVM外部的内存减少了80MB(NMT空间和RSS空间之间的差异)。 优化编译器C2需要100MB。
可以使用以下标志禁用C1和C2编译器。
-Xint
JVM外部的内存现在低于提交的总空间。 代码空间减少43MB。 注意,这对应用程序的性能有很大影响。 禁用C1和C2编译器将减少使用170 MB的内存。
使用Graal VM编译器(替代C2)会导致更小的内存占用。 它增加了20MB的代码内存空间,减少了来自JVM外部内存的60MB。
文章Java内存管理为JVM提供了一些相关信息,不同的内存空间。 Oracle在本机内存跟踪文档中提供了一些详细信息。 更多关于编译级别的详细信息,请参见高级编译策略和禁用C2,将代码缓存大小减少了5倍。 关于为什么JVM报告的提交内存比Linux进程驻留集大小多的一些细节? 当两个编译器都禁用时。

https://developers.redhat.com/blog/2017/04/04/openjdk-and-containers/:
为什么当我指定-xmx=1g时,我的JVM会使用超过1GB的内存呢?
指定-xmx=1g就是告诉JVM分配一个1GB的堆。 它没有告诉JVM将其整个内存使用量限制在1GB以内。 有卡片表,代码缓存和其他各种离堆数据结构。 您用来指定总内存使用量的参数是-xx:maxram。 请注意,使用-xx:maxram=500M时,堆将大约为250MB。
Java只看到主机内存大小,它并不知道任何容器内存限制。 它不会产生内存压力,因此GC也不需要释放使用过的内存。 我希望xx:maxram将帮助您减少内存占用。 最后,您可以调整GC配置(-xx:minheapfreeratio,-xx:maxheapfreeratio,。。。)
内存度量有多种类型。 Docker似乎在报告RSS内存大小,这可能不同于jcmd报告的“提交”内存(旧版本的Docker报告RSS+缓存作为内存使用)。 很好的讨论和链接:在Docker容器中运行的JVM的驻留集大小(RSS)和Java总提交内存(NMT)之间的差异
(RSS)内存也可以被容器中的一些其他实用程序吞噬--shell,process manager,。。。我们不知道容器中还在运行什么,也不知道如何启动容器中的进程。

Java进程使用的虚拟内存远远超出了Java堆的范围。 JVM包含许多子系统:垃圾收集器,类加载,JIT编译器等,而所有这些子系统都需要一定数量的RAM来运行。
JVM不是RAM的唯一消费者。 本机库(包括标准Java类库)也可能分配本机内存。 而这对于本机内存跟踪甚至是不可见的。 Java应用程序本身也可以通过直接字节缓冲的方式使用堆外内存。
那么,在Java过程中,什么需要内存呢?
>
Java堆
最明显的部分。 这是Java物体居住的地方。 堆占用的内存最多为-xmx。
垃圾收集器
GC结构和算法需要额外的内存来进行堆管理。 这些结构是标记位图,标记堆栈(用于遍历对象图),记忆集(用于记录区域间引用)和其他。 其中一些是直接可调的,例如-xx:MarkStackSizemAX,其他则依赖于堆布局,例如越大的是G1区域(-xx:G1HeapRegionSize),越小的是记忆集。
GC内存开销因GC算法而异。 -xx:+UseSerialGC和-xx:+UseHenandoAHGC开销最小。 G1或CMS可以轻松地使用总堆大小的大约10%。
代码缓存
包含动态生成的代码:JIT编译的方法,解释器和运行时存根。 其大小受-xx:reservedCodeCacheSize限制(默认情况下为240M)。 关闭-xx:-tieredcompility以减少编译代码的数量,从而减少代码缓存的使用。
编译器
JIT编译器本身也需要内存来完成它的工作。 这可以通过关闭分层编译或减少编译器线程的数量来再次减少:-xx:CICompilerCount。
类加载
类元数据(方法字节码,符号,常量池,注释等)存储在称为元空间的堆外区域中。 加载的类越多--使用的元空间就越多。 可以通过-xx:maxMetaSpaceSize(默认情况下不受限制)和-xx:compressedClassSpaceSize(默认情况下为1G)来限制总使用量。
符号表
JVM的两个主要哈希表:Symbol表包含名称,签名,标识符等,String表包含对插入字符串的引用。 如果本机内存跟踪表明字符串表占用了大量内存,则可能意味着应用程序过度调用了String.intern。
螺纹
线程堆栈还负责占用RAM。 堆栈大小由-xss控制。 默认值是每个线程1M,但幸运的是事情并不是那么糟糕。 OS懒散地分配内存页,即在第一次使用时分配,因此实际的内存使用量会低得多(典型地每个线程堆栈80-200 KB)。 我写了一个脚本来估计有多少RSS属于Java线程堆栈。
还有其他分配本机内存的JVM部分,但它们通常不会在总内存消耗中扮演很大的角色。
应用程序可以通过调用ByteBuffer.AllocateDirection显式请求堆外内存。 缺省堆外限制等于-xmx,但可以用-xx:maxDirectMemorySize重写它。 直接字节缓冲区包含在NMT输出的other部分(或JDK 11之前的internal)中。
使用的直接内存数量通过JMX可见,例如在JConsole或Java任务控制中:
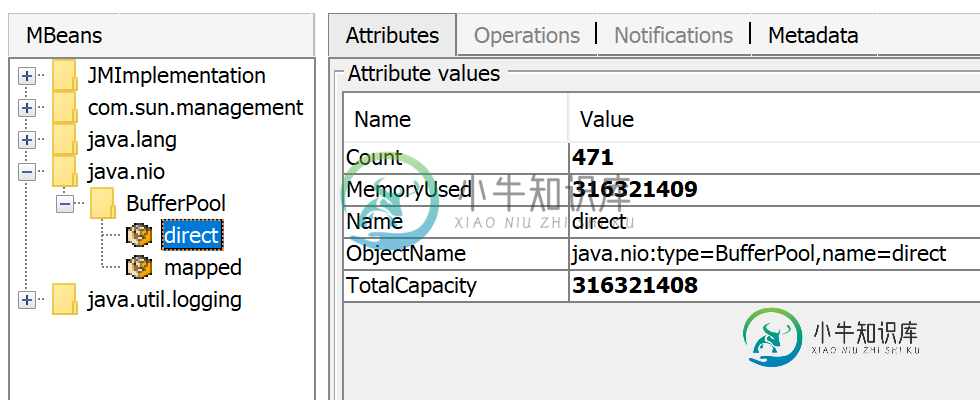
除了直接ByteBuffer之外,还可以有mappedByteBuffers-映射到进程虚拟内存的文件。 NMT不跟踪它们,但是,MappedByteBuffers也可以占用物理内存。 而且没有一个简单的方法来限制他们能承受多少。 您可以通过查看进程内存映射来查看实际使用情况:pmap-x
Address Kbytes RSS Dirty Mode Mapping
...
00007f2b3e557000 39592 32956 0 r--s- some-file-17405-Index.db
00007f2b40c01000 39600 33092 0 r--s- some-file-17404-Index.db
^^^^^ ^^^^^^^^^^^^^^^^^^^^^^^^
由System.LoadLibrary加载的JNI代码可以根据需要分配尽可能多的堆外内存,而无需JVM端的控制。 这也涉及到标准的Java类库。 尤其是未关闭的Java资源,可能成为本机内存泄漏的一个源头。 典型的例子是ZipInputStream或DirectoryStream。
JVMTI代理,特别是jdwp调试代理-也可能导致过度的内存消耗。
这个答案描述了如何使用Async-Profiler分析本机内存分配。
进程通常直接从OS(通过mmap系统调用)请求本机内存,或者使用malloc-标准libc分配器请求本机内存。 反过来,malloc使用mmap从OS请求大的内存块,然后根据自己的分配算法管理这些块。 问题是--这种算法会导致碎片和过多的虚拟内存使用。
另一种分配器jemalloc通常比常规的libcmalloc更聪明,因此切换到jemalloc可能会免费获得更小的内存占用。
没有保证的方法来估计一个Java进程的全部内存使用情况,因为需要考虑的因素太多了。
Total memory = Heap + Code Cache + Metaspace + Symbol tables +
Other JVM structures + Thread stacks +
Direct buffers + Mapped files +
Native Libraries + Malloc overhead + ...
可以通过JVM标志缩小或限制某些内存区域(如代码缓存),但其他许多区域则完全不受JVM控制。
设置Docker限制的一种可能方法是在进程的“正常”状态下观察实际内存使用情况。 有一些工具和技术可以用来调查Java内存消耗的问题:本机内存跟踪,pmap,jemalloc,async-profiler。
这里是我的一个Java过程的演示记忆足迹的记录。
在本视频中,我将讨论在Java进程中哪些可能消耗内存,如何监控和限制某些内存区域的大小,以及如何在Java应用程序中配置本机内存泄漏。
-
问题内容: 对于我的应用程序,Java进程使用的内存远远大于堆大小。 容器运行所在的系统开始出现内存问题,因为容器占用的内存比堆大小大得多。 堆大小设置为128 MB(-),而容器最多占用1GB的内存。正常情况下需要500MB。如果docker容器的限制低于(例如),则该进程将被操作系统的内存不足杀手杀死。 你能解释一下为什么Java进程使用的内存比堆多得多吗?如何正确调整Docker内存限制的大
-
上面链接中的代码正在工作,但可以传输到一定数量的数据。当我试图传输一个大小约为334 MB的.mkv格式的电影时,它给出了“内存不足,java堆大小”的错误。我是一个乞丐,我不知道如何解决这个问题,我试图在客户端程序中增加缓冲区大小,但问题仍然存在。请帮帮我.
-
问题内容: 我们正试图在我们的Web应用程序中找到导致大量内存泄漏的元凶。我们在发现内存泄漏方面经验有限,但是我们发现了如何使用Eclipse MAT进行Java堆转储并对其进行分析。 但是,对于我们使用56 / 60GB内存的应用程序,堆转储的大小仅为16GB,而在Eclipse MAT中则更少。 语境 我们的服务器将Ubuntu 14.04上的Wildfly 8.2.0用于我们的Java应用程
-
我们正试图找到web应用程序中大内存泄漏的罪魁祸首。我们在查找内存泄漏方面的经验相当有限,但我们了解了如何使用创建java堆转储,并在Eclipse mat中对其进行分析。 但是,由于我们的应用程序使用56/60GB内存,堆转储的大小只有16GB,在Eclipse mat中就更少了。 对于我们的java应用程序,我们的服务器使用Ubuntu14.04上的Wildfly8.2.0,其进程使用了95%
-
本文向大家介绍cgroup限制mongodb进程内存大小,包括了cgroup限制mongodb进程内存大小的使用技巧和注意事项,需要的朋友参考一下 以限制mongodb的内存大小为例。 通过cgroup限制后,当内存达到限额,进程会被kill。 数据查询脚本: 数据插入脚本:
-
我们将和设置为1536m。现在,如果我理解正确的话,j-xmx表示堆的最大大小。 本系统采用4核15GB ram进程。 但是,当我检查正在运行的Java进程的RSS(使用top)时,我看到它使用的值比大,大约。 对于来说,有4个内核和15GB RAM的理想设置是什么(假设除了Java应用程序之外,系统中没有其他进程在运行)
-
问题内容: 我想创建一个LinkedHashMap,它将根据可用内存(即,当低于某个阈值时)限制其大小。这将用作缓存的一种形式,可能使用“最近最少使用”作为缓存策略。 不过,我担心的是,allocatedMemory还包括(我认为)垃圾回收的数据,因此将高估已使用的内存量。我担心这可能会带来意想不到的后果。 例如,LinkedHashMap可能会继续删除项目,因为它认为没有足够的可用内存,但是可用
-
在堆上分配内存时,唯一的限制是可用RAM(或虚拟内存)。它产生Gb的内存。 那么,为什么堆栈大小如此有限(大约1 Mb)?什么技术原因阻止您在堆栈上创建真正大的对象? 更新:我的意图可能不清楚,我不想在堆栈上分配巨大的对象,也不需要更大的堆栈。这个问题只是纯粹的好奇心!